- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
バッチ処理モジュール
現時点で使用できるアルゴリズムは次のとおりです。
- 2D オブジェクトの密度ベースのクラスタリング (分散クラスタリング)
SBT
Maven
グレードル
libraryDependencies ++= Seq(
"com.here.platform.location" %% "location-spark" % "0.21.788"
)<dependencies>
<dependency>
<groupId>com.here.platform.location</groupId>
<artifactId>location-spark_${scala.compat.version}</artifactId>
<version>0.21.788</version>
</dependency>
</dependencies>dependencies {
compile group: 'com.here.platform.location', name: 'location-spark_2.12', version:'0.21.788'
}クラスタリング
クラスタリングアルゴリズムは、分散バージョン の DBScan を実装します。 地理的に分散した地理位置のアイテムをクラスタ化します。 アルゴリズムの動作を例証するには、次の図を参照してください。
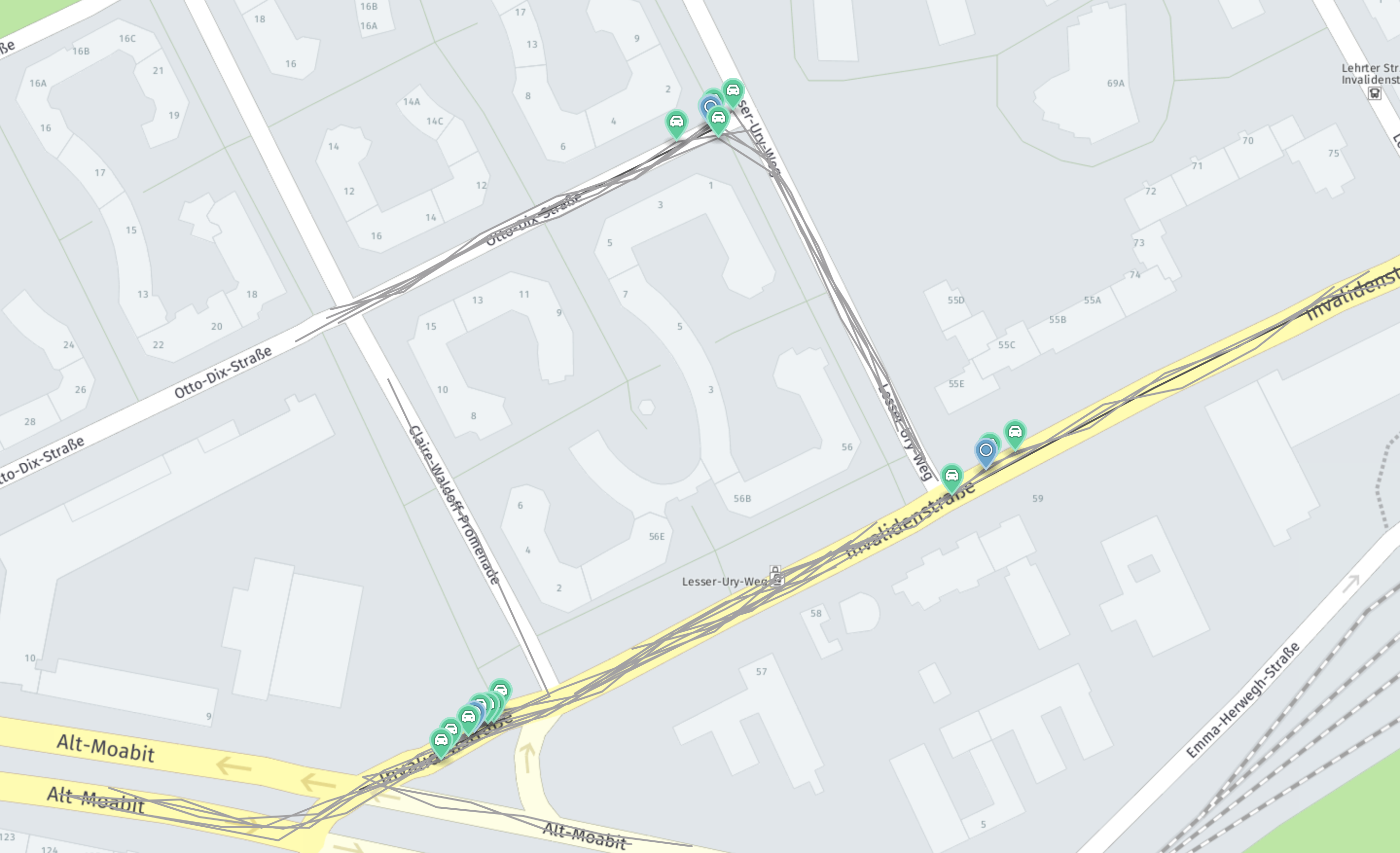
入力データには、報告されたさまざまな旅程とイベントが含まれています。 これらのイベントは緑色で示されます。 この図は、これらのクラスタを示しています。 各インスタンスについて 、クラスタのインスタンス が返されます。 青色のマーカーはクラスタの中心を示しています。
次 のように DistributedClustering を使用できます。
Scala
import com.here.platform.location.spark.{Cluster, DistributedClustering}
import org.apache.spark.rdd.RDD
val events: RDD[Event] = mapPointsToEvents(sensorData)
val dc = new DistributedClustering[Event](neighborhoodRadiusInMeters = 20.0,
minNeighbors = 3,
partitionBufferZoneInMeters = 125.0)
val clusters: RDD[Cluster[EventWithPosition]] = dc(events)
val result = clusters.collect()
assert(result.nonEmpty)
// Print some statistics
val clusterCount = result.length
val clusteredEvents = result.map(_.events.length).sum.toDouble
println(s"Found $clusterCount clusters")
println(s"Found $clusteredEvents events in total.")
println(s"An average of ${clusteredEvents / clusterCount} event per cluster")独自 のEventタイプに対応する地理位置情報を抽出するには、 GeoCoordinateOperations の暗黙的なインスタンスが必要です。