- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
Adaptive Leveling
Geographically-distributed content such as road networks, POIs, buildings and houses, is by nature not uniformly distributed across the globe. Cities tend to have a higher concentration of geodata, rural areas tend to have sparse geodata, seas and oceans are typically empty.
This unbalance is expected because the content is distributed in this way in reality, relatively constant over time. However, this unbalance does cause some challenges with data processing and data consumption.
The main issue for datasets partitioned geographically in tiles is that some tiles tend to contain too much content, while other tiles tend to be almost empty. No matter at which level the tiling grid is defined, there are either too many tiles, a majority of them small in size, or too few tiles, with a minority of them resulting too big in size.
Too many small tiles result in a high overhead in data processing and consumption, compared to the amount of data processed or consumed.
Fewer, bigger tiles result in peaks of resource consumption, that in turn leads to pipelines running out of memory when processing tiles that contain too much content, or to unacceptable delays when consuming such tiles in an interactive application.
There is no "one size fits all" solution, when tile leveling is fixed.
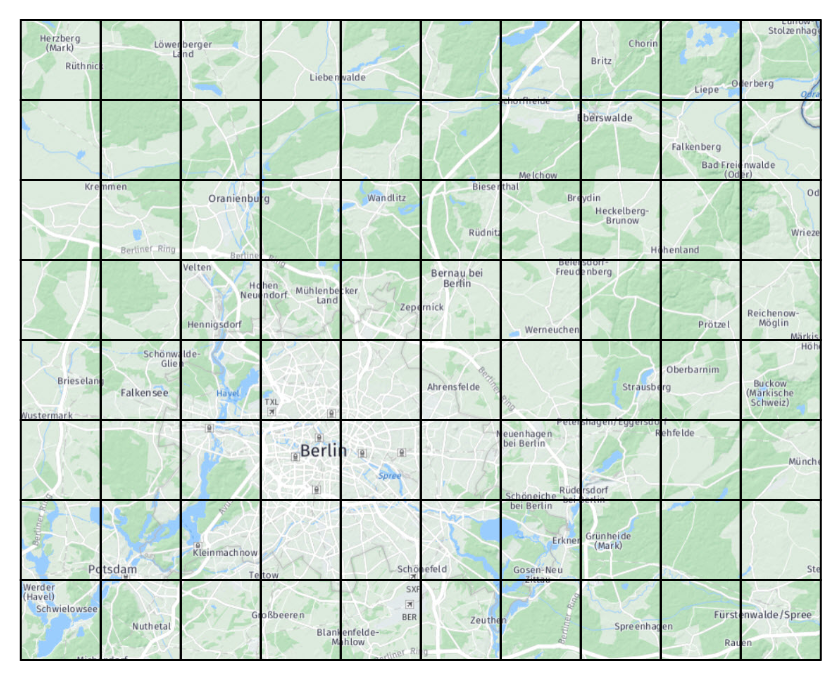
Adaptive leveling is a solution to overcome the limitation of choosing just one tile size. It is based on the concept of AdaptivePattern, that describes the geographical density of some content. In areas where content is sparse, a lower tile level is used. In areas where content is dense, a higher tile level is used. An AdaptivePattern is estimated by the AdaptivePatternEstimator algorithm provided in the library.
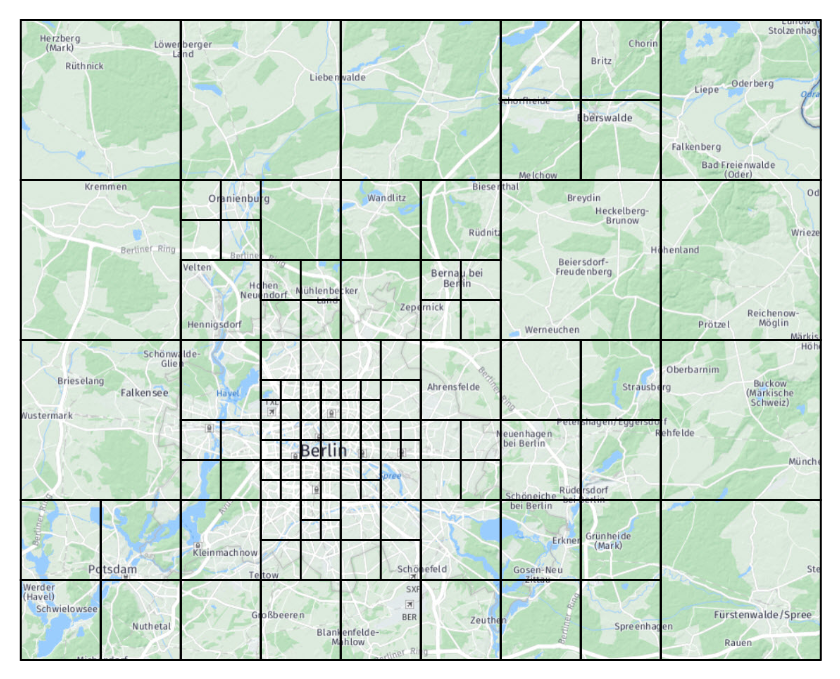
For comparison, a FixedPattern is also present to represent the logic of distributing tiles at a fixed level. As both classes share a common parent Pattern, you can easily switch from one pattern to the other.
