- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
CLI およびデータ クライアント ライブラリを使用したローカルでの開発およびテスト
目的: ローカルカタログを使用して処理アプリケーションを実装およびテストする方法を理解します。
複雑さ: 中級者です
所要時間: 45 分
前提条件: Spark Connector を使用してデータの読み取りと書き込み を行います ( サンプル処理アプリケーションのロジック用 )
ソースコード: ダウンロード
この例では、次の操作を実行する方法を示します。
- CLI を使用してローカル出力カタログを作成し、開発中に処理パイプラインを実行します
- CLI を使用して、入力プラットフォームがホストするカタログのローカルコピーを作成し、完全にオフラインの開発環境を作成します
- データ クライアント ライブラリ、ローカルカタログ、およびお気に入りのテストフレームワークを使用して、処理中のパイプラインをテストします。
ローカルカタログについて
ローカルカタログは、ファイルにエンコードされ ~/.here/local/ 、ディレクトリに保存される特殊なカタログです。 CLI およびデータ クライアント ライブラリは、ローカルカタログの読み取りおよび書き込みを行う Data API のローカルバージョンを生成できます。 すべてのローカルカタログファイルにはファイル名が含ま <catalog-id>.dbれており、エンジニアリングチーム内またはエンジニアリングチーム間でローカルカタログを共有するために、名前の変更(カタログ ID の変更)、コピー、他のマシンへの移動を行うことができます。 カタログは ~/.here/local/ ディレクトリに追加でき、 CLI およびデータ クライアント ライブラリでただちに使用できます。
ローカルカタログは、特殊な HERE リソースネーム によって識別 hrn:local:data:::<catalog-id>されます。
ローカルカタログを使用するために、認証および外部ネットワークへのアクセスは必要ありません。そのため、ローカルカタログへのアクセスに追加のコストは発生しません。 ローカルマシンに含まれているため、レルム内での命名の競合の影響を受けません。
さらに、ローカルカタログをディスクに永続化するのではなく、オプションで作成してメモリに保存することもできます。これにより、開発および自動テスト中に特に役立ちます。
注
ローカルカタログは、開発およびテストの目的でのみ使用できます。 ローカルカタログを使用してプロダクションユースケースを実行することは許可されていません。
サンプル処理アプリケーション
ローカルカタログは、スタンドアロンから Spark または Flink ベースのアプリケーション、バージョン管理レイヤー、ストリームレイヤー、インデックスレイヤー、揮発性レイヤーなど、幅広いアプリケーションの開発時に使用できます。
このチュートリアルでは、データクライアントライブラリの Spark コネクタを使用しますが、このアプリケーションをローカルカタログで実行およびテストする手順は、他のすべてのシナリオで使用できます。
まず、 HERE Map Content の各トポロジパーティションについて、各レベル 14 のサブタイルのトポロジノード数をカウントし、この情報をレベル 12 の GeoJSON タイルにエンコードして結果を出力バージョン付レイヤーに保存するアプリケーションを開発します。
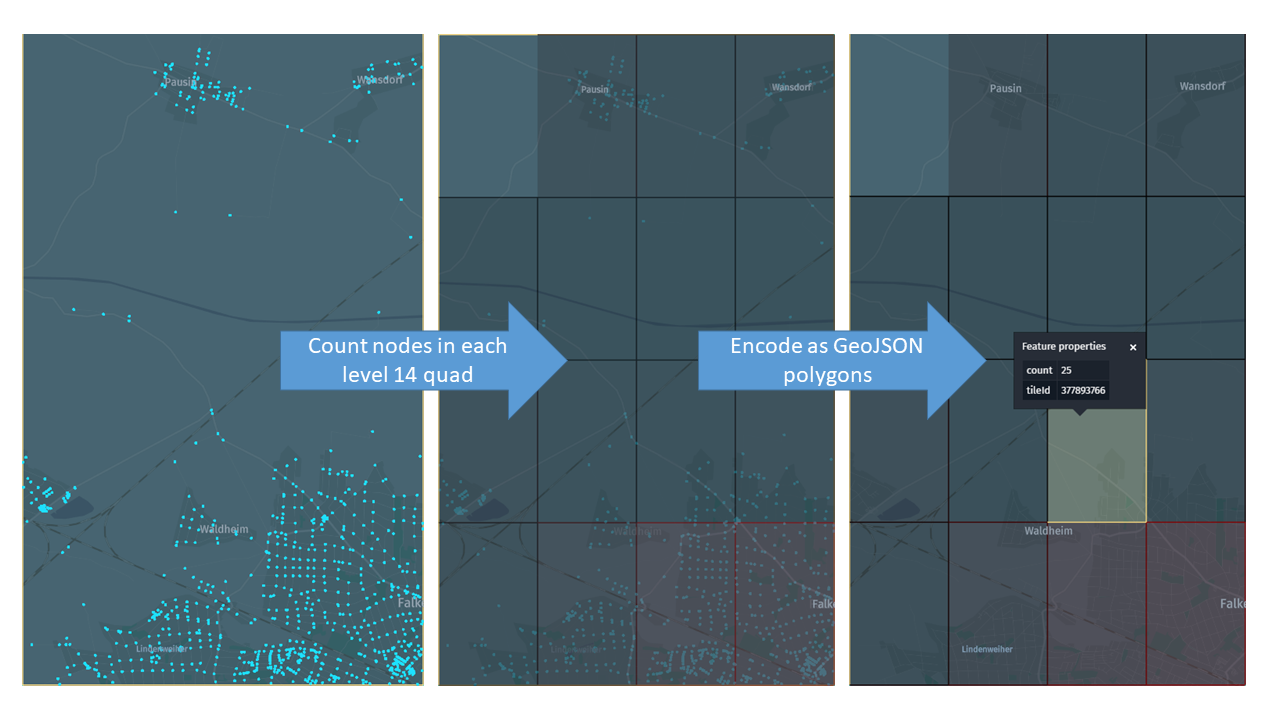
節点の数に基づいて異なる赤のシェードを使用して、サブタイルの交差の密度を表す「ヒートマップ」を作成します。

Maven プロジェクトを設定します
プロジェクトの次のフォルダー構造を作成します。
local-development-workflow
└── src
├── main
| ├── java
| ├── scala
| └── resources
└── test
├── java
├── scala
└── resources
この操作は、次の bash 1 つのコマンドで実行できます。
mkdir -p local-development-workflow/src/{main,test}/{java,scala,resources}
Maven POM ファイルは 、 Maven 設定の確認 の例で親 POM と依存関係のセクションが更新されたのと似ています。
親 POM :
<parent>
<groupId>com.here.platform</groupId>
<artifactId>sdk-batch-bom_2.12</artifactId>
<version>2.54.3</version>
<relativePath/>
</parent>
依存関係 :
<dependencies>
<dependency>
<groupId>com.here.platform.pipeline</groupId>
<artifactId>pipeline-interface_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.platform.data.client</groupId>
<artifactId>spark-support_${scala.compat.version}</artifactId>
</dependency>
<!-- To enable support of local catalogs -->
<dependency>
<groupId>com.here.platform.data.client</groupId>
<artifactId>local-support_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.hrn</groupId>
<artifactId>hrn_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</dependency>
<dependency>
<groupId>com.here.schema.rib</groupId>
<artifactId>topology-geometry_v2_scala_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.schema.rib</groupId>
<artifactId>topology-geometry_v2_java</artifactId>
</dependency>
<dependency>
<groupId>com.thesamet.scalapb</groupId>
<artifactId>sparksql-scalapb_${scala.compat.version}</artifactId>
<version>0.10.4</version>
</dependency>
<!-- To test the Scala version of the application -->
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_${scala.compat.version}</artifactId>
<version>3.0.1</version>
<scope>test</scope>
</dependency>
<!-- To test the Java version of the application -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
