- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
パフォーマンスチューニング
コンパイラーを実装する場合、コンパイラーのパフォーマンスを調整するために使用できるステップがいくつかあります。 このトピックでは、処理順序に従って潜在的なボトルネックを一覧表示します。
ヒント Spark は、さまざまなステージのプロセスに重なり合うことが多いため、どのステージが処理を遅くしているかを簡単に特定できない場合があります。 エラーのあるステージを特定する 1 つの方法は、後のステージのコードを空のスタブ実装で置き換えることです。 たとえば、 RefTreeCompiler のみ、 resolveFn または resolveFn および compileInFn に実際の処理コードが含まれているとします。
Spark の設定
Spark には、アプリケーションを設定するための Spark プロパティのセットが用意されています。 これらの値は、 Java システムのプロパティを使用して設定できます。このプロパティは、 --conf オプションを使用してコマンド ラインの引数として spark-submit 設定するか、または SparkContext オブジェクトの作成時にハードコード化できます。
データ プロセッシング ライブラリを使用すると、特定のバッチ処理アプリケーション用に Spark をより簡単に設定できます。 Spark のプロパティは、次の application.conf here.platform.data-processing.spark セクションで追加できます。
here.platform.data-processing.spark {
default.parallelism = 512
}
これらの設定は、の作成に使用されます SparkContext。
カスタムの Kyro 登録者
パフォーマンス上の理由から、データ プロセッシング ライブラリでは Kryo シリアル化フレームワークが頻繁に使用されます。 このフレームワークは、 Spark が RDD に存在するオブジェクトをシリアライズおよびデシリアライズするために使用します。 これには、パーティションキーやメタデータなどの広く使用されている概念だけでなく、Tでコンパイルパターンで識別された開発者が使用するカスタムタイプも含まれます。 また、 RDD ベースのパターンでは、開発者は任意のカスタムタイプを自由に導入し、そのようなタイプの DDs を宣言して使用できます。
処理中のライブラリは、アプリケーションで使用されているすべてのカスタムタイプを認識しませんが、 Kyro フレームワークにはこの情報が必要です。 そのため、処理ライブラリを専門とするカスタムレジストラを提供 KyroRegistrator して、自動的に登録されるクラスおよびカスタムタイプのリストを返す必要があります。
例 :
package com.mycompany.myproject
class MyKryoRegistrator extends com.here.platform.data.processing.spark.KryoRegistrator {
override def userClasses: Seq[Class[_]] = Seq(
classOf[MyClass1],
classOf[MyClass2]
)
}
クラスの名前は、次の方法でライブラリ設定に提供する必要が application.confあります。
here.platform.data-processing.spark {
kryo.registrationRequired = true
kryo.registrator = "com.mycompany.myproject.MyKryoRegistrator"
}
Resolve 関数への並列呼び出し (RefTreeCompiler のみ )
実行ごとに並列スレッド数を調整できます。 デフォルトは 10 です。つまり、 10 個のスレッドが並列に動作します。
このフェーズでマシンのメモリが不足しているか、または CPU 使用率が非常に高い場合は、この数値を削減する必要があります。 CPU 使用率が低い場合 (75% 未満 ) 、コンパイラーはおそらくほとんどがネットワーク I/O を待っているため、この数を増やすことができます。 設定パラメータの名前は次のとおりです。
here.platform.data-processing.executors.reftree {
// number of threads to use within one executor to run the resolve function
