- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
Functional Patterns
The following functional patterns are available:
All of the classes that implement the functional compiler interfaces described below must be Serializable, as they are serialized and distributed among Spark executors.
Direct 1:N and M:N Compilers
A direct compiler implements a logical map (1:1), map (1:N) or map+group (M:N) between input partitions and output partitions, with constraints on the mapping function.
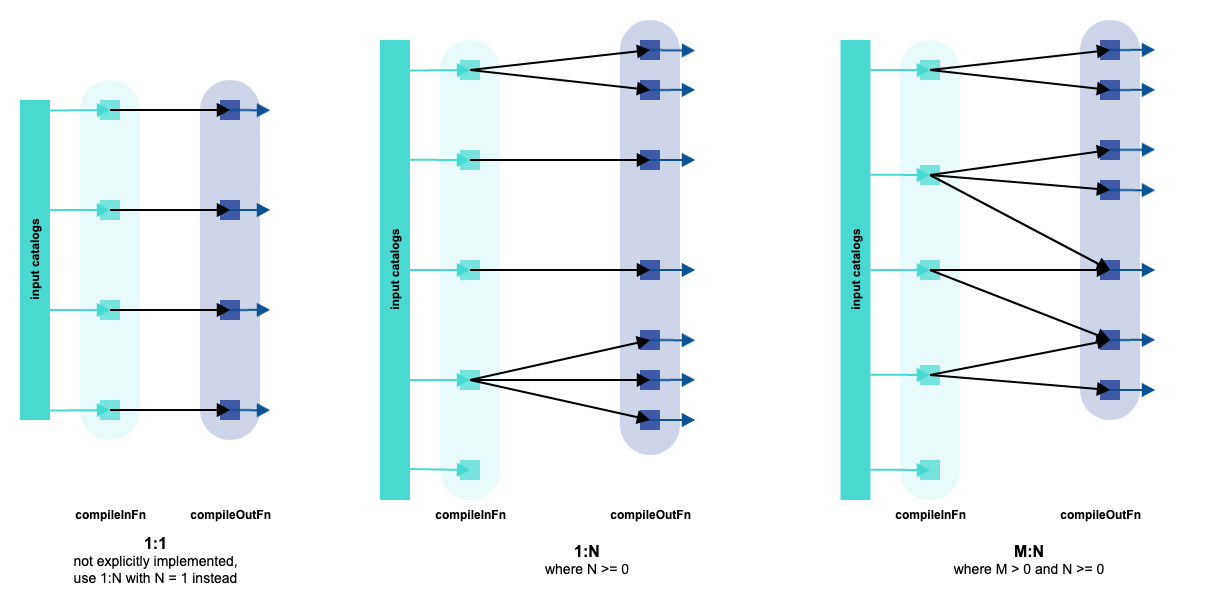
This pattern can be used when the input/output transformations follow these principles:
- Each input partition contributes to one or more output partition.
- Which output partition each input partition contributes to is a function of the partition key only, but not of its metadata or content.
- Each output partition is affected by one and only one input partition. This is the case for the Direct 1:N Compiler.
- Each output partition may be affected by more than one input partition. This is the case for the Direct M:N Compiler.
Typical Use Cases
Developers can use this pattern in cases where the transformation is based on the keys and not on their content (mapping is fixed).
- Passing metadata unchanged, similar to a multiplexer, or filtering by layer.
- Transforming partitions 1:1, such as decoding and re-encoding each payload.
- Re-tiling, such as changing the tiling scheme or shifting a layer of one or more levels up or down.
- Geometric transformations solely based on keys, such as processing neighboring tiles or merging and splitting tiles.
High-level Interface
T is a developer-defined type.
CompileIn (compiler front-end): describes the mapping between input and output keys and processes input keys to generate the intermediate Ts.
- mappingFn(in: InKey) ⇒ Iterable[OutKey]
- compileInFn(in: (InKey, InMeta)) ⇒ T
CompileOut (compiler back-end): collects and groups Ts coming from the front end (1 or M) to the same output partition and produces payloads that are then uploaded and committed.
