- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
RDD-based Patterns
Despite being more cumbersome to implement, RDD-based patterns provide more freedom, such as the freedom to implement the actual business logic that leverages Spark operations: joining, filtering, mapping, and so on. These operations not only reduce the metadata, but the actual data as well.
Functional patterns use Spark to parallelize the function applications, but these functions cannot see the RDDs. In contrast, RDD-based patterns have RDDs as parameters and return values for the interfaces that should be implemented.
However, there is one important drawback: compiler implementations must actively support incremental compilation. This means that this key Data Processing Library feature is not fully transparent: compilers shall cooperate and return additional RDDs that contain the information requested by each pattern for the compiler to complete the job and support incremental processing properly. Failing to do so, or returning an RDD that does not follow what the pattern specification expects, results in invalid maps being produced when the compiler is run incrementally.
The expected content of the RDD that your functions should return is described in the sections detail below.
The following RDD-based patterns are available:
NonIncrementalCompiler
This pattern provides maximum freedom to developers: Spark is directly accessible from the input data RDD. Developers can implement any sort of compilation to return an RDD of the payloads that have to be published. However, this pattern does not support incremental compilation.
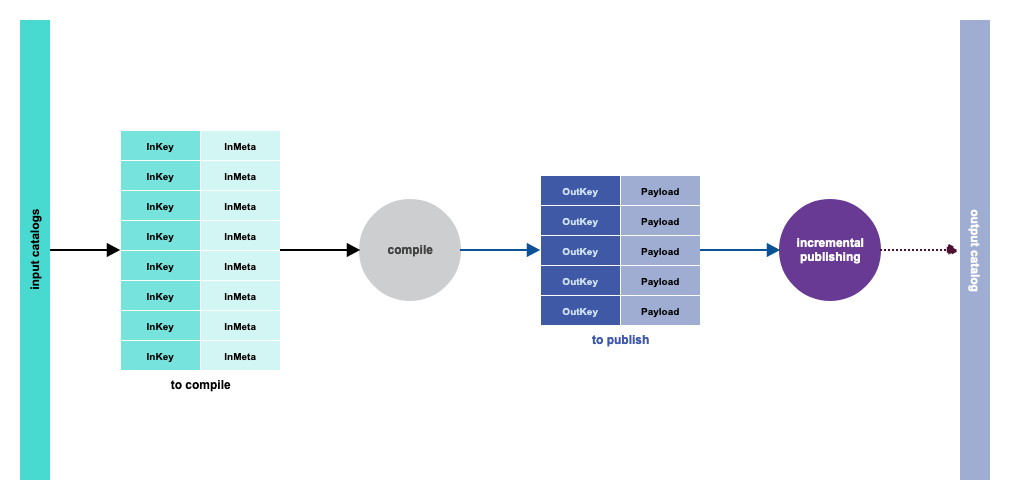
This is the most general compilation pattern, and has no specific applicability restrictions.
Typical Use Cases
All cases where the developer wants to freely implement a compiler in terms of Spark transformations.
High-level Interface
There is no front-end and back-end distinction. The only function to be implemented is:
- compile(toCompile: RDD[(InKey, InMeta)]) ⇒ RDD[(OutKey, Option[Payload])]
Runtime Characteristics
The compiler is stateless. State is not present as no incremental compilation is supported in this pattern, by design.
References
-
TaskBuilder:withNonIncrementalCompilermethod -
NonIncrementalCompiler: main interface to implement
DepCompiler and IncrementalDepCompiler
These compilation patterns implement a map-reduce compilation, where the reduce function does not actually reduce anything, but simply groups the elements with the same key. This pattern is equivalent to the MapGroup functional compiler.
These two patterns are equivalent. IncrementalDepCompiler is a specialization of DepCompiler and adds additional logic for a more efficient incremental compilation.
This compilation pattern can be used for all cases of MapGroupCompiler.
