- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
アダプティブレベリング
道路網、 POI 、建物、住宅など、地理的に分散したコンテンツは、自然には世界中に均等に分散されていません。 都市では地理データの集中度が高くなる傾向があり、農村地域では地理データが希薄になり、海や海は空になることが一般的です。
このような不均衡が予想されるのは、コンテンツがこのように実際には時間の経過とともに相対的に一定で配布されるためです。 ただし、このようなバランスの取れていないと、データの処理やデータの使用に問題が発生します。
タイル内で地理的に分割されたデータセットの主な問題は、一部のタイルには内容が多すぎる傾向があり、他のタイルはほとんど空になっている傾向があることです。 タイリンググリッドのレベルにかかわらず、タイル数が多すぎるか、タイルの大部分がサイズが小さいか、またはタイル数が少なすぎます。タイル数の一部が大きすぎます。
小さなタイルが多すぎると、処理または消費されたデータ量に比べて、データの処理および消費のオーバーヘッドが高くなります。
タイルの数が少なくて大きいほど、リソース消費のピークにつながります。その結果、コンテンツ量が多すぎるタイルを処理する場合にはパイプラインがメモリ不足になり、インタラクティブなアプリケーションでそのようなタイルを使用する場合には許容できない遅延が発生します。
タイルのレベリングが固定されている場合、「 1 つのサイズですべてに対応」のソリューションはありません。
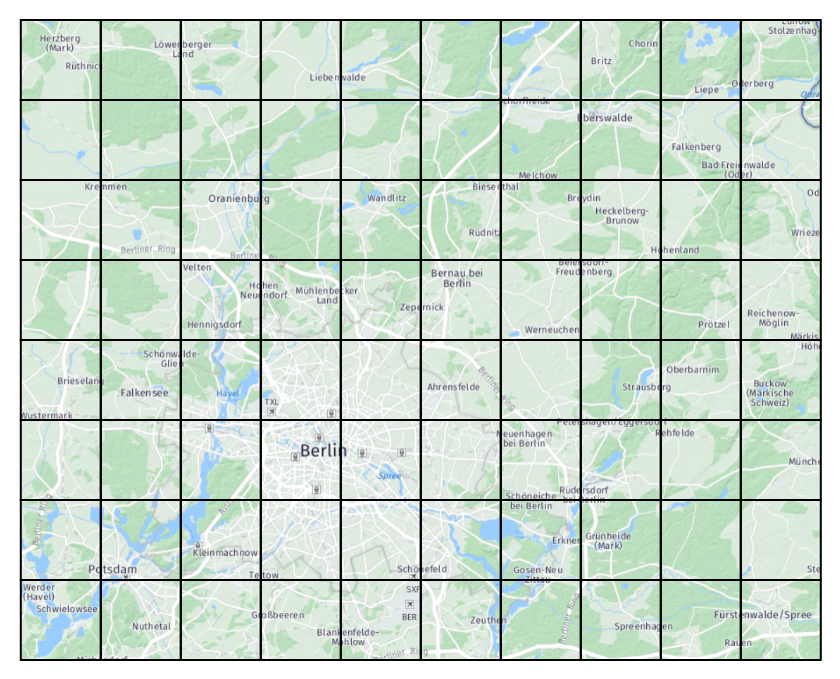
アダプティブレベリングは、タイルサイズを 1 つだけ選択するという制限を克服するソリューションです。 一 AdaptivePattern部のコンテンツの地理的密度を記述するの概念に基づいています。 コンテンツがスパースの領域では、低いタイルレベルが使用されます。 コンテンツの密度が高い領域では、より高いタイルレベルが使用されます。 AdaptivePatternは、ライブラリで提供されているAdaptivePatternEstimatorアルゴリズムによって推定されます。
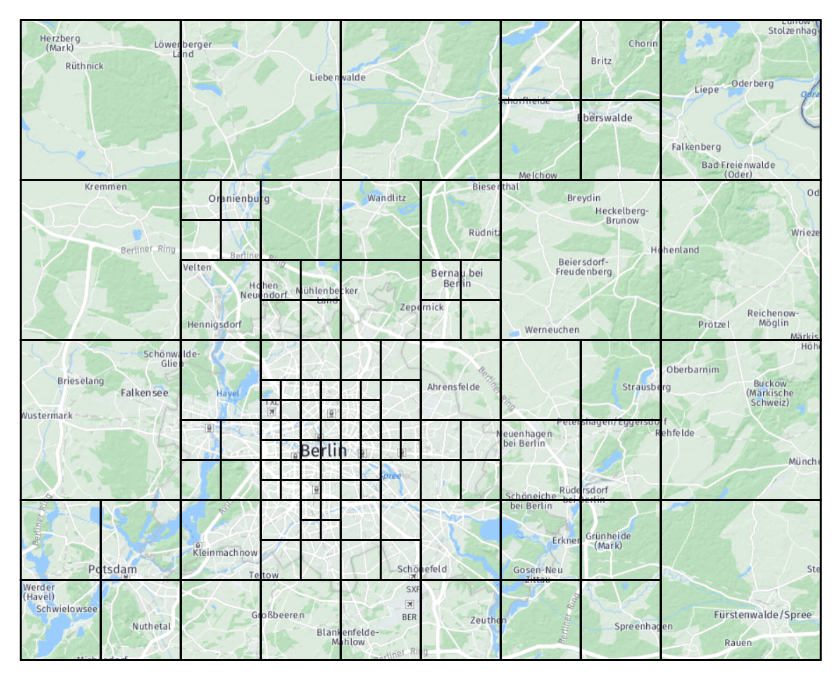
比較の FixedPattern ために、は、固定レベルでタイルを配布するロジックを表すためにも存在します。 両方のクラスが共通の親を共有 Patternするので、 1 つのパターンから別のパターンに簡単に切り替えることができます。
アダプティブパターンの推定
このクラス AdaptivePatternEstimator は、適応パターンを計算します。
このアルゴリズムは、メイン処理を行う前に実行する必要があります。このアルゴリズムは、結果のパターンが後続の処理ステップで使用されるためです。 このロジックを接続する場合、以下 の例に示すように、DriverBuilderを使用してDriverを設定することをお勧めします。 Java バージョンは 、この章で説明する他のクラスと同様に、 Java バインディングの一部として存在します。
