- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
一般的な問題
一般的な問題とローカルの問題
Python エントリポイントが見つかりません
など sdk_setup.py のエラーが発生した場合にを使用して SDK をインストールするには Python.exe - Entry Point not found、次の手順を実行します。
-
conda がアクティブ化されます
-
conda が Python を更新します
Sparkmagic 拡張 skipna=true
NAT 値が含まれているデータを表示すると、段落の下に警告メッセージが表示されます。
/usr/local/lib/python3.6/site-packages/autovizwidget/widget/utils.py:50: FutureWarning:
A future version of pandas will default to `skipna=True`. To silence this warning, pass `skipna=True|False` explicitly.
この警告メッセージは、ノートブックの動作には影響しません。
これ は Sparkmagic の問題 であり 、 pandas.api.types.infer_dtype メソッドの skpna パラメータのデフォルト値が true の場合、将来のパンダバージョンで解決される予定です。
回避策: ノートブックの動作には影響がないため、操作は不要です。
Pyspark カーネル TypeError
Pyspark カーネル TypeError: object of type 'NoneType' has no len()。 %%SQL magic コマンドを使用して、 Spark からローカル Python にデータを渡します ( カーネルの再起動後 ) 。例 :
%%sql -o nodes
select * from nodes
次のエラーが発生します。
Traceback (most recent call last):
File "/usr/lib64/python2.7/SocketServer.py", line 295, in _handle_request_noblock
self.process_request(request, client_address)
File "/usr/lib64/python2.7/SocketServer.py", line 321, in process_request
self.finish_request(request, client_address)
File "/usr/lib64/python2.7/SocketServer.py", line 334, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "/usr/lib64/python2.7/SocketServer.py", line 649, in __init__
self.handle()
File "/usr/spark-2.4.0/python/lib/pyspark.zip/pyspark/accumulators.py", line 266, in handle
poll(authenticate_and_accum_updates)
File "/usr/spark-2.4.0/python/lib/pyspark.zip/pyspark/accumulators.py", line 241, in poll
if func():
File "/usr/spark-2.4.0/python/lib/pyspark.zip/pyspark/accumulators.py", line 254, in authenticate_and_accum_updates
received_token = self.rfile.read(len(auth_token))', "TypeError: object of type 'NoneType' has no len()"]
このエラー はすでにコミュニティによって緩和され ており、 Spark 2.4.1 でリリースされています。 地域社会の決定によれば、 Spark 3 ではコミュニティからの緩和策がなくなるため、最終的な解決策を見つけるには、さらなる調査が必要になります。
現在提供されている Spark のバージョンは 2.4.0 です。
回避策: 問題のある段落を再実行します。
セルエラーです requirement failed: Session isn't active.
次のエラーが発生した場合 :
An error was encountered:
Invalid status code '400' from http://livy:8998/sessions/[#]/statements/[#] with error playload: "requirement failed: Session isn't active."
これは、あなたのリヴィー / スパークドライバーのセッションが何らかの理由で終了しているためです。
フォルダ内の Livy ログを確認 ~/livy/logs/します。
Spark の UI で実行されているローカルデプロイメントの Spark 実行者リソースを確認することも http://localhost:4040/executors/できます。 EMR を使用 http://${master_dns}:4040/executors/して、で確認できます。
python-geohash の依存関係により、 conda 環境の作成中にエラーが発生しました
MacOS
gcc または Xcode (xcrun) に関連するエラーが表示された場合は、以下の手順を実行します。
ターミナルで、次のコマンドを実行して xcode-select をインストールします。
xcode-select --install
[ インストール ] および [ 同意 ] ボタンを選択し、インストール処理が完了するまで数分待ちます。
ここで、次のコマンドを実行します。
sudo installer -pkg /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg -target /
注
.pkg のバージョンが、そのパスにインストールしたものと同じであることを確認してください。
問題の詳細については 、「 HERE」をクリックしてください。
conda 環境のインストールをもう一度試してください。
CentOS
CentOS の場合は、 python-geohash 依存性のために libsasl2-devel パッケージをインストールする必要があります。
実行 :
sudo yum upgrade python-setuptools
sudo yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel
問題の詳細については 、 HERE を参照してください。
conda 環境のインストールをもう一度試してください。
データ クライアント ライブラリ使用中のエラー : No FileSystem for scheme: olp
データ クライアント ライブラリを使用してこのような例外が発生した場合は、次の手順を実行します
java.io.IOException: No FileSystem for scheme: olp
at org.apache.hadoop.fs.FileSystem.getFileSystemClass(FileSystem.java:2660)
at org.apache.hadoop.fs.FileSystem.createFileSystem(FileSystem.java:2667)
...