-
compileOutFn(out: OutKey, intermediate: T) ⇒ Option[Payload] (for the 1:N case)
-
compileOutFn(out: OutKey, intermediate: Iterable[T]) ⇒ payloads to be published (for the M:N case)
Runtime Characteristics
Direct 1:N and M:N compilers are stateless.
The 1:N compiler is the most efficient. In incremental mode, mappingFn, compileInFn, and compileOutFn run only on a number of partitions proportional to the number of the changes. compileInFn and compileOutFn can be configured for parallel execution inside single Spark workers, in case they are I/O bound. In contrast, mappingFn cannot be I/O bound because it has no access to the metadata, so it cannot retrieve and process payloads.
The M:N compiler is almost as efficient as the 1:N. The description above also applies to the M:N case. However, in incremental mode, mappingFn is applied to the whole dataset, while compileInFn and compileOutFn are applied only to the changes or to the restricted set of output partitions that must be recomputed due to the input changes. mappingFn must be fast as it may even be executed multiple times for the same key.
Ts are stored in an RDD which is then shuffled between front-end and back-end stages. This may pose a limitation in terms of the amount of memory, disk, or network resources required.
References
-
TaskBuilder:withDirect1ToNCompilerandwithDirectMToNCompilermethods -
Direct1ToNCompiler: main interface to implement for the 1:N case -
DirectMToNCompiler: main interface to implement for the M:N case
MapGroupCompiler
This is a more general version of an M:N direct compiler. Unlike in an M:N direct compiler, where the input/output mapping is a function of the input key only, in a MapGroup compiler the input/output mapping is a function of the input key and the input metadata (therefore of the content) of the input catalogs.
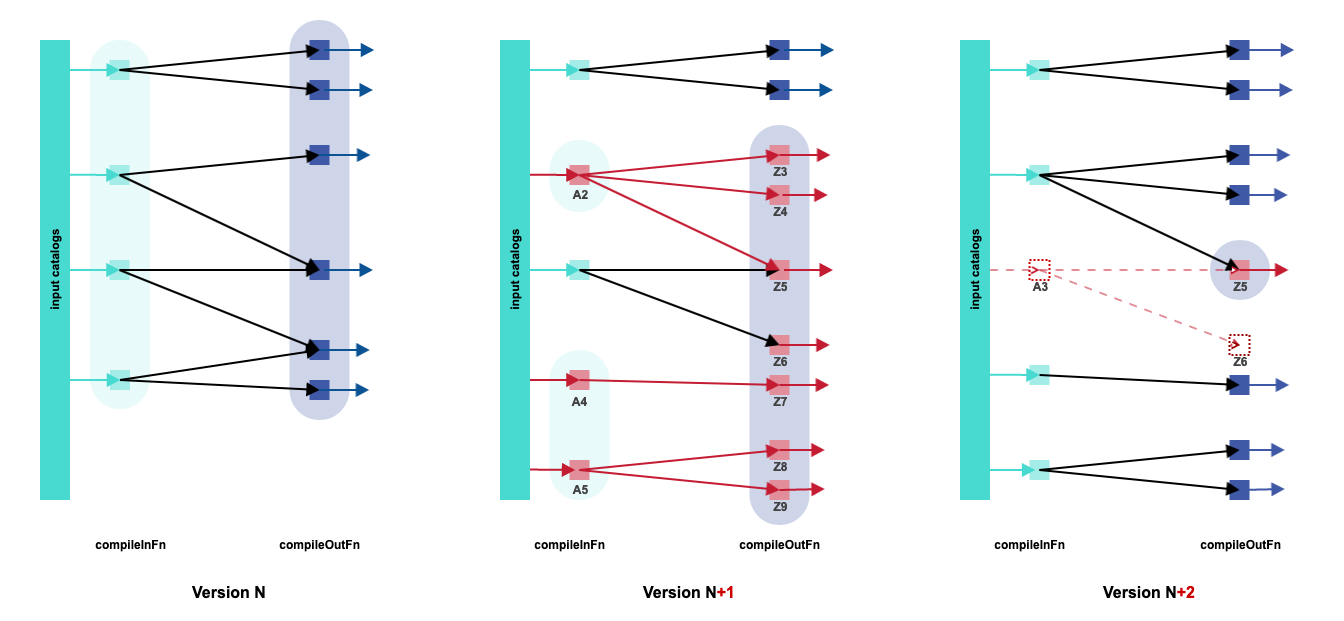
In the example above, a generic M:N compiler processes, at version N, input partitions (map), shuffles the resulting Ts grouping them by output partitions (group), and subsequently generates output partitions for publishing.