ローカル出力カタログを作成します
まず、パイプラインを開発し、 HERE Map Content から読み取り、ローカルカタログへの書き込みを行います。 さらに、 HERE Map Content カタログのローカルコピーを作成して、完全にオフラインの開発環境を作成します。
CLI を使用してローカルカタログを作成する方法は、プラットフォームでカタログを作成する方法と非常に似ています。 次のカタログ設定を使用しています :
{
"id": "node-count",
"name": "Aggregated node count at level 14 (From tutorial)",
"summary": "Here Map Content node count per level 14 tile.",
"description": "Here Map Content node count per level 14 tile.",
"tags": ["Tutorial"],
"layers": [
{
"id": "node-count",
"name": "node-count",
"summary": "Node count.",
"description": "Node count.",
"contentType": "application/vnd.geo+json",
"layerType": "versioned",
"volume": {
"volumeType": "durable"
},
"partitioning": {
"scheme": "heretile",
"tileLevels": [12]
}
}
]
}
カタログには、レベル 12 の GeoJSON レイヤーが含まれています(入力カタログと同じ)。 次のコマンドを実行して、カタログを作成します。
olp local catalog create node-count "Node Count" \
--config local-development-workflow-output-catalog.json
注
レルムで請求タグが必要な場合 は、layerセクションにbillingTags: ["YOUR_BILLING_TAG"]プロパティを追加して設定 ファイルを更新します。
CLI は次のように戻ります。
Catalog hrn:local:data:::node-count has been created.
つまり、ローカルカタログへのアクセス権が付与さ hrn:local:data:::node-countれ、 CLI カタログコマンドのローカルバリアントを使用して再生できます。
olp local catalog list
olp local catalog show hrn:local:data:::node-count
olp local catalog layer show hrn:local:data:::node-count node-count
ローカルカタログで使用できる CLI コマンドの詳細について は、 OLP CLI のドキュメントを参照してください。
カタログデータは ~/.here/local/node-count.db ファイルに保存され、次の条件で確認できます。
ls ~/.here/local/
pipeline-config.conf 入力カタログ( HERE Map Content )を含むファイルを作成できるようになりました。新しく作成したローカルカタログは出力カタログです。
pipeline.config {
// Make sure the local catalog has been created first:
// olp local catalog create node-count "Node Count" --config local-development-workflow-output-catalog.json
output-catalog { hrn = "hrn:local:data:::node-count" }
input-catalogs {
here-map-content { hrn = "hrn:here:data::olp-here:rib-2" }
}
}
アプリケーションを実装します
サンプルアプリケーションは application.conf 、設定ファイルで指定されたバウンディング ボックス内のすべての入力パーティションを読み取り、処理します。
tutorial {
boundingBox {
// Berlin
north = 52.67551
south = 52.33826
east = 13.76116
west = 13.08835
}
}
ロジックを実装するに は、データ クライアント ライブラリ Spark コネクターおよび一般的な Spark 変換を使用します。 チュートリアルを続行するために、処理ロジックを完全に理解する必要はありません。 この演習を終了すると、このコードがブラックボックスとしてテストされます。
Scala
Java
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import com.here.olp.util.geo.BoundingBox
import com.here.olp.util.quad.factory.HereQuadFactory
import com.here.platform.data.client.spark.LayerDataFrameReader.SparkSessionExt
import com.here.platform.data.client.spark.LayerDataFrameWriter.DataFrameExt
import com.here.platform.data.client.spark.scaladsl.{
GroupedData,
VersionedDataConverter,
VersionedRowMetadata
}
import com.here.platform.pipeline.PipelineContext
import com.here.schema.rib.v2.topology_geometry_partition.TopologyGeometryPartition
import com.typesafe.config.ConfigBeanFactory
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import scalapb.spark.Implicits._
object SparkConnectorLocalScala {
// We expose two public methods, `main` and `run`. `main` reads the pipeline context and the
// configuration from `pipeline-config.conf` and `application.conf`, while `run` accepts them
// as parameters. This makes it convenient to test the logic later using `run` with different
// configuration parameters, without having to pass them through the classpath.