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:178)
at com.here.platform.data.client.spark.internal.IndexDataFrameReaderImpl.load(IndexDataFrameReaderImpl.scala:93)
... 56 elided
"spark.hadoop.fs.olp.impl""com.here.platform.data.client.hdfs.DataServiceHadoopFileSystem" Spark 設定で、値を使用してプロパティを指定します。
{
"driverMemory": "2G",
...,
"conf": {
...,
"spark.hadoop.fs.olp.impl": "com.here.platform.data.client.hdfs.DataServiceHadoopFileSystem",
...
}
}
Sparkmagic $HOME/.sparkmagic/config.json フィールドの JSON 設定ファイルに追加 session_configs -> conf -> spark.hadoop.fs.olp.implできます。 Python カーネルを使用している場合 %%spark config は、 magic コマンドを使用して Jupyter 段落で直接指定できます。
データ クライアント ライブラリを使用してインデックス化されたレイヤーを寄木細工で読み取る際にエラー
データ クライアント ライブラリを使用して、寄木細工のデータを含むインデックス化されたレイヤーを読み取る場合、次のようになります。
%%spark
import com.here.hrn.HRN
import com.here.platform.data.client.spark.IndexDataFrameReader._
import org.apache.spark.sql.{DataFrame, SparkSession}
val catalogHrn = HRN("hrn:here:data::olp-here:olp-sdii-sample-berlin-2")
val layerId = "sample-index-layer"
val bbNorth = 52.7
val bbSouth = 52.3
val bbEast = 13.8
val bbWest = 13.1
val indexLayerQueryString =
s"tileId=INBOUNDINGBOX=($bbNorth, $bbSouth, $bbEast, $bbWest)"
val sdiiDF = spark.
readIndexLayer(catalogHrn, layerId).
format("parquet").
index(query=indexLayerQueryString).
load()
次のようなエラーが表示されます。
java.lang.NoSuchMethodError: org.apache.spark.sql.execution.datasources.DataSource$.lookupDataSource(Ljava/lang/String;)Ljava/lang/Class;
HERE Data クライアントライブラリでの寄木細工の読み取りに関連する問題が原因です。
回避策は、 OLP ファイルシステムを直接使用することです。 これは同じ例ですが、ファイルシステムを使用しています。
%%spark
import com.here.hrn.HRN
val catalogHrn = HRN("hrn:here:data::olp-here:olp-sdii-sample-berlin-2")
val layerId = "sample-index-layer"
val bbNorth = 52.7
val bbSouth = 52.3
val bbEast = 13.8
val bbWest = 13.1
val indexLayerQueryString =
s"tile_id=INBOUNDINGBOX=($bbNorth, $bbSouth, $bbEast, $bbWest)"
val parquetLayer = spark.read.parquet(s"olp://$catalogHrn/$layerId/index/${indexLayerQueryString}")
EMR の問題
EMR の問題は、通常、 Amazon で作成されたリソースおよびローカルのテラフォーム状態に関連しています。
EMR クラスタ状態の待機中にエラーが発生しました
クラスタの状態に関連して展開が失敗することがあります。
症状 :
Error: Error applying plan:
1 error(s) occurred:
* aws_emr_cluster.spark-emr-lab: 1 error(s) occurred:
* aws_emr_cluster.spark-emr-lab: Error waiting for EMR Cluster state to be "WAITING" or "RUNNING": TERMINATED_WITH_ERRORS: VALIDATION_ERROR: The VPC/subnet configuration was invalid: No route to any external sources detected in Route Table for Subnet: subnet-00cd6179487d7aa83 for VPC: vpc-0d6c6ceeabdc0908a
Terraform does not automatically rollback in the face of errors. Instead, your Terraform state file has been partially updated with any resources that successfully completed. Please address the error above and apply again to incrementally change your infrastructure.