Estimating an Adaptive Pattern
The class AdaptivePatternEstimator calculates an adaptive pattern.
You must run this algorithm before the main processing takes place, as the resulting pattern is to be used in the subsequent processing steps. The recommended place to plug this logic is where the Driver is configured using the DriverBuilder, as shown in the examples below. A Java version exists as part of the Java bindings, as for the other classes mentioned in this chapter.
The estimator requires you to provide an implementation for the AdaptivePatternEstimateFn interface. Similar to functional compilation patterns, you need to specify which input layers to take into account for the pattern estimation. The AdaptivePatternEstimator needs this information to query the input catalog(s), call the estimateFn for each input partition of the layer(s) specified, and then aggregate the result in an AdaptivePattern instance. Whether or not DriverTasks run incrementally, if you integrate the AdaptivePattern this way, pattern estimation is run at every compilation.
Weights
The estimation algorithm evaluates an estimateFn for each input partition involved. These can be both types of partition, usually HERE Tile, but Generic partitions may be used as estimation input as well. Additionally, metadata are also provided to the estimateFn function.
With the estimateFn you describe the density of data by returning a collection of HERE tile IDs and weights. You tell the estimator how dense or heavy, some geographic locations are. In case different calls to estimateFn return the same HERE Tile ID, their weights are summed up. Tile IDs produced by the estimate function may have any level.
The semantics of the weights is not fixed. You may store any value of your choice in the weights, as long as it's greater than zero. You may store the size of the input data, taken from the metadata, but you can also use more complex schemes as illustrated in the examples below. It is also possible to fetch the input payloads using a Retriever, inspect the content, and use that content to define the weights. For example returning the number of routing graph nodes, or the number of POIs or roads. However this pattern is not recommended because the estimation process is run from scratch at every job, which means that the entire input content needs to be fetched for each run. Consequently, this is not a good approach unless you have small layers for pattern estimation. Often, just using the metadata's size provides sufficient results. Nevertheless, you can use estimation functions that retrieve the payloads.
An example implementation of AdaptivePatternEstimateFn:
class MyEstimateFn extends AdaptivePatternEstimateFn {
override def inLayers: Map[Catalog.Id, Set[Layer.Id]] = {
// These are the catalog and layers that contribute to the estimation
Map(
Ids.RoadCatalog -> Set(Ids.RoadJunctions, Ids.RoadGeometries),
Ids.ExtraCatalog -> Set(Ids.ExtraContent)
)
}
override def inPartitioner(parallelism: Int): Option[Partitioner[InKey]] = {
// There is in general no need to dictate which Spark partitioner the
// AdaptivePatternEstimator has to use for its internal operations,
// so we return None here, but this possibility is not prevented.
None
}
override def estimateFn(src: (InKey, InMeta)): Iterable[(HereTile, Long)] = {
// The assumption made in this example is the average density of data
// is function of what is present in 3 layers of 2 input catalogs
// and somehow proportional to the sizes of the payloads of that layers.
// The road catalog, that contains road junctions and geometries,
// and an extra catalog, that contains additional tiled content.
// The weight of the road junction is 5 times the one of the geometry,
// while the weight of the extra content is twice the one of the geometry.