parallelResolves = 10
}
通常、パーティションの内容はその参照を収集するために使用されるため、 RESOLVE 関数がペイロードを取得する必要があると想定しても安全です。 ペイロードの取得はブロッキング I/O 処理であるため、 RESOLVE 機能は同じ Spark ワーカーノード内であっても、並列実行によってメリットがあります。
並列実行で CPU オーバーヘッドが多すぎる場合 resolveFn ( パーティションの合計数と比較してパーティションのペイロードを取得する回数が少ない場合など ) は、このパラメータを 1 に設定して並列実行を無効にします。
compileIn 関数への並列呼び出し ( すべての関数コンパイラ )
HERE の最も一般的なパフォーマンスの影響を受ける要因は、パーティションが複数回読み取られていることです。たとえば、タイルを処理する際に、隣接するタイルをロードする必要がある場合です。
このような場合は、次のいずれかの方法でパフォーマンスを向上できます。
- キャッシュを使用
Retrieverして、に依存せずにタイルオブジェクトを読み込んでデコードします。 パーティションのサイズによっては、タイルのデシリアライズを複数回行った場合でも、 CPU の負荷が高くなり、ガーベッジコレクションの負荷が高くなることがあります。 これは、タイルには小さなオブジェクトが多数含まれている可能性があるためです。 基本的なパターンは、Retrieverを使用してタイルをロードし、タイルのKeyおよびMetaのペアを指定してデコードする更新関数を持っていることです。 次に、キャッシュオブジェクトを使用して、デコードされたタイルをそのKeyペアとペアから抽出Metaします。このとき、 UPDATE 関数を使用して、ミスが発生した場合にキャッシュをいっぱいにします。 - 大規模なカタログの場合、すべてのパーティションをキャッシュするのに十分なメモリ量ではない可能性があります。 この場合
LocalityAwarePartitioner、のを使用してパフォーマンスを改善できinPartitionerます。 処理済みタイルレベルよりも 2 ~ 5 のレベルを使用します。たとえば、レベル 14 の入力カタログの場合、レベル 9 ~ 12 が適切な値である可能性があります。 通常、ローカル性の向上( 9 などのグローバルレベルの向上)と、タイルの Spark パーティションへの分散の改善( 12 などの詳細レベル)の間にトレードオフがあります。 を使用する場合LocalityAwarePartitionerはsorting、設定で変数を設定することもお勧めします。 - HERE では、設定にチューニング可能な 2 つのパラメータがあります。 並列スレッド数を設定できます。並列スレッド数は、スレッド数が少ない場合のネットワーク I/O 遅延と、スレッド数が多い場合の高い場合の CPU およびメモリ使用量とのトレードオフになります。 または、 compileIn: を使用する場合は true に設定し、
LocalityAwarePartitionerを使用する場合は false に設定して、パーティション内のタイルの並べ替えを設定できHashPartitionerます。
here.platform.data-processing.executors.compilein {
// number of threads to use within one executor to run the compileIn function
threads = 10
// sorting will make sure partitions with similar partition name are compiled together,
// increasing cache hit ratio in many setups
sorting = true
}
Spark 並列処理
各 RDD が構成する Spark パーティションの数は、使用するパーティションによって異なります。 処理ライブラリは、 inPartitioner メソッドおよび outPartitioner メソッドを使用して、 compileIn メソッドおよび compileOut メソッドに渡された DDs をパーティションに渡します。 例 :
def inPartitioner(parallelism: Int): Option[Partitioner[InKey]] = {
Some(LocalityAwarePartitioner(parallelism, 10))
}
def outPartitioner(parallelism: Int): Option[Partitioner[OutKey]] = {