考えられる原因 : 現在、根本的な原因は不明です。この問題が発生する状況は、ローカルマシンと AWS 間の接続の問題の可能性を示唆しています。
解決策 : emr-provision 変更せずにコマンドを再度呼び出すだけです
S3 バケット作成中にエラーが発生しました
環境を継続的に展開および破棄する場合、 S3 バケットを作成できなかったことを示す展開が失敗することがあります。
症状 :
Error: Error applying plan:
2 error(s) occurred: * aws_s3_bucket.spark-emrlab-bucket: 1 error(s) occurred:
* aws_s3_bucket.spark-emrlab-bucket: Error creating S3 bucket: Error creating S3 bucket spark-emrlab-bucket-castilla, retrying: OperationAborted: A conflicting conditional operation is currently in progress against this resource. Please try again. status code: 409, request id: C9A8FD78A01B7DEE, host id: dr+uOt5aKAdg1/56aBuZwTPDTvw1dw8mWrZi+elmiROol0znbypTIU0tOt9LabsQpfoZAhuMvro=
* aws_emr_cluster.spark-emr-lab: 1 error(s) occurred: * aws_emr_cluster.spark-emr-lab: Error waiting for EMR Cluster state to be "WAITING" or "RUNNING": TERMINATING: BOOTSTRAP_FAILURE: Master instance (i-0403cc5aace11a13a) failed attempting to download bootstrap action 1 file from S3
Terraform does not automatically rollback in the face of errors. Instead, your Terraform state file has been partially updated with any resources that successfully completed. Please address the error above and apply again to incrementally change your infrastructure.
考えられる原因 : プロビジョニング / プロビジョニング解除を繰り返し呼び出すと、 AWS に対する一部のリクエスト(特にバケット s3 のリクエスト)がキューに入れられ、完了までに時間がかかることがあります。
解決策 : しばらくお待ちいただくか ( 最大 2 時間 ) 、使用している名前のサフィックスを変更することで、さまざまなリソースを作成できます。 最終的に、以前のリソースが削除されます。
VPC を破棄できませんでした
環境を破棄しても、 VPC は破棄されません。
症状 :
Error: Error applying plan:
1 error(s) occurred:
* aws_vpc.spark-emr-main (destroy): 1 error(s) occurred:
* aws_vpc.spark-emr-main: DependencyViolation: The vpc 'vpc-03745a66e683ce814' has dependencies and cannot be deleted.
status code: 400, request id: 7151dc40-0553-454b-880f-373d3da96e6b
Terraform does not automatically rollback in the face of errors.
Instead, your Terraform state file has been partially updated with
any resources that successfully completed. Please address the error
above and apply again to incrementally change your infrastructure.
考えられる原因 :
Amazon でいずれかのテラフォームリソースが手動または自動で他のシステムによって変更された場合、ローカルおよびリモートの状態が同期されなくなり、テラフォームによるリソースの削除が防止されます。 VPC にセキュリティグループを手動で追加するなどの変更が、この問題の一般的な原因となります。
解決策 :
- AWS Web コンソールに移動し、エラーが表示された後で VPC を手動で削除するか、追加のリソースを探して手動で削除します
- プロビジョニング解除スクリプトを呼び出します
VPC を手動で削除する方法:
- AWS Web コンソールにログインします。
- [ サービス ] 、 [VPC] 、 [VPC] の順に移動します。
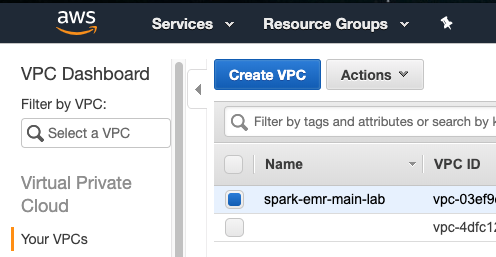
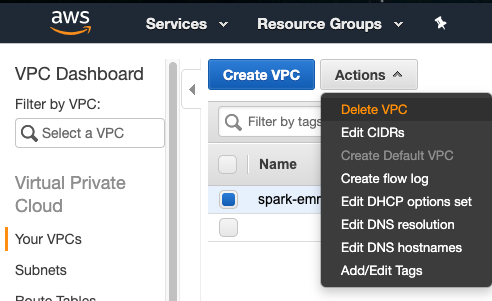
- 入力したサフィックスで終わる名前の vPC を確認してください。
- [ アクション ] をクリックし、 [VPC の削除 ] をクリックします。
IAM インスタンスプロファイルのエラー
IAM インスタンスプロファイルがすでに存在するため、作成できないことを示す新しい環境の展開に失敗しました。
症状 :
Error: Error applying plan:
1 error(s) occurred:
* aws_iam_instance_profile.spark-emr_profile: 1 error(s) occurred:
* aws_iam_instance_profile.spark-emr_profile: Error creating IAM instance profile spark-emr_profile-lab: EntityAlreadyExists: Instance Profile spark-emr_profile-lab already exists.
status code: 409, request id: 77f84a10-7288-11e9-8338-15cce7c2336c
Terraform does not automatically rollback in the face of errors.