// The storage level of the 3 input layers is assumed to be the same.
src match {
case (InKey(Ids.RoadCatalog, Ids.RoadJunctions, tile: HereTile),
InMeta(_, _, _, Some(size))) =>
List(tile -> size * 5)
case (InKey(Ids.RoadCatalog, Ids.RoadGeometries, tile: HereTile),
InMeta(_, _, _, Some(size))) =>
List(tile -> size)
case (InKey(Ids.ExtraCatalog, Ids.ExtraContent, tile: HereTile),
InMeta(_, _, _, Some(size))) =>
List(tile -> size * 2)
}
}
}
Threshold
The weights are aggregated into an AdaptivePattern given a threshold, that you have to provide to the AdaptivePatternEstimator. The semantics of the threshold follows the semantics you have decided to give to the weights, as these must be comparable.
Weights are aggregated in such a way that the total weight of an aggregated tile must not exceed the given threshold. This total weight is defined as the estimated weight of the tile itself, including the weight of its children and grandchildren.
Whenever possible, the calculated AdaptivePattern maps each tile to its aggregation target, which is its parent at the lowest level that does not exceed the threshold. If tiles weigh more than the threshold they can't be aggregated and are left unmapped. This also applies to unexpected tiles, which are tiles that were not provided when the pattern was initially estimated. In such cases, the pattern mapping function returns None.
For example, given the following tiles and weights produced by the estimateFn:
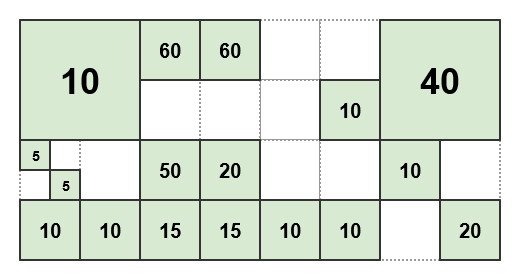
if the threshold is set to 50, the resulting pattern is as follows:
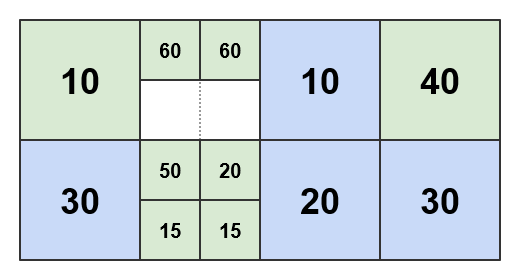
The AdaptivePattern contains only the blue tiles, without the weights, illustrated in the diagram together with some of the estimation input just for completeness and clarity. When a tile is mapped through the pattern, one of the four blue tiles is returned if the tile to be mapped is one of its children or grand-children; otherwise it is left unmapped.
If the threshold is set to 100, the resulting pattern is as follows:
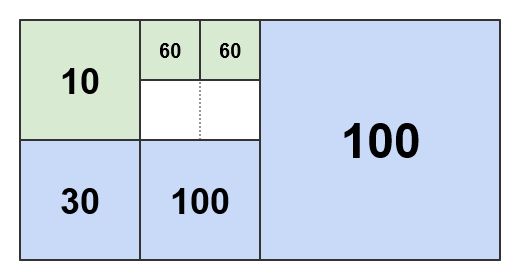
A higher threshold determines aggregation tiles at a lower level. Aggregation tends to be more aggressive since there's more weight budget for it.
Below are the patterns calculated using a threshold of 200 and 300 respectively:
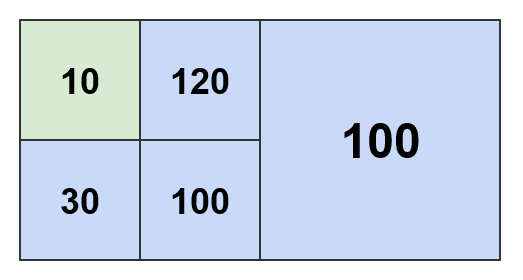
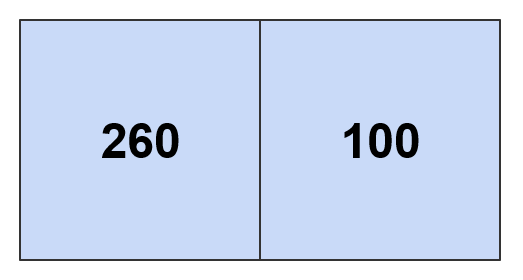
When using a threshold of 360 or higher, the whole estimated density map collapses to an AdaptivePattern that contains only the world root tile.