At version N+1, two input partitions (A2, A4) are changed and one input partition (A5) is added. A2 determines recompilation of the two output partitions (Z3, Z4) and the creation of a new one (Z5), due to changes in its payload. A 4 removes a dependency between itself and an output partition (Z6), again due to changes in its payload. Both the output partitions that depend on A4 at version N (Z6, Z7) or depended on A4 at version N+1 (Z7) are regenerated. The added input partition (A5) determines the creation of two new output partitions (Z8, Z9).
At version N+2, one input partition (A3) is deleted. Both the output partitions (Z5, Z6) that depended on A3 at version N+1 are reprocessed. Output partitions for which the input for reprocessing is empty are deleted. So in the example, Z5 is updated and published, while Z6 is deleted.
The behavior of the compiler across the various versions is fully dynamic. In other words, nothing is fixed: the input/output mapping and values Ts emitted by the front-end and grouped by the back-end, are a function of the input partitions.
The MapGroup compiler implementation included in the processing library orchestrates this entire process. You need only provide the two processing functions.
This pattern can be used when the input/output transformation follows these principles:
- Each input partition contributes to zero, one, or more output partitions.
- Which output partition each input partition contributes to may be a function of the partition key, metadata, or even content.
- Each input partition may affect output partitions in different ways, specific to the output partition key.
- Each output partition may be affected by more than one input partition.
- How an input partition affects the output can be a function of only that particular partition; it is not possible to "lookup" or "follow" references to additional partitions in the front-end.
Typical Use Cases
Developers can use this pattern in cases where the transformation takes into account the input content.
- Decoding input partitions and distributing content among different output partitions or as a function of the content.
- Creating output layers with a subset of input data.
- Distributing objects from input layers to output layers, shifting levels up or down, or as a function of object properties.
- Indexing of content, for example by country or by tile.
High-level Interface
T is a developer-defined type.
CompileIn (compiler front-end): processes keys and metadata, possibly retrieving the payloads, and produces the output partitions that are affected by the input, including "how" (as some intermediate processing data, T). The payloads of the output partitions will be functions of the input partitions through this intermediate data only.
- compileInFn(in: (InKey, InMeta)) ⇒ Iterable[OutKey, T]
CompileOut (compiler back-end): collects and groups Ts that are coming from the front-end to the same output partition and produces the payloads which are then uploaded and committed.
- compileOutFn(out: OutKey, intermediate: Iterable[T]) ⇒ payloads to be published
Runtime Characteristics
MapGroup is a stateful compiler: it persists in the output catalog, on a dedicated state layer, state data describing how the input affected the output in a previous compilation. The state data is then used and updated in each run to properly implement the incremental compilation. This requires no intervention from the developer.
The compiler is efficient also in incremental mode. Both compileInFn and compileOutFn run only on a number of partitions proportional to the number of changes. Which partitions are processed depends on the compiler implementation. In particular, compileInFn is run over:
- the changed partitions;
- the unchanged partitions whose intermediate processing result (
T) affects, according to the previous runs of compileInFn, output partitions that are candidate to recompilation.
compileInFn and compileOutFn can be configured for parallel execution inside single Spark workers, in case they are I/O bound.
Ts are stored in an RDD that is then shuffled between front-end and back-end stages. This may pose as a limitation in terms of the amount of memory, disk, or network resources required.
References
-
TaskBuilder:withMapGroupCompilermethod -
MapGroupCompiler: main interface to implement
RefTreeCompiler
This is an even more generic version of the aforementioned M:N map+group compiler. The main benefit of this pattern is the possibility of representing references between input partitions. These references are resolved, aggregated, and provided by the processing library already in the front-end (CompileIn). Therefore, input partitions are not compiled standalone, but have access to additional input partitions containing referenced objects or data logically related to them.
