- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
バッチ パイプライン
HERE Workspace では、ワークスペースでの豊富で厳密なバッチ処理モデルが提供されます。このモデルは、単にデータをチャンク単位で処理するだけではありません。 これは、バージョン管理されたデータの処理および出力としてのバージョン管理されたデータの作成に関連するほとんどの使用例を支援します。 これを伝えるもう 1 つの方法は、ワークスペースがスナップショットからスナップショットへのコンパイルをサポートしていることです。 このモデルは、入力データが定期的に更新され、何度も処理する必要がある場合に役立ちます。
ただし、データを 1 回のみ処理するユースケースもあります。 または、 Spark および DDs の使用経験が豊富な場合があります。そのため、純粋な体験をご希望の場合もあります。 したがって、 HERE Workspace では、ワークスペースでストリーミング処理を行うときに Flink で直接作業する場合にも使用するのと同じコンポーネントを使用して、ワークスペース内の Spark で直接作業することもできます。
バッチ処理モデルは、ワークスペースがバージョン管理されたデータを保存する方法から開始して、ワークスペース内の複数のレベルに実装されます。引き続き、パイプライン API が Spark でバッチジョブをトリガーする方法、およびバッチ処理アプリケーションの構築を支援するデータ プロセッシング ライブラリで終了する方法を使用します。
データ プロセッシング ライブラリを使用すると、この処理が自動的に行われ、ビジネスロジックに集中できます。 入力パーティションの一部のみが変更された場合、インクリメンタル・コンパイルによって処理時間とコストを節約できます。 ただし、この厳密なモデルから分離することはできません。 Spark で直接作業する場合は、出力カタログに書き込むときに依存関係も記述するようにする必要があります。
次の図は、バッチ パイプラインの作成を示しています。
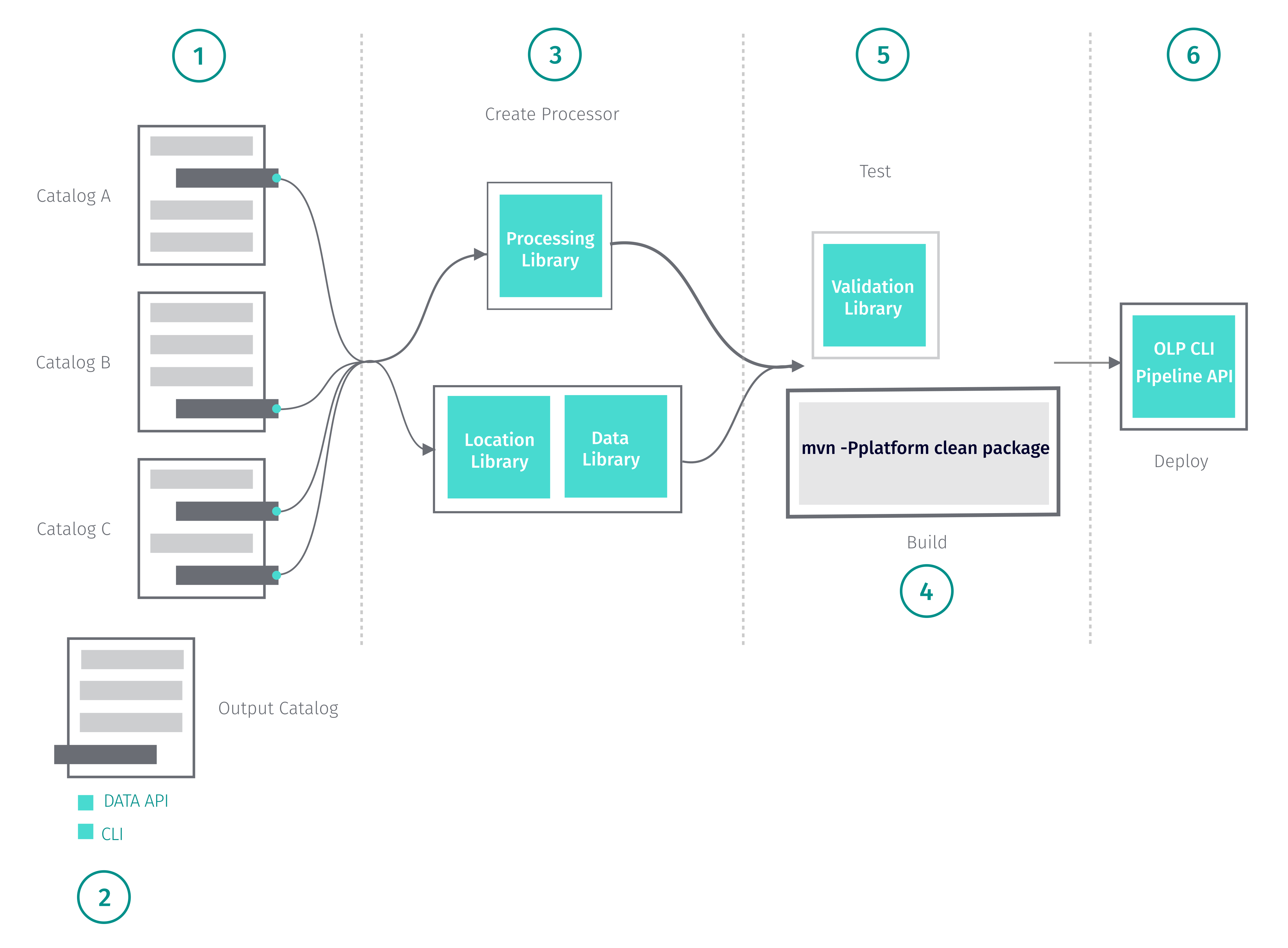
バッチ パイプラインを作成するには、次の手順を実行します。
-
データソースとして使用する 1 つ以上のバージョンレイヤーを指定します。
- ワークスペースでのデータカタログの操作の詳細については、Data API を参照してください。
- ワークスペースは、 HERE Map Content 仕様に基づいてマップ データを提供します。 HERE Map Content カタログのデータ構造の詳細について は、『 HERE Map Content データ仕様』を参照してください。
- Workspace には、センサーデータインジェストインターフェイス( SDII )に基づいたセンサーデータカタログが用意されています。 SDII カタログのデータ構造について詳しく は、 SDII データ仕様を参照してください。
- HERE Workspace では、独自のデータを取得することもできます。 独自の形式でデータを使用する方法の詳細については、Data API を参照してください。
-
出力カタログを作成します。
- HERE ポータル には、データカタログを管理するための UI が用意されています。 ワークスペースでのカタログの作成の詳細については、Data API を参照してください。
