- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
Pipelines and the Data Processing Library
Pipeline is the main abstraction to define, implement and deploy data processing algorithms and custom logic on the HERE platform.
A PipelineTemplate is a reusable definition of a Pipeline, that includes the implementation and all the information needed to make it runnable, such as:
- the entry point, which is the name of the main class
- the definition and schema of the input and output catalogs which the implementation needs to be connected to
- the type of runtime required
- the default configuration and parameters
A Pipeline is instantiated by the Pipeline API for a given PipelineTemplate.
Pipelines are deployed on runtime environments dynamically provided by the HERE Workspace and are connected to their input and output catalogs. Pipelines automatically receive the credentials from the Pipeline API to authenticate to other platform services, such as the Data API, the configuration, HRNs for each of the expected input and output catalogs and the job description, when applicable.
The Pipeline API supports runtime environments based on Apache Flink and Apache Spark.
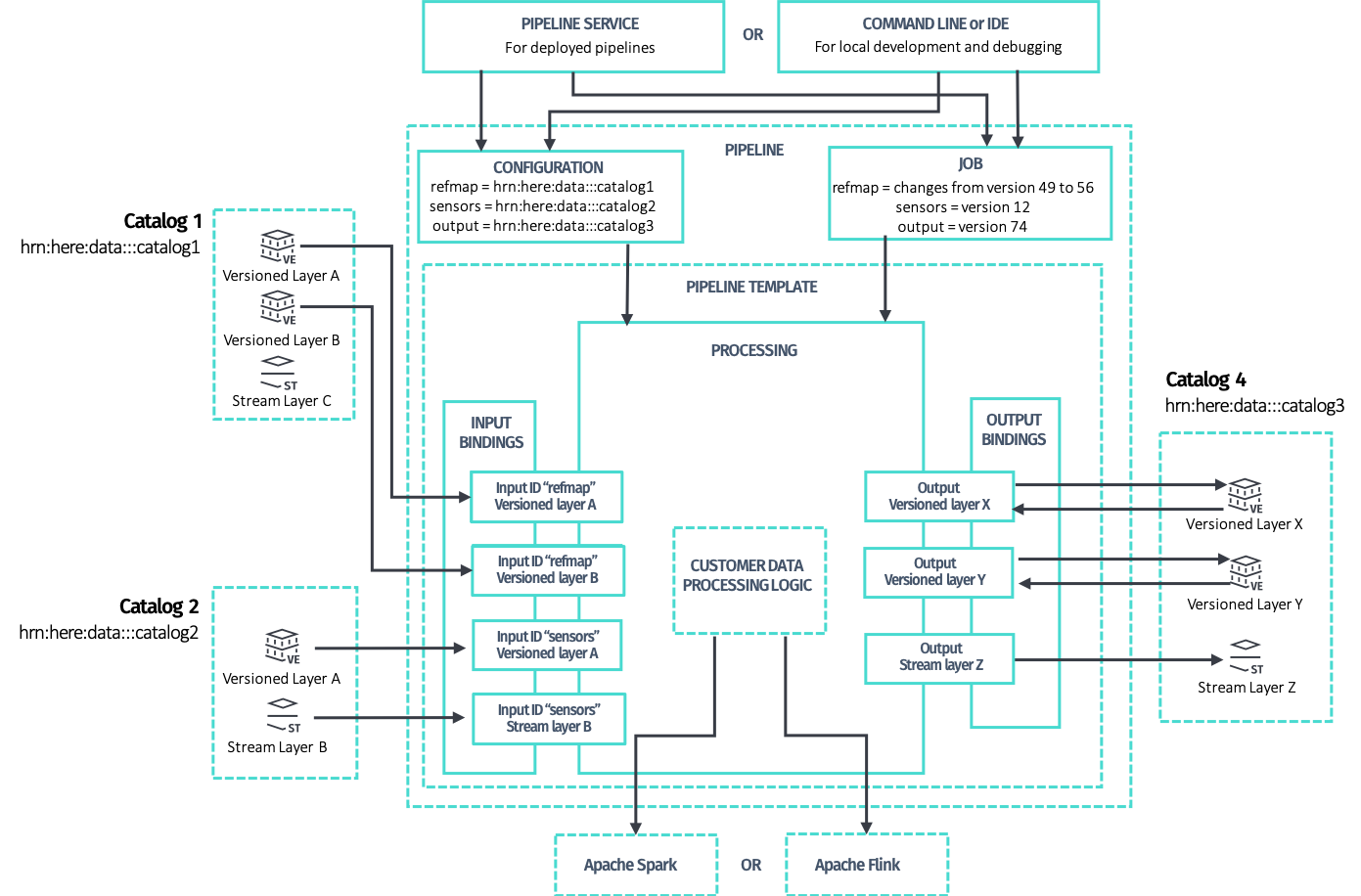
A pipeline implementation assumes the existence of only one output catalog and one or more input catalogs. Each input catalog is marked by a symbolic, implementation-specific ID used in the code to differentiate between multiple inputs. The implementation also implicitly assumes the list and type of the layers for each catalog, as the code contains logic to read and write to specific layers.
Layers can be of different types:
-
versionedlayers contain partitioned data; the Data API keeps track of how each partition evolves over time. A typical use case of versioned layers is to store a snapshot of a dataset, usually map data, that is updated from time to time. -
streamlayers contain live data streams; the Data API exposes streams as message queues. A typical use case for stream layers is to report events or sensor readings from vehicles, IoT devices, or other web events and services. -
volatilelayers contain data similar to versioned layers, but the content of each partition may change without producing an additional version. A typical use case for volatile layers is to produce data that varies rapidly over time, obsoletes quickly, in an efficient way. For example, traffic data.
When run locally or deployed on the platform pipeline, HRNs of each input and output catalog are provided and the process binds to the actual data instances. This makes the implementation, and so the pipeline template, reusable.
For more information on pipelines, how they are deployed on the HERE platform, different types of pipelines and runtime environments, how pipelines are connected together to form topologies, see the Developer's Guide of the Pipeline API.
The Data Processing Library provides abstractions and libraries to implement pipelines.