概算見積書で AdaptivePatternEstimateFn は、インターフェイスの実装を指定する必要があります。 機能 的なコンパイル・パターンと同様に、パターンの見積もりに反映する入力レイヤーを指定する必要があります。 は AdaptivePatternEstimator 、入力カタログを照会し、 estimateFn 指定されたレイヤーの各入力パーティションについてを呼び出して、 AdaptivePattern 結果をインスタンスに集約するために、この情報を必要とします。 DriverTaskがインクリメンタルに実行されるかどうかにかかわら AdaptivePattern ず、この方法で統合すると、パターンの見積もりがコンパイルごとに実行されます。
重量
推定アルゴリズムで estimateFn は、関連する各入力パーティションについてが評価されます。 これらは両方のタイプのパーティション(通常は HERE Tile )にすることができますが、汎用パーティションを概算入力として使用することもできます。 また estimateFn 、この機能にはメタデータも提供されています。
で estimateFn は、 HERE Tile ID と重みのコレクションを返して、データの密度を記述します。 地理的な場所の密度または重さを概算値に指定します。 estimateFn 同じ HERE Tile ID を返す複数のコールがある場合、それらの重みが合計されます。 概算見積書機能によって作成されたタイル ID には、任意のレベルを指定できます。
重みの意味は固定されていません。 任意の値を重みに保存できます。ただし、値が 0 より大きい場合に限ります。 メタデータから取得した入力データのサイズを保存できますが、以下の例に示すように、より複雑なスキームを使用することもできます。 を使用して入力ペイロードを取得 Retrieverし、コンテンツを検査して、そのコンテンツを使用してウェイトを定義することもできます。 たとえば、ルーティンググラフノードの数、 POI または道路の数を返します。 ただし、このパターンはお勧めしません。評価プロセスはすべてのジョブで最初から実行されるため、つまり入力内容全体を実行ごとに取得する必要があるからです。 したがって、パターンの見積もりに小さなレイヤーがない限り、この方法は適していません。 多くの場合、メタデータのサイズを使用するだけで十分な結果が得られます。 それでも、ペイロードを取得する概算関数を使用できます。
次の実装例 : AdaptivePatternEstimateFn
class MyEstimateFn extends AdaptivePatternEstimateFn {
override def inLayers: Map[Catalog.Id, Set[Layer.Id]] = {
// These are the catalog and layers that contribute to the estimation
Map(
Ids.RoadCatalog -> Set(Ids.RoadJunctions, Ids.RoadGeometries),
Ids.ExtraCatalog -> Set(Ids.ExtraContent)
)
}
override def inPartitioner(parallelism: Int): Option[Partitioner[InKey]] = {
// There is in general no need to dictate which Spark partitioner the
// AdaptivePatternEstimator has to use for its internal operations,
// so we return None here, but this possibility is not prevented.