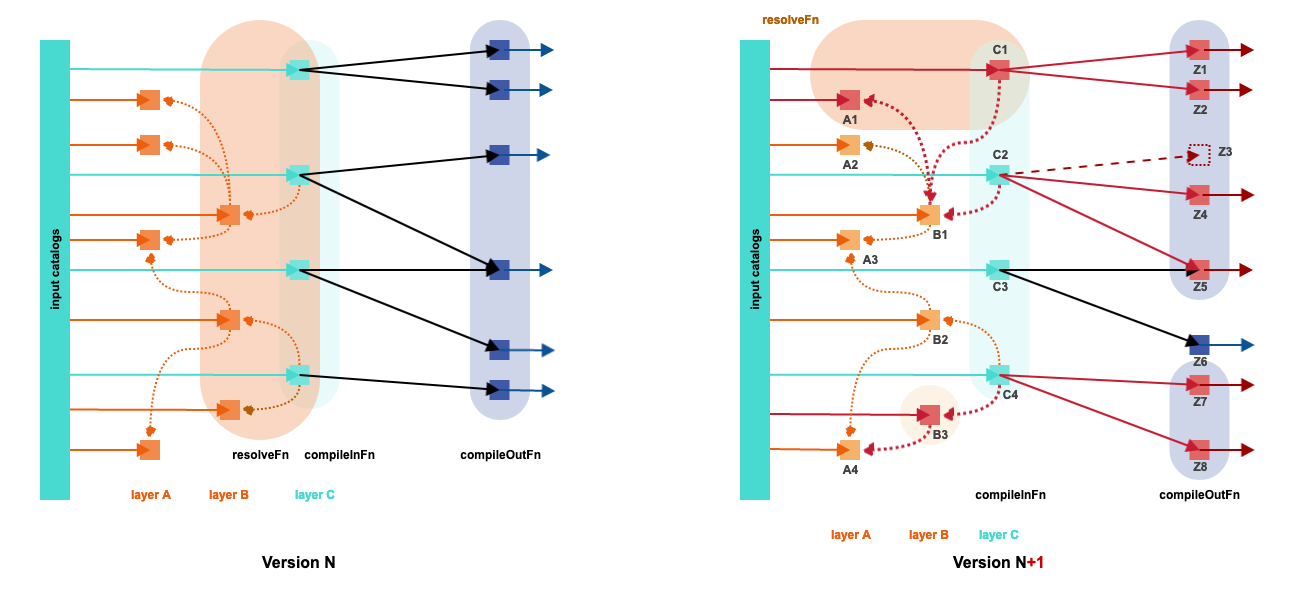
In the example, a generic compiler processes, at version N, input partitions, shuffles the resulting Ts grouping them by output partitions, and generates output partitions for publishing.
This is the first compiler that introduces layer-specific logic. For clarity, three layers (A, B, and C) are defined among the input catalog(s). One layer is defined as a subject layer, in this case, layer C. This is the layer that drives the compilation. In addition, layers A and B contain additional attributes and properties needed to compile the subject layer; they are the referenced layers. The result of compilation from one subject partition may affect 0, 1, or more output partitions, similar to the other compilers. There can be more than one subject layer and layers may be both subject and referenced simultaneously. However, in the example above, there are one subject layer and two "referenced" layers.
- Partitions of layer C may have zero or more references to partitions of layer B.
- Partitions of layer B may have zero or more references to partitions of layer A.
- Partitions of layer A have no references.
Conceptually, there are only two types of references (C → B and B → A) and these form a tree rooted in C; hence the name RefTree.

At version N+1, one partition changes for each layer. The change inC1 results in its recompilation that updates Z1 and Z2 and the creation of a new reference to B1. References are tracked, so the change of A1 results, indirectly via B1, also in recompilation of the subject C2. The recompilation of C2 produces one new (Z4), one updated (Z5) and one deleted (Z3) partition in the output map. The change of B3 results in recompilation of the subject C4 and the creation of a new reference to A4. At a given run, which references exist depends on the content. References are resolved by the processing library (via resolveFn), provided to each subject (via compileInFn), and affect the incremental compilation of future versions. All of the reference resolution logic, reference tracking, and dependency tracking is provided by the pattern implementation.
At compilation N+1, the following references are resolved and provided to the following subjects, that are recompiled:
- C1 with references to A1, A2, A3, B1.