def main(args: Array[String]): Unit = {
// Read the default pipeline context
val pipelineContext = new PipelineContext
// Read the bounding box configured in `application.conf`
val bbox = ConfigBeanFactory.create(
pipelineContext.applicationConfig.getConfig("tutorial.boundingBox"),
classOf[BoundingBox]
)
run(pipelineContext, bbox)
}
def run(pipelineContext: PipelineContext, bbox: BoundingBox): Unit = {
// Defines the input / output catalogs to be read / written to
val inputHrn = pipelineContext.config.inputCatalogs("here-map-content")
val outputHrn = pipelineContext.config.outputCatalog
// Input / output layers
val topologyGeometryLayer = "topology-geometry"
val outputLayer = "node-count"
val sparkSession: SparkSession =
SparkSession.builder().appName("SparkTopologyNodeCount").getOrCreate()
// Read the input data as a Dataset of topology partitions
val topologyGeometryData: Dataset[TopologyGeometryPartition] = sparkSession
.readLayer(inputHrn, topologyGeometryLayer)
.query(
s"mt_partition=inboundingbox=(${bbox.getNorth},${bbox.getSouth},${bbox.getEast},${bbox.getWest})"
)
.option("olp.connector.force-raw-data", value = true)
.load()
.select("data")
.as[Array[Byte]]
.map(TopologyGeometryPartition.parseFrom)
// This is needed for implicit conversions - moved down to avoid conflicts with scalapb.spark.Implicits._
import sparkSession.implicits._
// Compute the output partitions
val nodeCountPartitions: Dataset[NodeCountPartition] = topologyGeometryData.map { partition =>
val quads = partition.node
.flatMap(_.geometry)
.map(
g => HereQuadFactory.INSTANCE.getMapQuadByLocation(g.latitude, g.longitude, 14).getLongKey
)
.groupBy(identity)
.map {
case (tileId, seq) => NodeCount(tileId, seq.size)
}
NodeCountPartition(partition.partitionName, quads.toSeq)
}
// Encode the output partitions, convert to DataFrame and publish the output data
nodeCountPartitions
.map(p => (p.partitionName, p.toGeoJson.getBytes))
.toDF("mt_partition", "data")
.writeLayer(outputHrn, outputLayer)
.withDataConverter(new VersionedDataConverter {
def serializeGroup(rowMetadata: VersionedRowMetadata,
rows: Iterator[Row]): GroupedData[VersionedRowMetadata] =
GroupedData(rowMetadata, rows.next().getAs[Array[Byte]]("data"))
})
.save()
sparkSession.stop()
}
// Class representing the number of nodes in a level 14 sub-tile
case class NodeCount(tileId: Long, count: Int) {
def toGeoJson: String = {
val box = HereQuadFactory.INSTANCE.getMapQuadByLongKey(tileId).getBoundingBox
val e = box.getEast
val w = box.getWest
val n = box.getNorth
val s = box.getSouth
val color = {
// from black (0 nodes) to red (500 nodes)
s"rgb(${(count.min(500).toDouble / 500 * 255).toInt},0,0)"
}
"""{"type":"Feature",""" +
s""""geometry":{"type":"Polygon","coordinates":[[[$w,$s],[$e,$s],[$e,$n],[$w,$n],[$w,$s]]]},""" +
s""""properties":{"description":{"tileId":$tileId,"count":$count},"style":{"color":"$color"}}}"""
}
}
// Class representing the decoded content of an output partition
case class NodeCountPartition(partitionName: String, counts: Seq[NodeCount]) {
def toGeoJson: String =
s"""{"type":"FeatureCollection","features":[${counts.map(_.toGeoJson).mkString(",")}]}"""
}
}
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import com.here.hrn.HRN;
import com.here.olp.util.geo.BoundingBox;
import com.here.olp.util.quad.factory.HereQuadFactory;
import com.here.platform.data.client.spark.javadsl.JavaLayerDataFrameReader;
import com.here.platform.data.client.spark.javadsl.JavaLayerDataFrameWriter;
import com.here.platform.data.client.spark.javadsl.VersionedDataConverter;
import com.here.platform.data.client.spark.scaladsl.GroupedData;
import com.here.platform.data.client.spark.scaladsl.VersionedRowMetadata;
import com.here.platform.pipeline.PipelineContext;
import com.here.schema.rib.v2.TopologyGeometry.Node;
import com.here.schema.rib.v2.TopologyGeometryPartitionOuterClass;
import com.here.schema.rib.v2.TopologyGeometryPartitionOuterClass.TopologyGeometryPartition;
import com.typesafe.config.ConfigBeanFactory;
import java.io.Serializable;
import java.util.Iterator;
import java.util.List;
import java.util.stream.Collectors;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SparkConnectorLocal {
// Class representing the number of nodes in a level 14 sub-tile
public static class NodeCount {
private long tileId;
private int count;
public NodeCount(long tileId, int count) {
this.tileId = tileId;
this.count = count;
}
public String toGeoJson() {
BoundingBox box = HereQuadFactory.INSTANCE.getMapQuadByLongKey(tileId).getBoundingBox();
double e = box.getEast();
double w = box.getWest();
double n = box.getNorth();
double s = box.getSouth();
// from black (0 nodes) to red (500 nodes)