None
}
override def estimateFn(src: (InKey, InMeta)): Iterable[(HereTile, Long)] = {
// The assumption made in this example is the average density of data
// is function of what is present in 3 layers of 2 input catalogs
// and somehow proportional to the sizes of the payloads of that layers.
// The road catalog, that contains road junctions and geometries,
// and an extra catalog, that contains additional tiled content.
// The weight of the road junction is 5 times the one of the geometry,
// while the weight of the extra content is twice the one of the geometry.
// The storage level of the 3 input layers is assumed to be the same.
src match {
case (InKey(Ids.RoadCatalog, Ids.RoadJunctions, tile: HereTile),
InMeta(_, _, _, Some(size))) =>
List(tile -> size * 5)
case (InKey(Ids.RoadCatalog, Ids.RoadGeometries, tile: HereTile),
InMeta(_, _, _, Some(size))) =>
List(tile -> size)
case (InKey(Ids.ExtraCatalog, Ids.ExtraContent, tile: HereTile),
InMeta(_, _, _, Some(size))) =>
List(tile -> size * 2)
}
}
}
しきい値
重みは AdaptivePattern 、に提供する必要がある所定のしきい値に集約 AdaptivePatternEstimatorされます。 しきい値のセマンティックは、重みに与えることにしたセマンティックに従います。これらのセマンティックは同等である必要があります。
重みは、集約タイルの合計重みが指定したしきい値を超えてはならないように集約されます。 この総重量は、タイル自体の推定重量として定義されます。この重量には、その子および孫の重量も含まれます。
計算されたは、可能な限り AdaptivePattern 、各タイルをその集約ターゲットにマッピングします。集約ターゲットは、しきい値を超えない最下位レベルの親です。 タイルの重量がしきい値を超えると、それらのタイルは集約できず、マップされません。 これは、予期しないタイル(パターンが最初に推定されたときに提供されなかったタイル)にも適用されます。 このような場合、パターンマッピング関数はを返し Noneます。
たとえば、によって作成された次のタイルおよび重量を指定 estimateFnします。
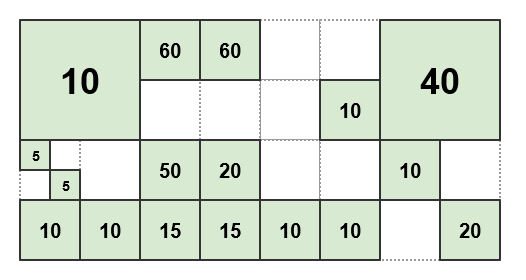