- OLP CLI には、データカタログを管理するためのコマンド ラインオプションがあります。 OLP CLI データコマンドの詳細については 、『 OLP CLI ユーザー ガイド』を参照してください。
- REST リクエストを使用する場合、 Data API はデータカタログを管理するための一連のエンドポイントを提供します。 詳細については 、 Data API 開発者ガイドを参照してください。
- パイプラインを作成し、出力レイヤーに書き込みます。
- データ プロセッシング ライブラリには、データの変換および出力レイヤーへの書き込みのための処理アルゴリズムおよびカスタムロジックを定義、実装、および展開するためのクラスとメソッドがあります。 データ プロセッシング ライブラリの詳細については 、『データ プロセッシング ライブラリ開発者ガイド』を参照してください。
- ロケーション ライブラリには、クラスタリング、マップマッチング、およびその他の機能などの操作のためのクラスとメソッドがあります。 ロケーション ライブラリの詳細については 、『ロケーション ライブラリ開発者ガイド』を参照してください。
- ロケーション ライブラリを使用すると、データ クライアント ライブラリを使用してデータを取得し、出力を出力レイヤーに書き込むことができます。 データ クライアント ライブラリの使用方法の詳細について は、『データ クライアント ライブラリ開発者ガイド』を参照してください。
-
パイプラインを構築します。
- パイプラインをファット JAR として構築するには、以下のコマンドを使用します。
mvn -Pplatform clean package- このコマンドは、環境 POM を親 POM として使用している場合にのみ使用できます。
- データ プロセッシング ライブラリおよびロケーション ライブラリの使用方法を示す例について は、「コード例」を参照してください。
- データ プロセッシング ライブラリの使用方法を示すチュートリアルについては、「カタログのコピー」チュートリアルを参照してください。
- ロケーション ライブラリの使用方法を示すチュートリアルについては、「センサデータと GeoJSON のパスの一致」チュートリアルを参照してください。
- パイプラインによって生成された出力をテストします。
- データ プロセッシング ライブラリの検証モジュールを使用すると、ワークスペースでバージョン管理されたデータレイヤーをテストできます。 詳細については 、データ プロセッシング ライブラリ開発者ガイドを参照してください。
- 展開。
- HERE Workspace には、パイプラインを管理するための UI が用意されています。 パイプラインをポータルに展開する方法の詳細について 開発者ガイドは、『パイプライン管理ガイド』を参照してください。
- OLP CLI には、ワークスペースで JAR ファイル を展開および管理するためのコマンドツールが用意されています。 OLP CLI パイプラインコマンドの詳細については 、『 OLP CLI ユーザー ガイド』を参照してください。
- REST 要求を使用する場合、パイプライン API は一連のエンドポイントを提供します。 詳細については 、パイプライン API 開発者ガイドを参照してください。
データ プロセッシング ライブラリ開発者ガイドでは 、 Java を使用し て Maven の原型を使用してバッチ パイプラインを構築する方法、 および Scala を使用して Maven の原型を使用してバッチ パイプラインを構築する方法についての詳細情報を提供しています。