String color = String.format("rgb(%d,0,0)", (int) (Math.min(count, 500) / 500.0 * 255));
return String.format(
"{\"type\":\"Feature\","
+ "\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[%f, %f], [%f, %f], [%f, %f], [%f, %f], [%f, %f]]]},"
+ "\"properties\":{\"description\":{\"tileId\":%d,\"count\":%d},\"style\":{\"color\":\"%s\"}}}",
w, s, e, s, e, n, w, n, w, s, tileId, count, color);
}
}
// Class representing the decoded content of an output partition
public static class NodeCountPartition {
private String partitionName;
private List<NodeCount> counts;
public NodeCountPartition(String partitionName, List<NodeCount> counts) {
this.partitionName = partitionName;
this.counts = counts;
}
public String toGeoJson() {
return String.format(
"{\"type\":\"FeatureCollection\",\"features\":[%s]}",
counts.stream().map(NodeCount::toGeoJson).collect(Collectors.joining(",")));
}
public String getPartitionName() {
return partitionName;
}
}
// Class representing an encoded output partition
public static class OutputData implements Serializable {
private String mt_partition;
private byte[] data;
public OutputData(String mt_partition, byte[] data) {
this.mt_partition = mt_partition;
this.data = data;
}
// Minimal bean interface - required to use Encoders.bean
public String getMt_partition() {
return mt_partition;
}
public void setMt_partition(String mt_partition) {
this.mt_partition = mt_partition;
}
public byte[] getData() {
return data;
}
public void setData(byte[] data) {
this.data = data;
}
}
// We expose two static methods, `main` and `run`. `main` reads the pipeline context and the
// configuration from `pipeline-config.conf` and `application.conf`, while `run` accepts them
// as parameters. This makes it convenient to test the logic later using `run` with different
// configuration parameters, without having to pass them through the classpath.
public static void main(String[] args) {
// Read the default pipeline context
PipelineContext pipelineContext = new PipelineContext();
// Read the bounding box configured in `application.conf`
BoundingBox boundingBox =
ConfigBeanFactory.create(
pipelineContext.applicationConfig().getConfig("tutorial.boundingBox"),
BoundingBox.class);
run(pipelineContext, boundingBox);
}
public static void run(PipelineContext pipelineContext, BoundingBox bbox) {
// Defines the input / output catalogs to be read / written to
HRN inputHrn = pipelineContext.getConfig().getInputCatalogs().get("here-map-content");
HRN outputHrn = pipelineContext.getConfig().getOutputCatalog();
// Input / output layers
String topologyGeometryLayer = "topology-geometry";
String outputLayer = "node-count";
SparkSession sparkSession =
SparkSession.builder().appName("SparkTopologyNodeCount").getOrCreate();
// Read the input data as a Dataset of topology partitions
Dataset<TopologyGeometryPartitionOuterClass.TopologyGeometryPartition> topologyGeometryData =
JavaLayerDataFrameReader.create(sparkSession)
.readLayer(inputHrn, topologyGeometryLayer)
.query(
String.format(
"mt_partition=inboundingbox=(%f,%f,%f,%f)",
bbox.getNorth(), bbox.getSouth(), bbox.getEast(), bbox.getWest()))
.option("olp.connector.force-raw-data", true)
.load()
.select("data")
.as(Encoders.BINARY())
.map(
(MapFunction<byte[], TopologyGeometryPartition>)
TopologyGeometryPartition::parseFrom,
Encoders.kryo(TopologyGeometryPartitionOuterClass.TopologyGeometryPartition.class));
// Compute the output partitions
Dataset<NodeCountPartition> nodeCountPartitions =
topologyGeometryData.map(
(MapFunction<TopologyGeometryPartition, NodeCountPartition>)
partition -> {
List<NodeCount> counts =
partition
.getNodeList()
.stream()
.map(Node::getGeometry)
.map(
g ->
HereQuadFactory.INSTANCE
.getMapQuadByLocation(g.getLatitude(), g.getLongitude(), 14)
.getLongKey())
.collect(Collectors.groupingBy(t -> t))
.entrySet()
.stream()
.map(e -> new NodeCount(e.getKey(), e.getValue().size()))
.collect(Collectors.toList());
return new NodeCountPartition(partition.getPartitionName(), counts);
},
Encoders.kryo(NodeCountPartition.class));
// Encode the output partitions, convert to DataFrame and publish the output data
JavaLayerDataFrameWriter.create(
nodeCountPartitions
.map(
(MapFunction<NodeCountPartition, OutputData>)
p -> new OutputData(p.getPartitionName(), p.toGeoJson().getBytes()),
Encoders.bean(OutputData.class))
.toDF())
.writeLayer(outputHrn, outputLayer)
.withDataConverter(
new VersionedDataConverter() {
@Override
public GroupedData<VersionedRowMetadata> serializeGroup(
VersionedRowMetadata rowMetadata, Iterator<Row> rows) {
return new GroupedData<>(rowMetadata, rows.next().getAs("data"));
}
})
.save();
sparkSession.stop();
}
}
ローカルでコンパイルおよび実行します
アプリケーションをローカルで実行するには、次のコマンドを実行します。
Scala
Java