しきい値がに設定されている場合 50、結果のパターンは次のようになります。
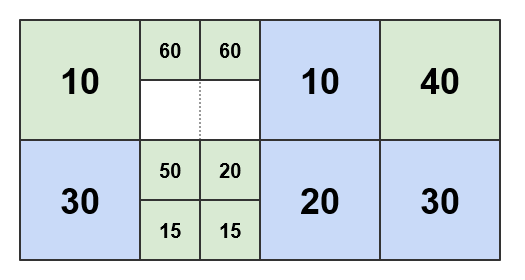
に AdaptivePattern は、完全性と明確性を考慮して、図に示されているように、重量のない青色のタイルのみが含まれています。また、一部の見積もり入力も含まれています。 タイルがパターンを介してマップされている場合、マップするタイルがその子または孫のいずれかである場合は、 4 つの青いタイルのいずれかが返されます。それ以外の場合は、マップされないままになります。
しきい値がに設定されている場合 100、結果のパターンは次のようになります。
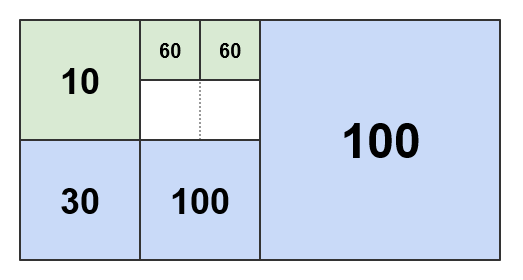
しきい値が大きいほど、下位レベルの集約タイルが決まります。 IT のウェイトバジェットが多いため、集約はより積極的に行われる傾向 があります。
しきい値 200 およびを 300 使用してそれぞれ計算されたパターンを次に示します。
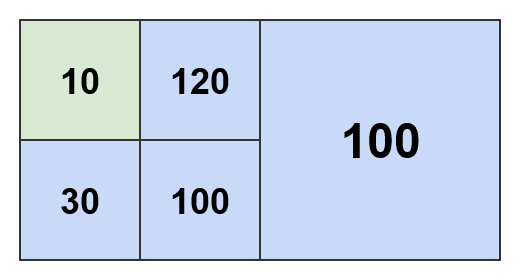
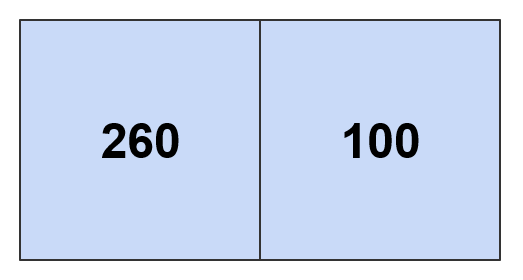
しきい値 360 以上を使用すると、推定密度マップ全体が AdaptivePattern 、ワールドルートタイルのみを含むに折りたたまれます。
コンテンツ密度に基づいた Spark パーティション
AdaptivePattern データの密度に基づいて Spark パーティションを定義することを可能にするキーユースケース。 重みとしきい値を指定し、パターンを使用して Spark を実装 Partitioner すると、動的なパーティション数が発生し、各パーティションはしきい値を超えない方法で定義されます。
は AdaptivePattern 、 Spark パーティションのサイズのバランスをとるために使用され、内部のコンテンツのより均一で統一された配布を取得します。 パーティションの処理が重すぎたり、ライトパーティションが多すぎたりする事態を避けるには、バランスを保つ必要があります。 その結果、処理がスムーズになり、クラスタリソースの使用率が向上します。これらの処理はすべて出力に影響を与えることなく行われます。
AdaptivePattern Spark パーティションごとのメモリ消費量が適切に割り当てられるため、大規模なジョブに割り当てられているリソースを調整する場合に優れたヘルパーとなります。これは、 ごとのメモリ消費量が多いために処理がメモリ不足になることを防ぐためです。
AdaptiveLevelingPartitioner このロジックを実装する Spark パーティション作成者です。 次 Driver の例に示すようにを設定することで、この機能を使用できます。
def configureCompiler(completeConfig: CompleteConfig,
context: DriverContext,
builder: DriverBuilder): builder.type = {
// We define our own estimate function and run it as preliminary step
// to calculate an adaptive pattern and use it to obtain a partitioner.
