- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
Payloads
The CompileOut of all the functional compilers return the payloads to be published, as described in their signatures.
Usually, the compilation patterns invoke compileOutFn to generate the payload of each OutKey returned by either mappingFn or compileInFn. In this nominal case, compileOutFn returns only one Payload.
Alternatively, you can create and commit multiple output partitions for each OutKey returned by either mappingFn or compileInFn. This is useful when you need to produce multiple layers out of the same intermediate data (T) provided to the compiler back-end. Then, OutKey is not used as the output partition's key and compileOutFn has to return the definitive OutKeys and the corresponding payloads. To this end, the return type is Map[OutKey, Payload].
For this reason, the exact return type of the compileOutFn is not visible in the reference documentation, the interface inherited by all of the functional compiler interfaces described so far.
Instead, the two different behaviors are provided as separate traits and you must explicitly choose the required behavior.
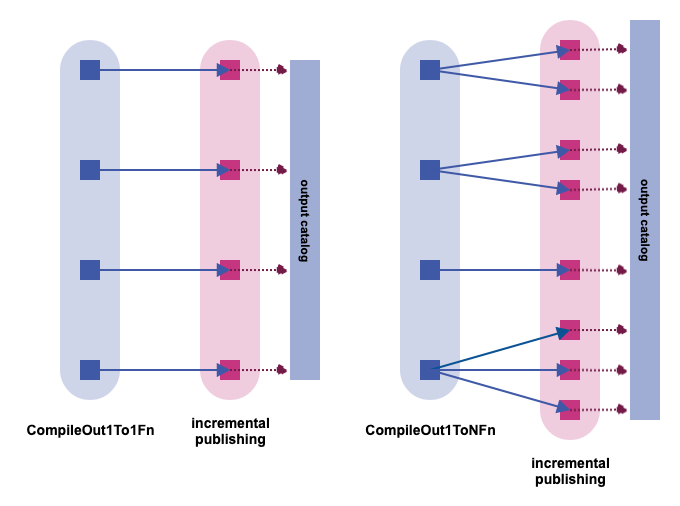
You have to mix in one of the two following traits and implement the exact compileOutFn function declared in it:
-
CompileOut1To1Fn-- the case of one payload per output partition generated by the compiler, which is typically what you need. -
CompileOut1ToNFn-- the case of multiple output partitions and payloads for each output partition generated by the compiler. This method can be useful in cases where thecompileOutFnneeds to produce two or more layers for the same output partition, using the same data, sharing processing code and intermediate data.
Typically, you would always mix in CompileOut1To1Fn. However, if you need a final additional 1:N stage, that stage is appended at the end of compilations in CompileOut1ToNFn. This optional 1:N stage is not an M:N stage, meaning that each actual output partition can be produced by only one nominal output partition. An explicit nominal-to-actual mapping must also be exposed, as required by the interface.
Alternatively, you can also use the CompileOutLayerStackFn trait, which contains simplified signatures and code to build a stack of layers for each nominal output partition. For this specific case, use the CompileOutLayerStackFn in place of CompileOut1ToNFn as it represents the output stack semantic explicitly and provides better guidance.
For more information, see the reference documentation for:
-
CompileOutFn: the abstract base class. -
CompileOut1To1Fn: the classic case of one payload per output partition generated by the compiler, usually the default. -
CompileOut1ToNFn: the case of multiple output partitions and payloads for each output partition generated by the compiler. -
CompileOutLayerStackFn: the specialized 1:N case when output partitions generated by the compiler produce multiple layers with the same partition name, like a stack.
Retrieving Payloads
Patterns don't provide Payloads directly on the interfaces, but always expose the input metadata. You have to retrieve the corresponding data manually when you need it.
The com.here.platform.data.processing.blobstore and com.here.platform.data.processing.java.blobstore packages contain the API to retrieve payloads from the metadata returned by catalog queries. This work is done by the Retriever, and can be obtained from the DriverContext:
Scala
Java
val retriever = driverContext.inRetriever(inputCatalogId)
def compileInFn(in: (InKey, InMeta)): IntermediateData = {
val payload = retriever.getPayload(in.key, in.meta)
new IntermediateData(payload.content)
}Retriever retriever;
public MyCompiler(DriverContext context) {
retriever = context.inRetriever(INPUT_CATALOG_ID);
}
@Override
public IntermediateData compileInFn(Pair<Key, Meta> in) {
Payload payload = retriever.getPayload(in.getKey(), in.getValue());
return new IntermediateData(payload.content());
}Caching Retrieved Payloads
If you have to retrieve the same partition multiple times, consider using a cache as it can result in significant improvement in performance. The Data Processing Library includes caching versions of the Retriever class, com.here.platform.data.processing.blobstore.caching.CachingRetriever and com.here.platform.data.processing.java.blobstore.caching.CachingRetriever, that you can build out of a traditional Retriever:
Scala
Java
// import implicit `caching()`
import com.here.platform.data.processing.blobstore.caching.CachingRetriever._
// equivalent to:
// val retriever = new CachingRetriever(driverContext.inRetrievers(inputCatalogId))
val retriever = driverContext.inRetriever(inputCatalogId).caching()
def compileInFn(in: (InKey, InMeta)): IntermediateData = {
val payload = retriever.getPayload(in.key, in.meta)
new IntermediateData(payload.content)
}Retriever retriever;
public MyCompilerWithCaching(DriverContext context) {
retriever =
new CachingRetriever.Builder(context.inRetriever(INPUT_CATALOG_ID)).build();
}
@Override
public IntermediateData compileInFn(Pair<Key, Meta> in) {
Payload payload = retriever.getPayload(in.getKey(), in.getValue());
return new IntermediateData(payload.content());
}Alternatively, the com.here.platform.data.processing.blobstore.caching.CachingMappingRetriever and com.here.platform.data.processing.java.blobstore.caching.CachingMappingRetriever classes accept a mapping function that can decode the raw payload and cache the decoded partition:
Scala
Java
def parsePayload(key: InKey, payload: Payload): MyDecodedPartition =