mvn compile exec:java \
-Dexec.mainClass=SparkConnectorLocalScala \
-Dpipeline-config.file=pipeline-config.conf \
-Dconfig.file=application.conf \
-Dspark.master="local[*]"
mvn compile exec:java \
-Dexec.mainClass=SparkConnectorLocal \
-Dpipeline-config.file=pipeline-config.conf \
-Dconfig.file=application.conf \
-Dspark.master="local[*]"
1 回の実行後、出力レイヤーおよび含まれているローカルデータ インスペクターを使用してローカル CLI を検査できます。
olp local catalog layer inspect hrn:local:data:::node-count node-count
オフラインの開発環境を作成します
これまでのところ、プラットフォームでホストされている入力カタログのみを使用しています。 外部ネットワークまたは HERE Credentials へのアクセスを必要としない開発環境を作成するには、次のコマンドを実行して、 HERE Map Content カタログのローカルコピーを作成します。
olp local catalog copy create hrn:here:data::olp-here:rib-2 \
--id here-map-content \
--include topology-geometry \
--filter [heretile]=bounding-box:52.67551,52.33826,13.76116,13.08835
ローカルカタログが作成さ hrn:local:data:::here-map-contentれます。 HERE Map Content カタログの最新バージョンをコピーtopology-geometry し、レイヤーのみを初期化してコピーします。 指定したバウンディング ボックスに含まれているパーティションのみを含めます。 ローカルカタログコピーは、ソースカタログに関する情報を保持する特殊なローカルカタログです。このカタログでは、次のコマンドを実行してローカルコピーを更新できます。
olp local catalog copy update hrn:local:data:::here-map-content
このローカルコピーを入力として使用するようにパイプライン設定を変更できるようになりました。
pipeline.config {
output-catalog {hrn = "hrn:local:data:::node-count"}
input-catalogs {
// Notice how we use a local catalog here - instead of the HERE Map Content catalog on the
// platform.
here-map-content {hrn = "hrn:local:data:::here-map-content"}
}
}
オプション here.platform.data-client.endpoint-locator.discovery-service-env=localで、プラットフォームのカタログにアクセスする必要はありません。を設定することで、ローカルカタログのみを使用するようにデータ クライアント ライブラリを設定できます。 これにより、ライブラリが認証トークンを取得しようとしないようにします。
Scala
Java
mvn compile exec:java \
-Dexec.mainClass=SparkConnectorLocalScala \
-Dpipeline-config.file=pipeline-config-local.conf \
-Dconfig.file=application.conf \
-Dspark.master="local[*]" \
-Dhere.platform.data-client.endpoint-locator.discovery-service-env=local
mvn compile exec:java \
-Dexec.mainClass=SparkConnectorLocal \
-Dpipeline-config.file=pipeline-config-local.conf \
-Dconfig.file=application.conf \
-Dspark.master="local[*]" \
-Dhere.platform.data-client.endpoint-locator.discovery-service-env=local
通勤中など、インターネットに接続せずにアプリケーションを開発して実行できるようになりました。
注
このチュートリアルでは、データ クライアント ライブラリのクエリ機能を使用して、小規模なバウンディング ボックスのみを処理しています。そのため、実際のプラットフォームでホストされているカタログから読み取るか、ローカルコピーから読み取るかにかかわらず、実行時間が短縮されます。 入力全体を処理するアプリケーションでは、まず入力カタログのクリップをコピー して開発サイクルを高速化し、ロジックがローカルデータで正しく動作することを確認した後で、パイプラインの実際のデータでロジックをテストすることをお勧めします。
サンプルアプリケーションをテストします
ローカルカタログを使用すると、処理アプリケーションのビジネスロジック全体を簡単にテストできます。 単一の方法を単体でテストすることは重要ですが、時間のかかるプロセスです。パイプライン全体をブラックボックスとしてテストすることも同様に重要です。 ただし、通常はプラットフォームでカタログリソースを作成してアクセスする必要があります。このため、自動化されたテストスイートを頻繁に実行すると、処理速度が遅くなり、コストがかかることがあります。 各開発者、または各テストの実行時に、一意の出力カタログにアクセスする必要があります。そのため、設定がさらに複雑になります。 ローカル のインメモリ カタログはメモリに保存され、単一のプロセスインスタンスにプライベートであるため、このような状況では理想的です。
注
インメモリ カタログの最大サイズは、 JVM で使用できるメモリ量によって制限されます。 大規模なローカルカタログでパフォーマンステストやストレステストを実行する必要がある場合here.platform.data-local.memory-mode=falseは、永続化されたカタログを使用することもできます () 。
まず、ファイルを作成してテスト構成を作成 src/test/resources/application.confします。 デフォルトでlocal環境を使用するようにデータ クライアント ライブラリを設定 します。この環境でAdminApiを使用してカタログを作成するには、が必要です。また、メモリ内のローカルカタログを有効にします。
here.platform.data-client {
# force local environment for all catalog accesses
endpoint-locator.discovery-service-env = local
}
here.platform.data-local {
# use in-memory local catalogs
memory-mode = true
}
1 つのテストを実行して、アプリケーションが各レベル 14 タイルのノード数を正しく計算していることを確認します。 このためには、まず、予期された出力から始まる擬似ランダム入力データを作成し、それをトポロジーパーティションにエンコードしてパイプラインを実行し、生成されたデータが予期された出力と一致することを確認します。 この設定を使用すると、複数のテストを異なるデータで実行でき、すべてのエッジケースをカバーできます。
Scala
Java
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import com.here.hrn.HRN
import com.here.olp.util.geo.BoundingBox
import com.here.olp.util.quad.factory.HereQuadFactory
import com.here.platform.data.client.engine.scaladsl.DataEngine
import com.here.platform.data.client.model._
import com.here.platform.data.client.scaladsl.{DataClient, NewPartition}
import com.here.platform.data.client.spark.DataClientSparkContextUtils.context._
import com.here.platform.data.client.spark.SparkSupport._
import com.here.platform.pipeline.{PipelineConfig, PipelineContext}
import com.here.schema.geometry.v2.geometry.Point
import com.here.schema.rib.v2.topology_geometry.Node
import com.here.schema.rib.v2.topology_geometry_partition.TopologyGeometryPartition
import org.junit.runner.RunWith
import org.scalatest.junit.JUnitRunner
import org.scalatest.{FlatSpec, Inspectors, Matchers}
import java.util.UUID
import scala.collection.JavaConverters._
import scala.util.Random
@RunWith(classOf[JUnitRunner])
class SparkConnectorLocalScalaTest extends FlatSpec with Matchers with Inspectors {
// Specify the bounding box used by our pipeline under test.