Some(HashPartitioner(parallelism))
}
inPartitioner および outPartitioner に渡された引数 parallelism は、設定パラメータ here.platform.data-processing.spark.default.parallelism の値です。 明示的に指定しない場合、これはすべての実行ノードのコア数と等しくなります。 大きなカタログを処理する場合、この数は少なすぎる可能性があり、 Spark のパーティションが少数になる可能性があります。 極端な場合は、になり OutOfMemoryErrorます。
この場合 application.conf、で値を明示的に設定することで、デフォルトの並列処理を増やすことができます。
here.platform.data-processing.spark.default.parallelism = 512
または、デフォルトの平行度に、パーティングの実装で係数を乗算できます。
def inPartitioner(parallelism: Int): Option[Partitioner[InKey]] = {
Some(HashPartitioner(parallelism * 3))
}
上記のソリューションを使用すると、タスクごとに異なる並列処理値を設定したり、同じタスクの異なるコンパイラーを設定したり、 compileIn および compileOut で使用される並列処理を個別に微調整できます。
並列処理の値を高く設定しすぎると、非常に短い Spark タスクが大量に発生し、計算のオーバーヘッドが顕著になります。 2 つのステージの間でエントリが同じ Spark パーティションにとどまる確率が高くなり、データのシャフリングが削減されます。この確率は、パーティション数の反比例します。 さらに、 Spark タスクは、最短 200ms の間効率的に実行できます。
compileIn と compileOut の間でシャッフル ( すべてのコンパイラ )
compileIn との間のすべてのデータ compileOut が 1 つの RDD に保存されます。 このようなフェーズ間で大量のデータが渡されると、次の理由により、クラスタ内で RDD が大量にシャッフルされる可能性があります。
- パーティション分割が
inPartitionerからに変更されますoutPartitioner Keyパーティションのが入力カタログから出力カタログに変更されます。
この問題は、次の方法で軽減できます。
- データの受け渡し量を削減できます。 処理方法が異なる場合
compileOutがあります。そのため、フェーズでのみ大きなデータが作成されます。 - と同様に
PartitionerNamePartitioner拡張 (LocalityAwarePartitionerまたはNameHashPartitioner) することで、同じパーティション作成者inPartitioneroutPartitionerを使用します。 このパーティション作成者は、カタログおよびレイヤー ID が変更された場合でも、同じ名前のパーティションが同じノードに保持されることを保証します。 このオプションはcompileIn、主に出力カタログ内の同じタイルのデータを生成する場合に役立ちます。 - 前述のように、デフォルトの RDD 永続化方式を変更します。 大量のデータが渡された場合、この RDD は非常に大きくなることがあるため、
MEMORY_ONLYおよびMEMORY_ONLY_ SERの設定によっては、ノードのメモリ使用量が少なくなることがあります。 この場合MEMORY_AND_DISK_SERは、代わりにを使用できます。
compileOut 関数への並列呼び出し ( すべての関数コンパイラ )
compileInに記載されているのと同じ規則が適用されます。
対応する設定は、個別に設定できます。
here.platform.data-processing.executors.compilein {
// number of threads to use within one executor to run the compileIn function
threads = 10
// sorting will make sure partitions with similar partition name are compiled together,
// increasing cache hit ratio in many setups
sorting = true
}
Spark でストレージレベルを調整しています