// The threshold is in the same units returned by the estimate function,
// that are related to the size in bytes, so we ask the estimator
// to define a pattern and have Spark partitions of a max size of 100 MB.
val myEstimateFn = new MyEstimateFn
val estimator = new AdaptivePatternEstimator(myEstimateFn, context)
// we use a NameHashPartitioner for partitions that are not aggregated
val fallbackPartitioner = NameHashPartitioner(context.spark.defaultParallelism)
val partitioner = estimator.partitioner(100 * 1024 * 1024, Some(fallbackPartitioner))
// The partitioner is passed to the compiler, that uses it to implement
// the inPartitioner and outPartitioner methods, ignoring the static parallelism
val myCompiler = new MyCompilerWithPartitioner(partitioner)
// Add the compiler to the Driver as new DriverTask
builder.addTask(builder.newTaskBuilder("compiler").withMapGroupCompiler(myCompiler).build())
}
パターンは、を設定するときに計算 Driver され、サンプルのコンパイラーに渡されます。
class MyCompilerWithPartitioner(partitioner: AdaptiveLevelingPartitioner)
extends MapGroupCompiler[Intermediate]
with CompileOut1To1Fn[Intermediate]
コンパイラーは、このメソッドを使用して、パーティャーを定義するメソッドを実装します。
def inPartitioner(parallelism: Int): Option[Partitioner[InKey]] = {
// parallelism is provided for convenience. In this case the partitioner
// has been already initialized: in an adaptive partitioner, the number
// of partitions is function of the weights and the threshold plus the
// parallelism of the fallback partitioner (if specified).
Some(partitioner)
}
def outPartitioner(parallelism: Int): Option[Partitioner[OutKey]] = {
// The output partitioner doesn't have to be the same
// as the input partitioner, but in this example it is.
Some(partitioner)
}
パターンは実行ごとに再計算されます。 AdaptivePattern パターンの推定に使用されたデータの変更によってに最終的に変更 が加えられても、インクリメンタルコンパイルは妨げられません。 これは、 Spark のパーティングが影響を与えるのは Spark のランタイムのパフォーマンスだけで、実際の出力カタログには影響しないためです。 したがって、現在の実行のインクリメンタル・コンパイルを無効にする必要はありません。
コンテンツの密度に基づいた出力レイヤーのレベル
AdaptivePattern データの密度に基づいて、可変レベルのレイヤーを出力するスマートなコンパイラーを有効にするもう 1 つの重要なユースケースがあります。
このように作成されたレイヤーは、コンテンツが密集している領域で、コンテンツが希薄で小さなタイルである地理的領域で、下位レベルの大きいタイルによって特徴付けられます。
このソリューションには、次の利点があります。
- 出力タイルのサイズはより均一で、平均サイズに近い大きさに分布します
- 大きすぎるタイルや小さすぎるタイルが少ないなどの極端な条件は避けてください
- ダウンロード時間は、特にインタラクティブなアプリケーションでは、より均一で予測可能です
この機能をイネーブルにするには、次の例に示すように、AdaptivePatternを推定して使用できるようにDriverを設定します。
def configureCompiler(completeConfig: CompleteConfig,
context: DriverContext,
builder: DriverBuilder): builder.type = {
// We define our own estimate function and run it as preliminary step
// to calculate an adaptive pattern and use it to model the output layer.
// The threshold is in the same units returned by the estimate function,
// that are related to the size in bytes, so we ask the estimator
// to define a pattern and have Spark partitions of a max size of 100 MB.
val myEstimateFn = new MyEstimateFn
val estimator = new AdaptivePatternEstimator(myEstimateFn, context)
val pattern = estimator.adaptivePattern(100 * 1024 * 1024)
// The pattern is passed to the compiler that uses it to implement
// its compileIn function. Other examples may use it differently.