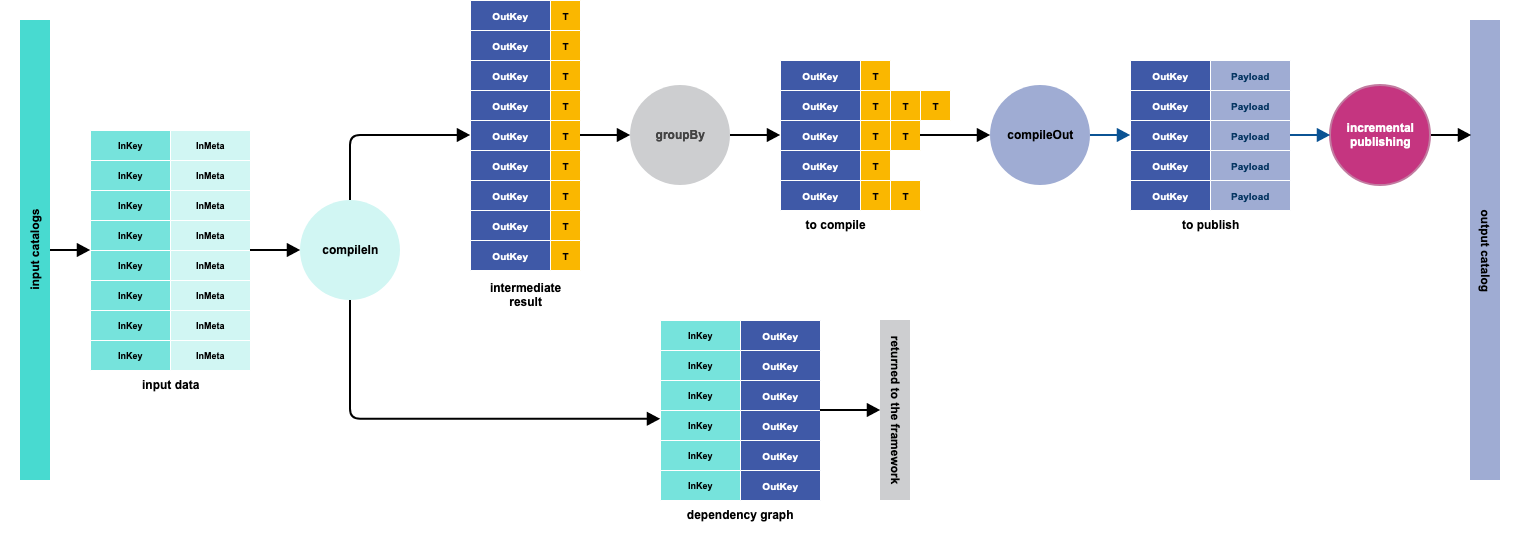
DepCompiler Logic
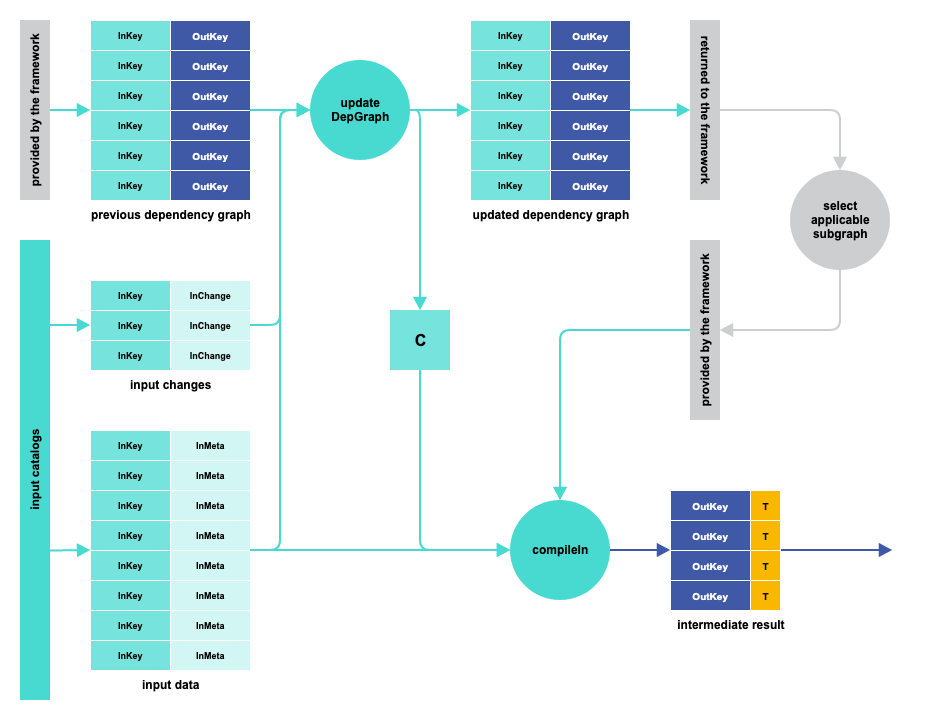
Additional Logic Introduced with IncrementalDepCompiler
Typical Use Cases
Use this pattern in cases where the transformation takes into account the input content, such as:
- Decoding input partitions and distributing content among different output partitions or as a function of the content.
- Creating output layers with a subset of input data.
- Distributing objects from input layers to output layers, shifting levels up or down, or as a function of object properties.
- Indexing of content, for example by country or by tile.
High-level Interface
T and C are developer-defined types. The dependency graph or its subsets have the form of RDD[(InKey, OutKey)].
CompileIn (non-incremental compiler front-end):
- compileIn(inData: RDD[(InKey, InMeta)]) ⇒ dependency graph and RDD[(OutKey, T)]
CompileIn (additions to run the front-end incrementally):
- updateDepGraph(inData: RDD[(InKey, InMeta)], inChanges: RDD[(InKey, InChange)], previous dependency graph) ⇒ updated dependency graph and C for next call
compileIn(inData: RDD[(InKey, InMeta)], subset of the dependency graph, C from previous call*) ⇒ RDD[(OutKey, T)]
CompileOut (compiler back-end):
- compileOut(toCompile: RDD[(OutKey, Iterable[T])]) ⇒ RDD[(OutKey, Option[ Payload])]
Runtime Characteristics
Both versions are stateful.
In DepCompiler, compileIn always runs on the whole set of input catalogs, also in incremental mode. compileOut is run incrementally, on the subset of output partitions that the library detects as a candidate for recompilation.
In IncrementalDepCompiler, compileIn (1st version) runs on the whole set of input catalogs for the non-incremental case. In the incremental case, updateDepGraph and compileIn (2nd version) run instead. Access is provided to both the overall data and the changes. compileOut, as in the previous case, runs only on a subset of output partitions.
References
-
TaskBuilder:withDepCompilerandwithIncrementalDepCompilermethods -
DepCompiler: main interface to implement (non-incremental front-end, incremental back-end) -
IncrementalDepCompiler: main interface to implement (incremental front-end and back-end