MyDecodedPartition.parseFrom(payload.content)
val partitionCache =
new CachingMappingRetriever[MyDecodedPartition](driverContext.inRetriever(inputCatalogId),
parsePayload)
def compileInFn(in: (InKey, InMeta)): IntermediateData = {
val partition = partitionCache.getPayloadAndMap(in.key, in.meta)
new IntermediateData(partition)
}CachingMappingRetriever<MyDecodedPartition> partitionCache;
public MyCompilerWithCachingAndDecoding(DriverContext context) {
Retriever retriever = context.inRetriever(INPUT_CATALOG_ID);
partitionCache =
new CachingMappingRetriever.Builder<>(
retriever, (key, payload) -> MyDecodedPartition.parseFrom(payload.content()))
.build();
}
@Override
public IntermediateData compileInFn(Pair<Key, Meta> in) {
MyDecodedPartition partition = partitionCache.getPayloadAndMap(in.getKey(), in.getValue());
return new IntermediateData(partition);
}You can specify which partitions to cache, by providing a filter function:
Scala
Java
// caches all but one layer
val cachingRetrieverWithFilter = driverContext
.inRetriever(catalogId)
.caching(filter = (key, meta) => key.layer != layerWeDontWantToCache)// caches all but one layer
Retriever cachingRetrieverWithFilter =
new CachingRetriever.Builder(retriever)
.setFilter((key, meta) -> !key.layer().equals(layerWeDontWantToCache))
.build();To monitor a cache's usage statistics, pass the Statistics object which the DriverContext provides to the CachingRetriever and CachingMappingRetriever classes. Specific Spark accumulators are used to store the number of hits and misses:
Scala
Java
// keeps track of cache hits/misses via specific Spark accumulators
val cachingRetrieverWithStats =
driverContext.inRetriever(catalogId).caching(statistics = Some(driverContext.statistics))// keeps track of cache hits/misses via specific Spark accumulators
Retriever cachingRetrieverWithStats =
new CachingRetriever.Builder(retriever).setStatistics(driverContext.statistics()).build();When you use caching within a compiler, enabling keys sorting in the executors configuration may help increasing the cache hit ratio:
here.platform.data-processing.executors {
compilein.sorting = true
compileout.sorting = true
}
Cache Factories
Each caching retriever uses a single cache per Spark node. A cache is built in each node through a factory object that can be passed to the caching retriever's constructor. The factory must return any object that implements the interface com.here.platform.data.processing.utils.cache.Cache or com.here.platform.data.processing.java.utils.cache.Cache. The default implementation when no factory is provided is based on Google Guava. You can use your own custom factory, or customize the built-in factory.
For a complete list of settings, refer to the cacheFactory method in the GuavaCache Scala API and the CacheFactoryBuilder class in the GuavaCache Java API.
Scala
Java
// overrides default cache settings:
// we use a Guava cache with the payload size as weight, a maximum weight (size) of 1 GB, and
// soft references
val cachingRetrieverWithCustomSettings = driverContext
.inRetriever(catalogId)
.caching(
factory = GuavaCache.cacheFactory(weigher = CachingRetriever.payloadSizeWeigher,
maximumWeight = 1048576000L, // 1 GB
softValues = true))// overrides default cache settings:
// we use a Guava cache with the payload size as weight, a maximum weight (size) of 1 GB, and
// soft references
Retriever cachingRetrieverWithCustomSettings =
new CachingRetriever.Builder(retriever)
.setFactory(
new GuavaCache.CacheFactoryBuilder<Pair<Key, Meta>, Payload>()
.setWeigher(CachingRetriever.payloadSizeWeigher())
.setMaximumWeight(1048576000L) // 1 GB
.setSoftValues(true)
.build())
.build();For more information, see the Scala API reference for CachingRetriever and CachingMappingRetriever or the Java API reference for CachingRetriever and CachingMappingRetriever.
Publishing Payloads
Compilers produce a set of output keys with optional Payloads. If a payload is undefined (None), then the corresponding output partition in the output catalog is deleted upon commit.
If a payload is defined, it is uploaded to Data Blob in the output catalog and then committed. Additionally, if that payload is already present with the same content, the upload is skipped.
To implement this check, the output catalog is queried and checksums of previously-published payloads are compared with the checksums of candidate payloads. In the architecture diagrams, this is represented with dotted arrows.
Note
To implement this incremental publishing logic, the Data Processing Library requires the output partitions include a checksum. The library honors the digest algorithm configured for each output layer. However, if the algorithm is not configured, checksums are produced anyway using a default algorithm (MD5).
The library is deterministic; the compilers should also be deterministic. If the compilers are deterministic, then running a compilation with the same input catalogs and versions twice should produce an empty commit the second time. An empty commit updates the output catalog's version and dependencies only.
All these functions are performed by the Publisher component of the library. Invocation of the Publisher is handled by the Driver at the end of each task.
The publisher returns a set of multipart commit part identifiers. The driver then collects the identifiers from all of the tasks and completes the multipart commit by committing all of these parts at once; provided there are no errors.
If an exception is detected, from any of the tasks, consecutive tasks are not run and the multipart commit is aborted.