// Note the pattern is in a broadcast variable registered in fingerprints.
val myCompiler = new MyCompilerWithPattern(pattern)
// Add the compiler to the Driver as new DriverTask
builder.addTask(builder.newTaskBuilder("compiler").withMapGroupCompiler(myCompiler).build())
}
AdaptivePatternEstimatorは、AdaptivePatternを含むBroadcast変数を返します。 このオブジェクトは、サンプルのコンパイラーに渡されます。 パフォーマンスを向上させ、リソース消費を改善する Broadcast には、変数をコンストラクタに変更せずに渡す必要があります。
class MyCompilerWithPattern(pattern: Broadcast[AdaptivePattern])
extends MapGroupCompiler[Intermediate]
with CompileOut1To1Fn[Intermediate]
この例では、コンパイラーが入力レイヤーと出力レイヤーを通常どおり定義します。
def inLayers: Map[Catalog.Id, Set[Layer.Id]] = Map(
Ids.RoadCatalog -> Set(Ids.RoadJunctions, Ids.RoadGeometries)
)
def outLayers: Set[Layer.Id] = Set(Ids.OutRendering, Ids.OutRouting)
で AdaptivePattern は、 compileInFn 入力タイルを可変レベルの出力タイルにマップするために使用されます。 .value 内部のパターンにアクセスする方法 Broadcastについては、を参照してください。
def compileInFn(in: (InKey, InMeta)): Iterable[(OutKey, Intermediate)] = {
// In this example we assume input tiles from the road catalog
// are to be mapped to variable-level output layers
// using the pattern passed in the constructor.
// Objects from the geometries layer must be decoded in roads
// and provided to both rendering and routing output layers.
// Objects from the junction layer must be decoded and
// provided to only the output routing layer (just an example).
in match {
case (InKey(Ids.RoadCatalog, Ids.RoadGeometries, tile: HereTile), meta) =>
// The leveling target should be defined for every input
val outTile = pattern.value.levelingTargetFor(tile).get
val payload: Payload = ??? /* retrieve and decode the payload */
val roads
: Set[Road] = ??? /* prepare the roads for the output routing and rendering layers */
val intermediate = Intermediate(roads, Set.empty)
List(
// outTile is used for both, but it is not a hard requirement
(OutKey(Default.OutCatalogId, Ids.OutRouting, outTile), intermediate),
(OutKey(Default.OutCatalogId, Ids.OutRendering, outTile), intermediate)
)
case (InKey(Ids.RoadCatalog, Ids.RoadJunctions, tile: HereTile), meta) =>
// The leveling target should be defined for every input
val outTile = pattern.value.levelingTargetFor(tile).get
val payload: Payload = ??? /* retrieve and decode the payload */
val junctions: Set[Junction] = ??? /* prepare the junctions for the output routing layer */
val intermediate = Intermediate(Set.empty, junctions)
List(
(OutKey(Default.OutCatalogId, Ids.OutRouting, outTile), intermediate)
)
case _ =>
sys.error("Unexpected input key")
}
}
は compileOutFn 、によって設定さ compileInFnれたキーおよび中間データを処理するので、アダプティブレベリングを認識する必要はありません。
def compileOutFn(outKey: OutKey, intermediate: Iterable[Intermediate]): Option[Payload] =
outKey match {
case OutKey(Default.OutCatalogId, Ids.OutRendering, _) =>
val roads: Set[Road] = intermediate.flatMap(_.roads)(collection.breakOut)
val payload: Payload = ??? /* process the roads and encode the result */
Some(payload)
case OutKey(Default.OutCatalogId, Ids.OutRouting, _) =>
val junctions: Set[Junction] = intermediate.flatMap(_.junctions)(collection.breakOut)
val payload: Payload = ??? /* process the junctions and encode the result */
Some(payload)
case _ =>
sys.error("Unexpected output key")
}
パターンは実行ごとに再計算されます。 ただし、この 2 番目のユースケースで は、AdaptivePatternパターンの推定に使用されたデータの変更によってに最終的に変更が加えられた場合 、インクリメンタル・コンパイルは防止されます。 これは、パターンが出力カタログをアクティブに定義するためです。 出力の破損を防ぐ Broadcast ために、パターンはコンパイラーの実装で使用される変数内に返されます。 Broadcast この種類の変数を変更すると、現在の実行のインクリメンタルコンパイルが禁止されます。
この制限は、平均重量分布および結果のパターンに影響がないように、パターンの変更の推定に使用されるデータが変更された場合には適用されません。