- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
ストリーム データをアーカイブします
HERE Workspace を使用すると、ストリームデータをアーカイブして、後で非リアルタイムの使用例についてそのデータをクエリーおよび処理できるようになります。 たとえば、バッチ処理を毎日実行して、特定の都市を囲む領域でその日に記録されたすべての路面状況検知イベントを検索する場合、インデックス レイヤーを使用して、イベント時間、イベントタイプ、および場所によって路面状況検知イベントのインデックスを作成できます。 データをアーカイブします。 バッチ処理の一部として、都市部でのプールイベントのデータを 24 時間ごとにクエリできます。
次の図は、ストリームデータをアーカイブしてクエリを実行する全体的なプロセスを示しています。
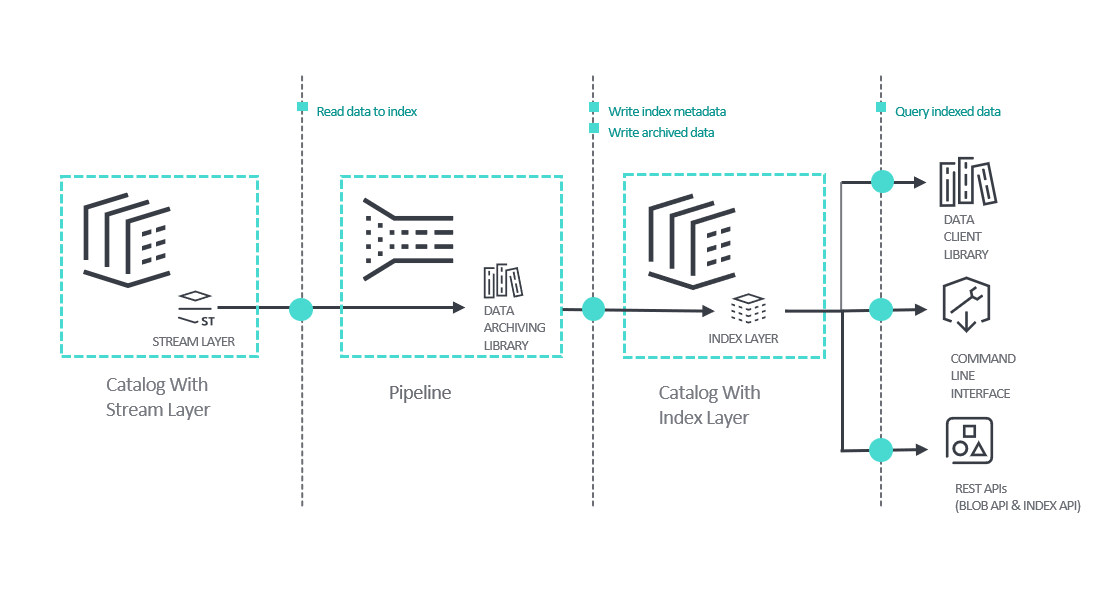
図の要点は次のとおりです。
-
ストリーム レイヤーからのデータは、プラットフォームパイプラインとして作成および実行するアプリケーションによってアーカイブされます。 アーカイブアプリケーションは 、 データアーカイブライブラリを使用します。この Java ライブラリは、ストリーム レイヤーからデータを読み取り、集計して、インデックス レイヤーにインデックスを作成します。 詳細については、以下を参照してください。
-
インデックス レイヤー には、アーカイブされたデータとインデックス属性が含まれています。 ストリーム レイヤー とは別のカタログ内のレイヤーです。
-
データがアーカイブされると、データのクエリー方法が複数あります。
- データ クライアント ライブラリ には、インデックスレイヤーからデータを読み取るための Java/Scala ライブラリが用意されています。
- コマンド ライン インターフェースを使用すると、コマンド ラインまたはスクリプトからインデックス レイヤーからデータを読み取ることができます。
- REST API インデックス と Blob を併用すると、インデックス化されたデータのクエリと読み取りを行うことができます。 Index API は、クエリに一致するデータのデータハンドルを返します。 たとえば、特定の時間枠および場所からイベントを検索する場合、応答にはそれらのイベントのデータハンドルが含まれます。 クエリ条件に一致するデータハンドルがある場合は、それらのハンドルを使用して Blob API を使用して対応するデータを取得できます。
インデックス レイヤー インターフェイスの比較
インデックス レイヤーとの対話には複数の方法があります。
- データアーカイブライブラリ: Data Archiving ライブラリを使用して、パイプラインで実行できるカスタムアプリケーションを Java で開発します。 ストリーム レイヤーメッセージをインデックス レイヤーに保存するには、 Data Archiving ライブラリを使用することをお勧めします。 Data Archiving ライブラリでは、アプリケーションにライブラリのユーザー定義関数を実装するだけで、各メッセージのインデックス属性を抽出できます。 アプリケーションを作成したら、パッケージ化してパイプラインでアプリケーションを実行できます。 Data Archiving ライブラリは、インデックス レイヤーへの書き込み専用です。 データのクエリには使用できません。