- C2 with references to A1, A2, A3, B1.
- C3 with no references (not needed because of input changes, but to reproduce the output tile Z5 shared with C2).
- C4 with references to A3, A4, B2, B3.
Although the compilation of C3 produces output for Z6, this is discarded and Z6 is not recompiled.
A More Complex Example of Reference Trees

In this example, the schema of reference contains 3 trees.
The same layer may be both a subject and a reference, even within the same tree. Layers may also be present more than once, as references are independent. Refx in the examples are the reference names.
The tree rooted in C has the references:
- Ref1: C → B
- Ref2: B → A
The tree rooted in D has the references:
- Ref3: D → E
- Ref4: E → A
- Ref5: D → F
- Ref6: F → E
The two references to E are different.
The tree rooted in G has the references:
- Ref7: G → G
- Ref8: G → E
The reference from G to G is not cyclic. From one subject partition of G, it is possible to obtain zero, one, or more references to other partitions of G, but the chain of references from the subject G stops at this point. If needed, another G → G reference may be added to the tree, but this will also be not recursive: it will just stop the resolution of references to G after two hops.
This pattern can be used when the input or output transformation follows these principles:
- All of the applicable cases of MapGroupCompiler.
- Some input partitions (subjects) have references to other input partitions that shall be resolved to process the subjects fully.
- Which output partition each subject partition contributes to may be a function of the partition key, metadata, content, or referenced input partitions (with their metadata and content).
- Input partitions may reference other input partitions as long as the schema of the possible references is fixed and can be defined per layer.
Typical Use Cases
Developers can use this pattern in cases where the transformation takes into account the input content and there are references to be resolved and followed between input partitions.
- All the typical use cases of MapGroupCompiler.
- Compilation of complex input catalogs that have references between input partitions.
- Implicit references, such as a road layer and a topology layer that might be coupled together by a tile ID.
- Explicit references within the same layer, such as partitions of a road layer that reference other partitions to form the road graph.
- Explicit references across layers and catalogs, such as a road layer that references attributes or admin area information stored in other layers.
High-level Interface
T is a developer-defined type.
Resolve (calculation and resolution of references): defines the structure of the references between input partitions. The input partitions are then analyzed, eventually retrieving their payloads, to calculate the other input partitions that these partitions reference.
- refStructure: tree structure modelling the references
- resolveFn(in: (InKey, InMeta)) ⇒ Map[reference, Set[InKey]]
CompileIn (compiler front-end): processes key and metadata of each input partition and its references, eventually retrieving the payloads, and produces the output partitions that are affected by the input, including "how" (the intermediate Ts).
- compileInFn(in: (InKey, InMeta), refs: Map[InKey, InMeta]) ⇒ Iterable[ OutKey, T]
CompileOut (compiler back-end): collects and groups the Ts coming from the front-end to the same output partition and produces the payloads that are then uploaded and committed.
- compileOutFn(out: OutKey, intermediate: Iterable[T]) ⇒ payloads to be published
Runtime Characteristics
RefTreeCompiler is a stateful compiler: it persists in the output catalog, on a dedicated state layer, state data describing references among input partitions and how the input affected the output in a previous compilation. This state data is then used and updated in each run to properly implement the incremental compilation. This requires no intervention from the developer.
The compiler is efficient also in incremental mode. resolveFn, compileInFn and compileOutFn run only on a number of partitions proportional to the number of changes. Which partitions are processed depends on the compiler implementation. In particular:
-
resolveFnis run over the changed partitions only; -
compileInFnis run over:- the changed partitions;
- the partitions with changed references;
- the unchanged partitions, whose intermediate processing result (
T) affects, according to the previous runs ofcompileInFn, output partitions that are candidate for recompilation.
resolveFn, compileInFn and compileOutFn can be configured for parallel execution inside single Spark workers, in case they are I/O bound.
Ts are stored in an RDD which is then shuffled between front-end and back-end stages. This may pose a limitation in terms of the amount of memory, disk, or network resources required.
References
-
TaskBuilder:withRefTreeCompilermethod -
RefTreeCompiler: main interface to implement -
RefTree: reference tree structure, that controls the process