- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
Batch Processing Module
At the moment the only available algorithm is:
- Density-based clustering of 2D objects (DistributedClustering)
SBT
Maven
Gradle
libraryDependencies ++= Seq(
"com.here.platform.location" %% "location-spark" % "0.21.788"
)<dependencies>
<dependency>
<groupId>com.here.platform.location</groupId>
<artifactId>location-spark_${scala.compat.version}</artifactId>
<version>0.21.788</version>
</dependency>
</dependencies>dependencies {
compile group: 'com.here.platform.location', name: 'location-spark_2.12', version:'0.21.788'
}Clustering
The clustering algorithm implements a distributed version of DBScan. It clusters geographically spread, geolocated items. To exemplify what the algorithm does, see the following image:
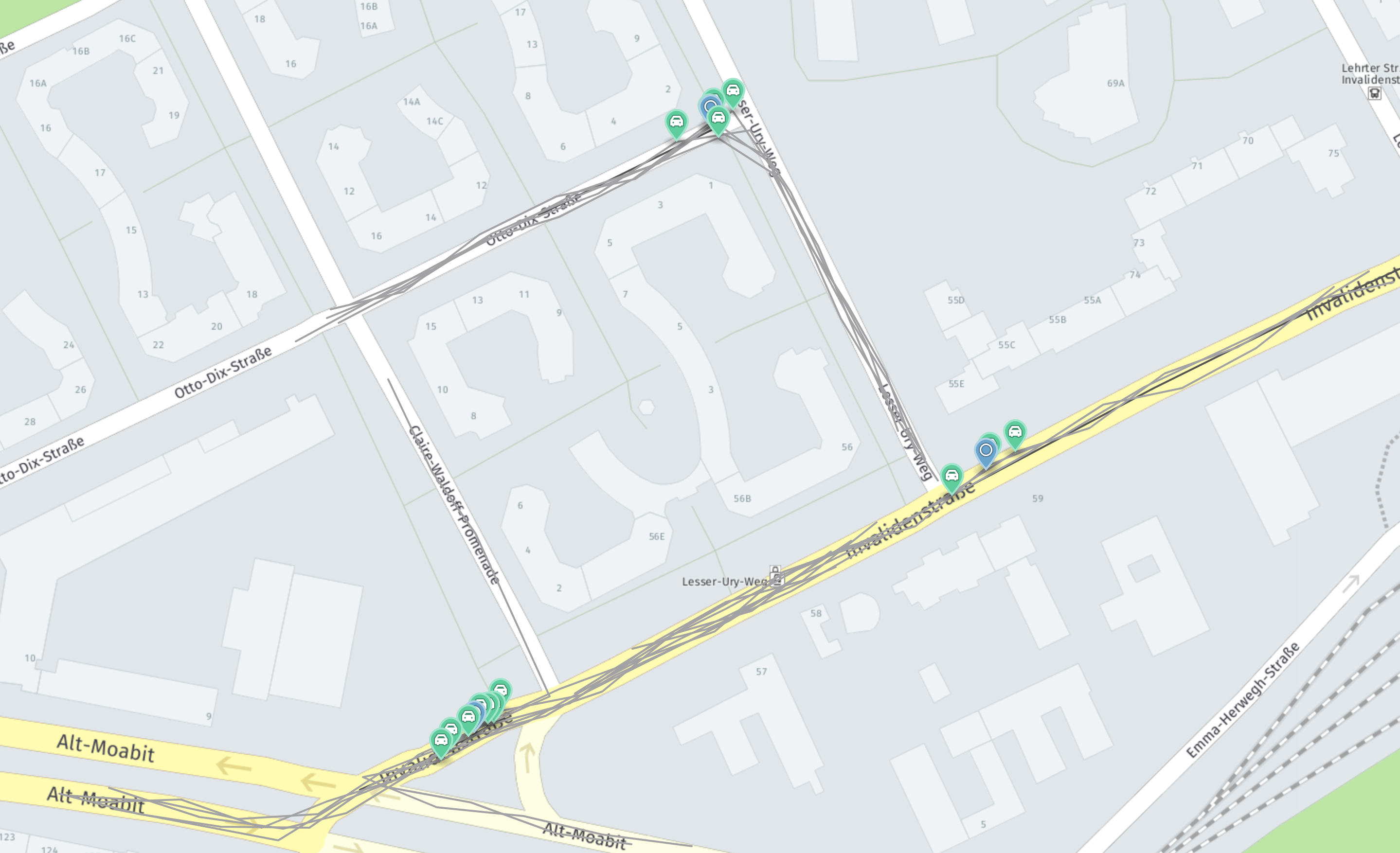
The input data contains different trips and events reported along them. These events are marked in green. The image shows these clusters. For each of them, an instance of Cluster is returned. The blue markers represent the cluster centers.
You can use DistributedClustering as follows:
Scala
import com.here.platform.location.spark.{Cluster, DistributedClustering}
import org.apache.spark.rdd.RDD
val events: RDD[Event] = mapPointsToEvents(sensorData)
val dc = new DistributedClustering[Event](neighborhoodRadiusInMeters = 20.0,
minNeighbors = 3,
partitionBufferZoneInMeters = 125.0)
val clusters: RDD[Cluster[EventWithPosition]] = dc(events)
val result = clusters.collect()
assert(result.nonEmpty)
// Print some statistics
val clusterCount = result.length
val clusteredEvents = result.map(_.events.length).sum.toDouble
println(s"Found $clusterCount clusters")
println(s"Found $clusteredEvents events in total.")
println(s"An average of ${clusteredEvents / clusterCount} event per cluster")You need an implicit instance of GeoCoordinateOperations to extract a GeoLocation that corresponds to your own Event type.