private val testBoundingBox = new BoundingBox(52.67551, 52.33826, 13.76116, 13.08835)
// Utilities to create a random topology node within a bounding box.
private val random = new Random(42)
private def randomInRange(min: Double, max: Double): Double =
min + (max - min) * random.nextDouble()
private def randomNode(boundingBox: BoundingBox): Node =
Node(
geometry = Some(
Point(
latitude = randomInRange(boundingBox.getSouth, boundingBox.getNorth),
longitude = randomInRange(boundingBox.getWest, boundingBox.getEast)
)
)
)
// Utility to create a catalog with a single HERE Tile versioned layer. The catalog will be local
// because we use `here.platform.data-client.endpoint-locator.discovery-service-env=local` in
// src/test/resources/application.conf. It will be kept in memory only, because we also use
// `here.platform.data-local.memory-mode=true`.
private def createCatalog(catalogIdPrefix: String, layerId: String): HRN =
DataClient()
.adminApi()
.createCatalog(
WritableCatalogConfiguration(
catalogIdPrefix + "-" + UUID.randomUUID().toString,
catalogIdPrefix,
"summary",
"description",
Seq(
WritableLayer(
layerId,
layerId,
"summary",
"description",
LayerTypes.Versioned,
HereTilePartitioning(List(12)),
DurableVolume,
contentType = "application/octet-stream"
)
)
)
)
.awaitResult()
// Utility to publish some test data in a catalog.
private def writeData(hrn: HRN, layer: String, data: Map[String, Array[Byte]]): Unit = {
val partitions = data.map {
case (partitionId, data) =>
NewPartition(
partitionId,
layer,
NewPartition.ByteArrayData(data)
)
}
DataEngine()
.writeEngine(hrn)
.publishBatch2(4, Some(Seq(layer)), Nil, partitions.iterator)
.awaitResult()
}
// Utility to read the data from the latest version of a catalog.
private def readData(hrn: HRN, layer: String): Map[String, Array[Byte]] = {
val readEngine = DataEngine().readEngine(hrn)
val queryApi = DataClient().queryApi(hrn)
queryApi
.getLatestVersion()
.flatMap {
case None => fail("Catalog is empty")
case Some(v) => queryApi.getPartitionsAsIterator(v, layer)
}
.awaitResult()
.map(p => p.partition -> readEngine.getDataAsBytes(p).awaitResult())
.toMap
}
// Utility to create an input test catalog given the expected outcome. `expectedCounts` is a map
// containing, for each level 14 tile ID, the number of nodes contained in that sub-tile.
// This method creates the requested number of topology nodes in each level-14 tile, encodes them
// in a topology partition and publishes them in a freshly created test catalog.
private def createTestInputCatalog(expectedCounts: Map[Long, Int]): HRN = {
val hrn = createCatalog("input", "topology-geometry")
val partitions: Map[String, Array[Byte]] = expectedCounts
.map {
case (tileId, count) =>
val boundingBox = HereQuadFactory.INSTANCE.getMapQuadByLongKey(tileId).getBoundingBox
val nodes = (1L to count).map(_ => randomNode(boundingBox))
tileId -> nodes
}
.groupBy {
case (tileId, _) =>
HereQuadFactory.INSTANCE.getMapQuadByLongKey(tileId).getAncestor(12).getLongKey
}
.map {
case (tileId, nodes) =>
tileId.toString -> TopologyGeometryPartition(
partitionName = tileId.toString,
node = nodes.values.reduce(_ ++ _)
).toByteArray
}
writeData(hrn, "topology-geometry", partitions)
hrn
}
// Utility to create an output catalog for the pipeline.
private def createTestOutputCatalog(): HRN = createCatalog("output", "node-count")
// Utility to retrieve the actual node count per level 14 tile in the output catalog. It reads the
// latest version of the catalog, retrieves the data, decodes it and returns the node count
// encoded in each level 14 tile. This is used, after a run of the pipeline under test, to verify
// that the node count is the expected on.
private def readActualNodeCount(hrn: HRN): Map[Long, Int] = {
// We use regular expressions to extract the tileId of the level 14 tiles and their node count.