Spark Partitions Based on Content Density
A key use case that AdaptivePattern enables is defining Spark partitions based on the density of data. Given weights and a threshold, using the pattern to implement a Spark Partitioner results in a dynamic number of partitions, each defined in a way that does not exceed the threshold.
The AdaptivePattern is used to balance the sizes of Spark partitions to obtain a more even, uniformed distribution of content inside them. A good balance is necessary to avoid cases where the partitions are too heavy to process, or there are too many light partitions. As a result, the processing becomes smoother and cluster resources are utilized better, all without affecting the output.
AdaptivePattern is a great helper when you are tuning resources that are allocated for large jobs as it can prevent the processing from running out of memory as the memory consumption per Spark partition is better allocated.
AdaptiveLevelingPartitioner is the Spark partitioner that implements this logic. It can be employed by setting up the Driver as shown in the following example:
def configureCompiler(completeConfig: CompleteConfig,
context: DriverContext,
builder: DriverBuilder): builder.type = {
// We define our own estimate function and run it as preliminary step
// to calculate an adaptive pattern and use it to obtain a partitioner.
// The threshold is in the same units returned by the estimate function,
// that are related to the size in bytes, so we ask the estimator
// to define a pattern and have Spark partitions of a max size of 100 MB.
val myEstimateFn = new MyEstimateFn
val estimator = new AdaptivePatternEstimator(myEstimateFn, context)
// we use a NameHashPartitioner for partitions that are not aggregated
val fallbackPartitioner = NameHashPartitioner(context.spark.defaultParallelism)
val partitioner = estimator.partitioner(100 * 1024 * 1024, Some(fallbackPartitioner))
// The partitioner is passed to the compiler, that uses it to implement
// the inPartitioner and outPartitioner methods, ignoring the static parallelism
val myCompiler = new MyCompilerWithPartitioner(partitioner)
// Add the compiler to the Driver as new DriverTask
builder.addTask(builder.newTaskBuilder("compiler").withMapGroupCompiler(myCompiler).build())
}
The pattern is calculated when configuring the Driver and passed to the example compiler.
class MyCompilerWithPartitioner(partitioner: AdaptiveLevelingPartitioner)
extends MapGroupCompiler[Intermediate]
with CompileOut1To1Fn[Intermediate]
The compiler uses it to implement the methods that define the partitioners.
def inPartitioner(parallelism: Int): Option[Partitioner[InKey]] = {
// parallelism is provided for convenience. In this case the partitioner
// has been already initialized: in an adaptive partitioner, the number
// of partitions is function of the weights and the threshold plus the
// parallelism of the fallback partitioner (if specified).
Some(partitioner)
}
def outPartitioner(parallelism: Int): Option[Partitioner[OutKey]] = {
// The output partitioner doesn't have to be the same
// as the input partitioner, but in this example it is.
Some(partitioner)
}
The pattern is recalculated at every run. Any eventual changes to the AdaptivePattern due to changes in the data used to estimate the pattern do not prevent incremental compilation. This is because Spark partitioners affect only the runtime performances of Spark but not the actual output catalog. Therefore it is not necessary to disable incremental compilation for the current run.
Level of Output Layers Based on Content Density
Another key use case that AdaptivePattern enables is enabling smarter compilers that output layers with a variable level, based on the density of the data.
Layers produced this way are characterized by larger tiles, at a lower level, in geographic areas where the content is sparse and smaller tiles, at a higher level, in areas where the content is dense.
This solution provides the following benefits:
- sizes of the output tiles are more uniform and distributed closer to the average size
- extremes such as few tiles that are too big or too many small tiles are avoided
- download times are more uniform and predictable, especially for interactive applications
To enable this feature, set up the Driver so that the AdaptivePattern can be estimated and employed as shown in the following example:
def configureCompiler(completeConfig: CompleteConfig,
context: DriverContext,
builder: DriverBuilder): builder.type = {
// We define our own estimate function and run it as preliminary step
// to calculate an adaptive pattern and use it to model the output layer.
// The threshold is in the same units returned by the estimate function,
// that are related to the size in bytes, so we ask the estimator
// to define a pattern and have Spark partitions of a max size of 100 MB.
val myEstimateFn = new MyEstimateFn
val estimator = new AdaptivePatternEstimator(myEstimateFn, context)
val pattern = estimator.adaptivePattern(100 * 1024 * 1024)
// The pattern is passed to the compiler that uses it to implement
// its compileIn function. Other examples may use it differently.