すべてのコンパイラ実行者が中間の RDD を作成します。 複数回使用されている DDs がある場合、同じ操作が複数回実行されないようにキャッシュされます。
次の理由により、複数の RDD クラスが永続化されます。
- Data API のクエリから取得された DDs 。
- メタデータおよび Blob API にペイロードをアップロードして公開することで取得された DDs 。
- 内部状態のシリアライズおよびデシリアライズによって取得された DDs 。
- 汎用 DDs 。デフォルトのクラスです。
これらの各クラスに Spark ストレージレベルを設定できます。 使用可能な値の一覧については 、 Spark のドキュメントを参照してください。
最も有効なストレージレベルの値は次のとおりです。
-
DISK_ONLY: RDD パーティションはディスクにのみ保存してください。 -
MEMORY_ONLY: RDD をデシリアライズされた Java オブジェクトとして Java 仮想マシン (JVM) に保存します。 RDD がメモリに収まらない場合、一部のパーティションはキャッシュされず、必要に応じてオンザフライで再計算されます。 -
MEMORY_ONLY_SER: RDD をシリアル化された Java オブジェクトとして保存します(パーティションごとに 1 バイトの配列)。 一般的に、これはデシリアライズされたオブジェクトよりもスペース効率が高くなります。特に、高速シリアライザを使用しているが、 CPU を多用して読み取る場合に適しています。 -
MEMORY_AND_DISK: RDD をデシリアライズされた Java オブジェクトとして JVM に保存します。 RDD がメモリに収まらない場合、適合しないパーティションはディスクに保存され、必要に応じてそこから読み取られます。 -
MEMORY_AND_DISK_SER: 上記のレベルと同じですが、各パーティションが 2 つのクラスタノードに複製されます。
現在、このように永続化された DDs は、の内部ステップである参照の収集に頻繁に使用 RefTreeCompilerExecutorされています。 での実装 RefTreeUtils.gatherReferences() は複雑です。 この操作中に、多数の DDs が生成され、永続化されます。 これらの DDs は、デフォルトクラスに属しています。
永続化された DDs のパフォーマンスへの影響を調整するには、次のパラメータを設定します。
here.platform.data-processing.driver.sparkStorageLevels {
default = "MEMORY_AND_DISK"
catalogQueries = "MEMORY_AND_DISK_SER"
publishedPayloads = "MEMORY_AND_DISK_SER"
persistedState = "MEMORY_AND_DISK_SER"
}
有効な値の詳細については 、「 RDD Persistence 」および 「選択するストレージレベル」を参照してください。
コンパイラーのパフォーマンスを向上させる可能性のある解決策は、次のとおりです。
- CPU とディスクの使用量が多いにもかかわらず、空きメモリがあるようであれば、
MEMORY_ONLYまたはMEMORY_ONLY_SERを試してください。 - メモリが不足しているにもかかわらず、 CPU の使用率が高い場合は、キャッシュスペースが不足している可能性があります (
MEMORY_AND_DISKまたはMEMORY_AND_DISK_SERを試してください ) 。 -
を使用
MEMORY_ONLY_SERし、コンパイラーのメモリ使用量が少ない場合は、シリアル化された RDD パーティションの RDD 圧縮プロパティを試してください。 既定では、このプロパティは Spark でオフになっています。 この機能を有効にすると、 CPU の使用量が増加するため、かなりのスペースを節約できます。 次のように有効にできます。// Whether to compress serialized RDD partitions (e.g. for MEMORY_ONLY_SER) here.platform.data-processing.spark.rdd.compress = true
作業者間のパーティションの分布の検査
Spark の Web UI には、ノード間のパーティションの分散状況がグラフィカルに表示されます。 表示するに Event Timelineは、 UI のステージに移動し、を開きます。
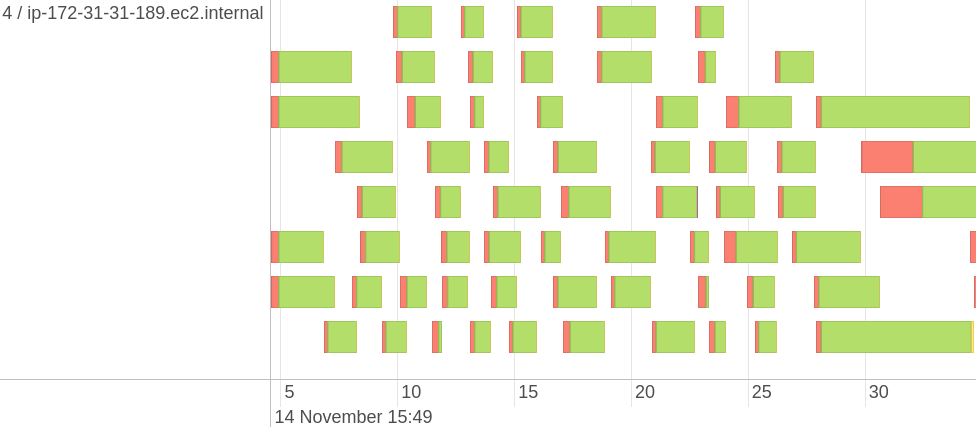