- データ クライアント ライブラリ: データ クライアント ライブラリには、インデックス レイヤーとの対話に使用できる Java および Scala API が用意されています。 データアーカイブライブラリが要件を満たしておらず、カスタムアプリケーションを開発する場合は、インデックス レイヤーを使用してデータ クライアント ライブラリを操作することをお勧めします。
- REST API : データ クライアント ライブラリでサポートされていない言語でアプリケーションを作成する場合は、 REST API を使用します。 REST API を使用してインデックス レイヤーと対話できます。
- コマンド ライン インターフェース: コマンド ライン インターフェース( CLI )を使用して、コマンド ラインまたはスクリプトからインデックス レイヤーを操作します。
アーカイブソリューションを作成しています
ストリーム レイヤーのアーカイブソリューションを作成するには、次の手順を実行します。
ステップ 1 : ストリーム レイヤー を作成します
データをアーカイブするストリーム レイヤー がまだない場合は、ストリーム レイヤー を作成します。 詳細については、「レイヤーを作成する」を参照してください。
ステップ 2 : インデックス レイヤー を作成します
アーカイブするストリーム レイヤー が含まれているカタログとは別のカタログで、インデックス レイヤー を作成します。 詳細については、「レイヤーを作成する」を参照してください。
ステップ 3 : アーカイブアプリケーションを作成します
アーカイブプロセスは、パイプラインで作成して実行するアプリケーションによって実行されます。 アプリケーションを作成する最も簡単な方法は、 HERE Data SDK に含まれているサンプルアプリケーションのいずれかから開始することです。 これらの例では、 Data Archiving ライブラリを使用してデータを保存する方法を示します。
アーカイブアプリケーションを作成するには、次の手順に従います。
- Data Archiving ライブラリで提供されるユーザー定義の機能を実装します。
application.confファイルを設定します。- アプリケーションを Fat JAR ファイル にパッケージ化します。
詳細については、サンプルに含まれている README ファイルを参照してください。
ステップ 4 : 権限を設定します
アーカイブパイプラインは、ストリーム レイヤーが含まれているカタログへの readアクセス権、およびインデックス レイヤー が含まれているカタログへの readwrite アクセス権を持っている必要があります。 このアクセス権を、アーカイブパイプライン を作成するグループ ID に付与します。 アクセス権を付与する方法の詳細については、「カタログを共有する」を参照してください。
ステップ 5 : パイプライン を使用してアプリケーションを展開します
アプリケーションを実行するには、 HERE Workspace でパイプライン を作成する必要があります。 詳細については、以下を参照してください。
ステップ 6 : パイプライン が実行されていることを確認します
HERE platform ポータルで、パイプライン タブを選択し、パイプライン を探します。 実行状態になっている必要があります。
インデックス付きデータをクエリしています
アーカイブパイプラインが実行され、データがインデックス レイヤーにアーカイブされたら、次のいずれかの方法でデータのクエリおよび取得を行うことができます。
注
インデックス レイヤーに問い合わせているアプリ read がインデックス レイヤーに対する権限を持っていることを確認してください。 詳細については、以下を参照してください。
インデックス レイヤーから取得したデータの解析については、次のトピックを参照してください。