Instead, your Terraform state file has been partially updated with
any resources that successfully completed. Please address the error
above and apply again to incrementally change your infrastructure.
考えられる原因 :
- 以前のプロビジョニングが失敗し、ローカルのテラフォーム状態が回復した場合
- 以前のプロビジョニング解除でリソースの削除に失敗した場合
解決策 : AWS コンソールからリソースを手動で削除する必要があります。
- destroy スクリプトを呼び出します。
- AWS Web コンソールに移動します
- [ サービス ] -> [iAM] -> [ 役割 ] の順に移動します。

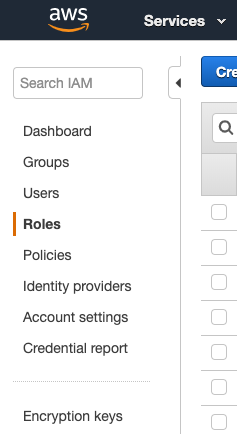
- テキストボックスで「 Spark 」を検索します。
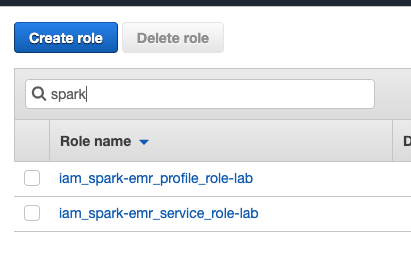
- 画像に似た名前の画像を削除します。
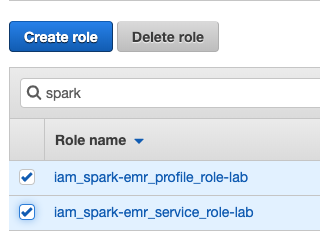
- 配布スクリプトをもう一度呼び出します。
AWS Web コンソールでは、役割に関連付けられていない限りインスタンスプロファイルが表示されないので、 awscli でインスタンスプロファイルを削除する方が信頼性が高くなります。
aws iam list-instance-profiles | grep spark-emr_profileaws iam delete-instance-profile --instance-profile-name <profile name from step #1>
NAT ゲートウェイの作成で問題が発生しました
場合によっては、 NAT ゲートウェイの作成に失敗することがあります。
症状 :
Error: Error applying plan:
1 error(s) occurred:
* aws_nat_gateway.spark-emr-nat-gw: 1 error(s) occurred:
* aws_nat_gateway.spark-emr-nat-gw: Error waiting for NAT Gateway (nat-003ec858485ccadff) to become available: unexpected state 'failed', wanted target 'available'. last error: %!s(<nil>)
Terraform does not automatically rollback in the face of errors.
Instead, your Terraform state file has been partially updated with
any resources that successfully completed. Please address the error
above and apply again to incrementally change your infrastructure.
考えられる原因
- AWS との接続の問題
- 不明 - 確定的ではありません
解決策 :
- 実行します
emr-deprovision - 実行します
emr-provision
HERE Data SDK for Python-Core の問題
GDAL のため、 Windows で Pip を使用してインストール中にエラーが発生しました
Windows で GDAL または geopandas に関連するエラーが表示された場合は、次の手順に従います。
提案された HERE として、 GDAL 、 Fiona 、 Rasterio および shapely のための車輪をダウンロードしなさい。 ご使用のアーキテクチャ( 64 ビット)および Python バージョンに一致する wheel ファイルを選択してください。 これらの 4 つのパッケージの説明に、 Gohlke が前提条件を記述した場合は、ここで前提条件をインストールします ( C++ の再配布可能ファイルまたは類似のものが一覧表示されている可能性があります ) 。
コマンドプロンプトを開き、これらの 4 つのホイールをダウンロードしたフォルダにディレクトリを変更します。
ターミナルで、次のサンプルコマンドを実行して、 wheel ファイルを使用して 4 つのパッケージを (GDAL 、 Fiona 、 rasterio 、 shapely) の順にインストールします。
pip install GDAL‑3.1.2‑cp37‑cp37m‑win_amd64.whl
4 輪すべてのパッケージをインストールした後、次のコマンドを使用してコアモジュールのインストールを再試行します。
pip install --extra-index-url https://repo.platform.here.com/artifactory/api/pypi/analytics-pypi/simple/ here-nagini==1.12新しい問題を作成します
問題が報告されない場合は、カスタマー サポートに連絡してください。
問題の説明にある次のコマンドの出力をコピーして貼り付けます。
conda infoconda env listwhich python