// Using a proper JSON parser is left as an exercise.
val descriptionRegex =
""""description":\s*\{"tileId":\s*(\d+),\s*"count":\s*(\d+)}""".r.unanchored
readData(hrn, "node-count").flatMap {
case (_, data) =>
val geoJson = new String(data)
descriptionRegex.findAllMatchIn(geoJson).map(m => m.group(1).toLong -> m.group(2).toInt)
}
}
// Randomly generated expected result. For each level 14 tile in `testBoundingBox` we generate a
// random non-negative node count. We filter out zeros because those are by design not encoded by
// the pipeline under test.
private val expectedNodeCount: Map[Long, Int] = {
HereQuadFactory.INSTANCE
.iterableBoundingBoxToMapQuad(testBoundingBox, 14)
.asScala
.map { quad =>
quad.getLongKey -> (random.nextInt.abs % 100)
}
.filter(_._2 != 0)
.toMap
}
"SparkConnectorLocalScala" should "correctly compute the number of nodes in each sub-tile" in {
// Create the input catalog and publish the test data.
val inputHrn = createTestInputCatalog(expectedNodeCount)
// Create an empty output catalog.
val outputHrn = createTestOutputCatalog()
val pipelineContext =
PipelineContext(PipelineConfig(outputHrn, Map("here-map-content" -> inputHrn)))
// Run the pipeline under test.
SparkConnectorLocalScala.run(pipelineContext, testBoundingBox)
// Check the output data.
readActualNodeCount(outputHrn) should contain theSameElementsAs expectedNodeCount
}
}
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import static junit.framework.TestCase.assertEquals;
import com.here.hrn.HRN;
import com.here.olp.util.geo.BoundingBox;
import com.here.olp.util.quad.factory.HereQuadFactory;
import com.here.platform.data.client.engine.javadsl.DataEngine;
import com.here.platform.data.client.engine.javadsl.ReadEngine;
import com.here.platform.data.client.javadsl.DataClient;
import com.here.platform.data.client.javadsl.NewPartition;
import com.here.platform.data.client.javadsl.Partition;
import com.here.platform.data.client.javadsl.QueryApi;
import com.here.platform.data.client.model.*;
import com.here.platform.data.client.spark.DataClientSparkContextUtils;
import com.here.platform.pipeline.PipelineConfig;
import com.here.platform.pipeline.PipelineContext;
import com.here.schema.geometry.v2.GeometryOuterClass;
import com.here.schema.rib.v2.TopologyGeometry;
import com.here.schema.rib.v2.TopologyGeometryPartitionOuterClass;
import java.util.*;
import java.util.concurrent.CompletionStage;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import java.util.stream.StreamSupport;
import org.junit.Test;
public class SparkConnectorLocalTest {
// Simple Pair class used to collect maps with Java streams.
static class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
}
// Specify the bounding box used by our pipeline under test.
private BoundingBox testBoundingBox = new BoundingBox(52.67551, 52.33826, 13.76116, 13.08835);
// Utilities to create a random topology node within a bounding box.
private Random random = new Random(42);
private double randomInRange(double min, double max) {
return min + (max - min) * random.nextDouble();
}
private TopologyGeometry.Node randomNode(BoundingBox boundingBox) {
return TopologyGeometry.Node.newBuilder()
.setGeometry(
GeometryOuterClass.Point.newBuilder()
.setLatitude(randomInRange(boundingBox.getSouth(), boundingBox.getNorth()))
.setLongitude(randomInRange(boundingBox.getWest(), boundingBox.getEast()))
.build())
.build();
}
// Utility to create a catalog with a single HERE Tile versioned layer. The catalog will be local
// because we use `here.platform.data-client.endpoint-locator.discovery-service-env=local` in
// src/test/resources/application.conf. It will be kept in memory only, because we also use
// `here.platform.data-local.memory-mode=true`.
private HRN createCatalog(String catalogIdPrefix, String layerId) {
return await(
DataClient.get(DataClientSparkContextUtils.context().actorSystem())
.adminApi()
.createCatalog(
new WritableCatalogConfiguration.Builder()
.withId(catalogIdPrefix + "-" + UUID.randomUUID().toString())
.withName("name")
.withSummary("summary")
.withDescription("description")
.withLayers(
Collections.singletonList(
new WritableLayer.Builder()
.withId(layerId)
.withName("name")
.withSummary("summary")
.withDescription("description")
.withLayerType(LayerTypes.Versioned())
.withPartitioning(
Partitioning.HereTile()
.withTileLevels(Collections.singletonList(12))
.build())
.withVolume(Volumes.Durable())
.withContentType("application/octet-stream")))
.build()));
}
// Utility to publish some test data in a catalog.
private void writeData(HRN hrn, String layer, Map<String, byte[]> data) {
Iterator<NewPartition> partitions =
data.entrySet()
.stream()
.map(
e ->
new NewPartition.Builder()
.withPartition(e.getKey())
.withLayer(layer)
.withData(e.getValue())
.build())
.collect(Collectors.toList())
.iterator();
await(
DataEngine.get(DataClientSparkContextUtils.context().actorSystem())
.writeEngine(hrn)
.publishBatch2(
4,
Optional.of(Collections.singletonList(layer)),
Collections.emptyList(),
partitions));
}
// Utility to read the data from the latest version of a catalog.
private Map<String, byte[]> readData(HRN hrn, String layer) {
ReadEngine readEngine =
DataEngine.get(DataClientSparkContextUtils.context().actorSystem()).readEngine(hrn);
QueryApi queryApi =
DataClient.get(DataClientSparkContextUtils.context().actorSystem()).queryApi(hrn);
Iterable<Partition> partitions =
() ->
await(
queryApi
.getLatestVersion(OptionalLong.empty())
.thenApply(
v -> v.orElseThrow(() -> new RuntimeException("Output catalog is empty")))
.thenCompose(
v -> queryApi.getPartitionsAsIterator(v, layer, Collections.emptySet())));
return StreamSupport.stream(partitions.spliterator(), false)
.map(p -> new Pair<>(p.getPartition(), await(readEngine.getDataAsBytes(p))))
.collect(Collectors.toMap(Pair::getKey, Pair::getValue));
}
// Utility to create an input test catalog given the expected outcome. `expectedCounts` is a map
// containing, for each level 14 tile ID, the number of nodes contained in that sub-tile.