// Note the pattern is in a broadcast variable registered in fingerprints.
val myCompiler = new MyCompilerWithPattern(pattern)
// Add the compiler to the Driver as new DriverTask
builder.addTask(builder.newTaskBuilder("compiler").withMapGroupCompiler(myCompiler).build())
}
The AdaptivePatternEstimator returns a Broadcast variable containing the AdaptivePattern. This object is passed to the example compiler. For better performance and improved resource consumption, the Broadcast variable should be passed unchanged to the constructor.
class MyCompilerWithPattern(pattern: Broadcast[AdaptivePattern])
extends MapGroupCompiler[Intermediate]
with CompileOut1To1Fn[Intermediate]
In this example, the compiler defines the input and output layers as usual.
def inLayers: Map[Catalog.Id, Set[Layer.Id]] = Map(
Ids.RoadCatalog -> Set(Ids.RoadJunctions, Ids.RoadGeometries)
)
def outLayers: Set[Layer.Id] = Set(Ids.OutRendering, Ids.OutRouting)
The AdaptivePattern is used in compileInFn to map input tiles to output tiles at a variable level. See the .value method to access the pattern inside the Broadcast.
def compileInFn(in: (InKey, InMeta)): Iterable[(OutKey, Intermediate)] = {
// In this example we assume input tiles from the road catalog
// are to be mapped to variable-level output layers
// using the pattern passed in the constructor.
// Objects from the geometries layer must be decoded in roads
// and provided to both rendering and routing output layers.
// Objects from the junction layer must be decoded and
// provided to only the output routing layer (just an example).
in match {
case (InKey(Ids.RoadCatalog, Ids.RoadGeometries, tile: HereTile), meta) =>
// The leveling target should be defined for every input
val outTile = pattern.value.levelingTargetFor(tile).get
val payload: Payload = ??? /* retrieve and decode the payload */
val roads
: Set[Road] = ??? /* prepare the roads for the output routing and rendering layers */
val intermediate = Intermediate(roads, Set.empty)
List(
// outTile is used for both, but it is not a hard requirement
(OutKey(Default.OutCatalogId, Ids.OutRouting, outTile), intermediate),
(OutKey(Default.OutCatalogId, Ids.OutRendering, outTile), intermediate)
)
case (InKey(Ids.RoadCatalog, Ids.RoadJunctions, tile: HereTile), meta) =>
// The leveling target should be defined for every input
val outTile = pattern.value.levelingTargetFor(tile).get
val payload: Payload = ??? /* retrieve and decode the payload */
val junctions: Set[Junction] = ??? /* prepare the junctions for the output routing layer */
val intermediate = Intermediate(Set.empty, junctions)
List(
(OutKey(Default.OutCatalogId, Ids.OutRouting, outTile), intermediate)
)
case _ =>
sys.error("Unexpected input key")
}
}
The compileOutFn does not need to be aware of the adaptive leveling, as it processes keys and intermediate data as established by the compileInFn.
def compileOutFn(outKey: OutKey, intermediate: Iterable[Intermediate]): Option[Payload] =
outKey match {
case OutKey(Default.OutCatalogId, Ids.OutRendering, _) =>
val roads: Set[Road] = intermediate.flatMap(_.roads)(collection.breakOut)
val payload: Payload = ??? /* process the roads and encode the result */
Some(payload)
case OutKey(Default.OutCatalogId, Ids.OutRouting, _) =>
val junctions: Set[Junction] = intermediate.flatMap(_.junctions)(collection.breakOut)
val payload: Payload = ??? /* process the junctions and encode the result */
Some(payload)
case _ =>
sys.error("Unexpected output key")
}
The pattern is recalculated at every run. In this second use case, however, any eventual changes to the AdaptivePattern due to changes in the data used to estimate the pattern do prevent incremental compilation. This is because the pattern actively defines the output catalog. To prevent a corrupted output, the pattern is returned inside a Broadcast variable to be used by compiler implementations. Changes to any Broadcast variable of this kind inhibit incremental compilation for the current run.
This limitation does not apply if the data used to estimate the pattern changes in such a way that the average weight distribution and the resulting pattern is not affected.