パーティションの分布は直接表示できませんが、さまざまなメトリクスを持つタスクのタイムラインを確認できます。たとえば、パーティションの分布を把握するのに役立つタスクのタイムライン Task Deserialization Time Executor Computing Time を確認できます。 上のイメージは、 1 つの Executor の配布を示しています。左側には、 executor の ID と IP アドレスが表示されています。 コンソールには、すべての実行者の配布が同時に表示されるため、どの程度の状態であるかを視覚的に見積もることができます。 正確な統計情報を取得するための組み込み機器はありません。 必要に応じて、ドライバーログを解析し、タスクのタイミングに関連付けられているすべての値を抽出できます。
デフォルトでは、最初の 100 件のタスクのみが表示されます。 視覚エフェクトを作成する前に、タスクに関連する情報が含まれているすべてのページを表示してください。 そうしないと、すべてのタスクが表示に含まれるわけではありません。

パーティションディストリビューションを分析するには、必要なステージを見つける必要もあります。 通常、 compileIn または compileOut です。 処理中のライブラリの RDD には、この RDD が属するステージを簡単に説明するテキストが付けられます。 複数の異なるコンパイラが存在し、それぞれが時間帯によって内部的に変更される可能性があるため、 DAG の視覚化での検索方法には汎用的なルールがありません。そのため、すべての段階のリストで、目的のステージを右の左に移動します。 compileIn ステージの例を次に示します。
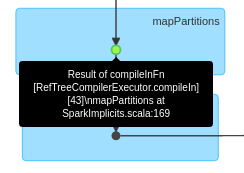
作業者間のパーティション配布の調整
ノード間でデータのパーティションを移動する操作にはコストがかかるため、 Spark はそのパーティションを回避し、データを処理するコードにできるだけ近い場所にデータを保存しようとします。 この概念はデータのローカル性と呼ば れます。詳細については、 Spark のドキュメントを参照してください。 これは、 Spark ジョブの開始時にデータが均等に分散されない場合、データが実際に存在するノードで計算が実行され、クラスタ内で利用可能なノード間での均等な負荷分散が防止されることを意味します。
ワーカーノード間のデータの分散にデータのローカル性が与える影響は 、 Spark 設定パラメータのセットを使用して制御できます。
特に、データのローカル性に対する負荷分散を優先するために、開発者は here.platform.data-processing.spark.locality.wait 次のセクションで説明するように、このパラメーターを使用できます。
spark.locality.wait を使用しています
spark.locality.wait は、公式の Spark API の一部です。 簡単に言うと、ローカル実行者がビジー状態のときに、データの一部がそのデータのローカルでない実行者に渡されるまでにかかる時間を定義します。 このパラメータを低い値に設定し、前述のようにデータが非常に不均等に分散されている場合、 Spark ではローカルでない実行者に処理を許可するだけです。 を指定すると here.platform.data-processing.spark.locality.wait=0、 Spark はまったく待機せず、ただちに別の実行者にデータを共有しようとします。
特定の Spark タスクの検査
Spark タスクの統計情報は、 Spark Web UI で表示できます。 このデータには、タスクの期間、タスクのデシリアライゼーション時間、実行時間、計算時間などのメトリクスが含まれます。 これらのタスクの一部を入力データに関連付けることができます。 たとえば、タスクのコンパイルに時間がかかりすぎて、そこでコンパイルされたデータを確認する必要がある場合などです。 TaskContext Spark の API を使用して確認できます。 この API は、現在のステージ、現在のタスクなどについての情報を提供し、ラムダ関数からアクセスできます。 API を使用すると、たとえば、 Spark タスクの ID と処理するキーを記録できます。
Spark の TaskContext API 内のデータ プロセッシング ライブラリで機能するコンパイラーの 1 つの制限事項は、 compileIn 関数と compileOut 関数の両方に対する並列呼び出しの数が 1 に設定されている場合にのみ使用できることです。 TaskContext は、並列コールの数が多い場合には使用できません。