// This method creates the requested number of topology nodes in each level-14 tile, encodes them
// in a topology partition and publishes them in a freshly created test catalog.
private HRN createInputCatalog(Map<Long, Integer> expectedNodeCount) {
HRN hrn = createCatalog("input", "topology-geometry");
Map<String, byte[]> partitions =
expectedNodeCount
.entrySet()
.stream()
.map(
e -> {
BoundingBox boundingBox =
HereQuadFactory.INSTANCE.getMapQuadByLongKey(e.getKey()).getBoundingBox();
List<TopologyGeometry.Node> nodes =
IntStream.rangeClosed(1, e.getValue())
.mapToObj(notused -> randomNode(boundingBox))
.collect(Collectors.toList());
return new Pair<>(e.getKey(), nodes);
})
.collect(
Collectors.groupingBy(
p ->
HereQuadFactory.INSTANCE
.getMapQuadByLongKey(p.getKey())
.getAncestor(12)
.getLongKey()))
.entrySet()
.stream()
.map(
e -> {
byte[] data =
TopologyGeometryPartitionOuterClass.TopologyGeometryPartition.newBuilder()
.setPartitionName(String.valueOf(e.getKey()))
.addAllNode(
e.getValue()
.stream()
.flatMap(p -> p.getValue().stream())
.collect(Collectors.toList()))
.build()
.toByteArray();
return new Pair<>(String.valueOf(e.getKey()), data);
})
.collect(Collectors.toMap(Pair::getKey, Pair::getValue));
writeData(hrn, "topology-geometry", partitions);
return hrn;
}
// Utility to create an output catalog for the pipeline.
private HRN createOutputCatalog() {
return createCatalog("output", "node-count");
}
private <T> T await(CompletionStage<T> stage) {
try {
return stage.toCompletableFuture().get();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// Utility to retrieve the actual node count per level 14 tile in the output catalog. It reads the
// latest version of the catalog, retrieves the data, decodes it and returns the node count
// encoded in each level 14 tile. This is used, after a run of the pipeline under test, to verify
// that the node count is the expected on.
private Map<Long, Integer> readActualNodeCount(HRN hrn) {
// We use regular expressions to extract the tileId of the level 14 tiles and their node count.
// Using a proper JSON parser is left as an exercise.
Pattern descriptionRegex =
Pattern.compile("\"description\":\\s*\\{\"tileId\":\\s*(\\d+),\\s*\"count\":\\s*(\\d+)}");
return readData(hrn, "node-count")
.entrySet()
.stream()
.flatMap(
e -> {
String geoJson = new String(e.getValue());
Matcher matcher = descriptionRegex.matcher(geoJson);
List<Pair<Long, Integer>> matches = new ArrayList<>();
while (matcher.find()) {
matches.add(
new Pair<>(
Long.parseLong(matcher.group(1)), Integer.parseInt(matcher.group(2))));
}
return matches.stream();
})
.collect(Collectors.toMap(Pair::getKey, Pair::getValue));
}
private Map<Long, Integer> initializeExpectedNodeCount() {
return StreamSupport.stream(
HereQuadFactory.INSTANCE
.iterableBoundingBoxToMapQuad(testBoundingBox, 14)
.spliterator(),
false)
.map(quad -> new Pair<>(quad.getLongKey(), Math.abs(random.nextInt()) % 100))
.filter(pair -> pair.getValue() != 0)
.collect(Collectors.toMap(Pair::getKey, Pair::getValue));
}
// Randomly generated expected result. For each level 14 tile in `testBoundingBox` we generate a
// random non-negative node count. We filter out zeros because those are by design not encoded by
// the pipeline under test.
private Map<Long, Integer> expectedNodeCount = initializeExpectedNodeCount();
@Test
public void correctNodeCountTest() {
// Create the input catalog and publish the test data.
HRN inputHrn = createInputCatalog(expectedNodeCount);
// Create an empty output catalog.
HRN outputHrn = createOutputCatalog();
PipelineContext pipelineContext =
new PipelineContext(
new PipelineConfig(outputHrn, Collections.singletonMap("here-map-content", inputHrn)),
Optional.empty());
// Run the pipeline under test.
SparkConnectorLocal.run(pipelineContext, testBoundingBox);
// Check the output data.
assertEquals(readActualNodeCount(outputHrn), expectedNodeCount);
}
}
Maven でテストを実行するには、次のコマンドを実行します。
mvn test -Dspark.master=local[*]
プラットフォームにデプロイします
アプリケーションに問題がなければ、次のように Fat JAR ファイル を作成できます。
mvn -Pplatform clean package
コードを変更せずに、パイプライン API 経由で展開します。 パイプラインの展開の詳細について は、『 Pipelines 開発者ガイド』を参照してください。
詳細情報
このチュートリアルで扱うトピックの詳細については、次のソースを参照してください。
- さまざまなレイヤータイプおよびレイヤー設定については 、 Data API のドキュメントを参照してください
- カタログの対話式の照会および操作の詳細については 、 OLP CLI のドキュメント および 「データ」セクションを参照してください
- プラットフォームにアクセスするための Scala および Java API の詳細については 、データ クライアント ライブラリ開発者ガイドを確認してください