- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
Spark with HERE Data SDK for Python ( 廃止 )
Data SDK for Python with Spark は、 Spark を使用してプラットフォームデータの大規模な分析を行ったり、パイプラインにソリューションを実装したいと考えており、同じ言語 / フレームワークを使用して展開を簡素化したいと考えているデータ科学者を対象としたツールです プロダクションに移行します。
SDK は、ローカルモードまたはクラスタモードで Spark で Spark ジョブを実行するために、 Jupyter の Sparkmagic 拡張機能を使用します。
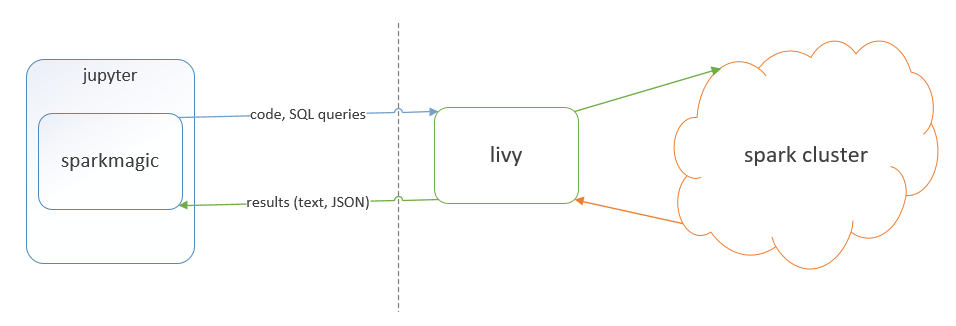
Data SDK for Python with Spark HERE をインストールして設定する手順について説明します。
前提条件
インストール
Data SDK for Python with Local Spark は、 Linux/MacOS でのみ動作します。 EMR Spark クラスタオプションは、すべてのプラットフォームで使用できます。 SDK を設定するには、次の手順を実行します。
- Sparkmagic 拡張機能をインストールして設定します。
- 必要な Livy Server の展開を選択します。
- ローカル Spark (Linux/MacOS のみ ): Hadoop 、 Spark 、および Livy をローカルでインストールおよび展開する方法について説明します。 これは最も簡単でデフォルトのオプションです。
- EMR Spark クラスタ (オプション): でジョブを実行する場合は、リモートの EMR クラスタの展開および接続方法を参照してください。