- 製品 製品ロケーションサービス
ジオフェンスからカスタム ルート検索まで、ロケーションに関する複雑な課題を解決します
プラットフォームロケーションを中心としたソリューションの構築、データ交換、可視化を実現するクラウド環境
トラッキングとポジショニング屋内または屋外での人やデバイスの高速かつ正確なトラッキングとポジショニング
API および SDK使いやすく、拡張性が高く、柔軟性に優れたツールで迅速に作業を開始できます
開発者エコシステムお気に入りの開発者プラットフォーム エコシステムでロケーションサービスにアクセスできます
- ドキュメント ドキュメント概要 概要サービス サービスアプリケーション アプリケーションSDKおよび開発ツール SDKおよび開発ツールコンテンツ コンテンツHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE Marketplaceプラットフォーム基盤とポリシーに関するドキュメントプラットフォーム基盤とポリシーに関するドキュメント
- 価格
- リソース リソースチュートリアル チュートリアル例 例ブログとリリースの公開 ブログとリリースの公開変更履歴 変更履歴開発者向けニュースレター 開発者向けニュースレターナレッジベース ナレッジベースフィーチャー 一覧フィーチャー 一覧サポートプラン サポートプランシステムステータス システムステータスロケーションサービスのカバレッジ情報ロケーションサービスのカバレッジ情報学習向けのサンプルマップデータ学習向けのサンプルマップデータ
- ヘルプ
プラットフォーム で Spark アプリケーションを実行します
目的: プラットフォーム でシンプルな Spark アプリケーションを実行し、アプリケーションの実行を監視します。
複雑さ: 初心者向け
所要時間: 40 分
前提条件: Spark アプリケーションを開発し、 プロジェクトで作業内容を整理します
このチュートリアルでは、プラットフォームでの「Spark アプリケーションの開発」チュートリアルで開発された Spark アプリケーションを実行する方法を示します。 Splunk 、 Spark UI 、 Grafana 、およびプラットフォーム 請求ページを使用して、アプリケーションの実行に関する情報を取得する方法を示します。
このチュートリアルでは、次のトピックについて説明します。
- プラットフォーム でリソースを設定します
- プラットフォーム で Spark アプリケーションを実行します
- Spark UI を使用して実行プランを表示します
- Splunk からアプリケーションログを取得します
- Grafana ホーム を使用してアプリケーションデータを監視します
- 実行コストを取得します
プラットフォーム でリソースを設定します
アプリケーションをプロジェクトで実行します。 プロジェクトは、アプリ 、サービス、またはその他の作業用製品をビルドするために使用する HERE platform リソースのコンテナです。 カタログ、パイプライン、スキーマ、サービスなどのリソースを含めることができます。 プロジェクトは、プロジェクト内のリソースにアクセスできるユーザー、アプリ、およびグループを制御します。 すべてのプラットフォーム リソースを管理するには、プロジェクトを使用することをお勧めします。 プロジェクトの詳細については、「プロジェクトの管理」ドキュメントを参照してください。
OLP CLI を使用してプロジェクトを作成してみましょう。
olp project create {{PROJECT_ID}} {{PROJECT_NAME}}
OLP CLI から次のメッセージが返されます。
Project {{YOUR_PROJECT_HRN}} has been created.
{{YOUR_PROJECT_HRN}} この値を console 変数に保存すると、コマンドの実行が簡単になります。
次のステップでは、前に作成したプロジェクトに入力および出力カタログを作成します。 --scope このパラメーターは、 OLP CLI でプロジェクトを指定するために使用されます。
チュートリアルフォルダーのルートから次のコマンドを実行して、 catalog-configuration.jsonSpark アプリケーションの開発 チュートリアルで使用したものとまったく同じ設定 ファイルを使用して入力カタログを作成します。
olp catalog create <catalog-id> <catalog-name> --config catalog-configuration.json --scope YOUR_PROJECT_HRN
OLP CLI から次のメッセージが返されます。
Catalog YOUR_INPUT_CATALOG_HRN has been created.
注
レルムで請求タグが必要な場合 は、layerセクションにbillingTags: ["YOUR_BILLING_TAG"]プロパティを追加して設定 ファイルを更新します。
出力カタログ は、を使用して作成する必要 output-catalog-configuration.jsonがあります。 チュートリアルフォルダーのルートから次のコマンドを実行して、出力カタログ を作成します。
olp catalog create <catalog-id> <catalog-name> --config output-catalog-configuration.json --scope YOUR_PROJECT_HRN
出力カタログ は当社のアプリケーションでは使用されていません。 OUTPUT_CATALOG_HRNpipeline-config.conf ファイル内のプレースホルダーを置き換えるには、このカタログが必要です。
次の手順では、前に作成した入力カタログ を使用するようにソースコードを設定します。 INPUT_CATALOG_HRNOUTPUT_CATALOG_HRNpipeline-config.conf ファイルのおよびプレースホルダーを、上記で作成したカタログの HRNS に置き換えます。
プラットフォーム に展開するには、アプリケーションに Fat JAR のすべての依存関係をパッケージ化する必要があります。 java/Scala SDK は platform 、ファット JAR を生成するプロファイルを提供します。 次のコマンドは、プロファイルを使用して Fat JAR を生成します。
mvn -Pplatform clean package
develop-spark-application-<tutorial-version>-platform.jar Fat JAR は ターゲット フォルダに作成する必要があります。
プラットフォーム で Spark アプリケーションを実行します
プラットフォーム で Spark アプリケーションを実行するには、 パイプライン API について理解しておく必要があります。
次の図は、 OLP CLI を使用したパイプライン の完全な展開フローを示しています。
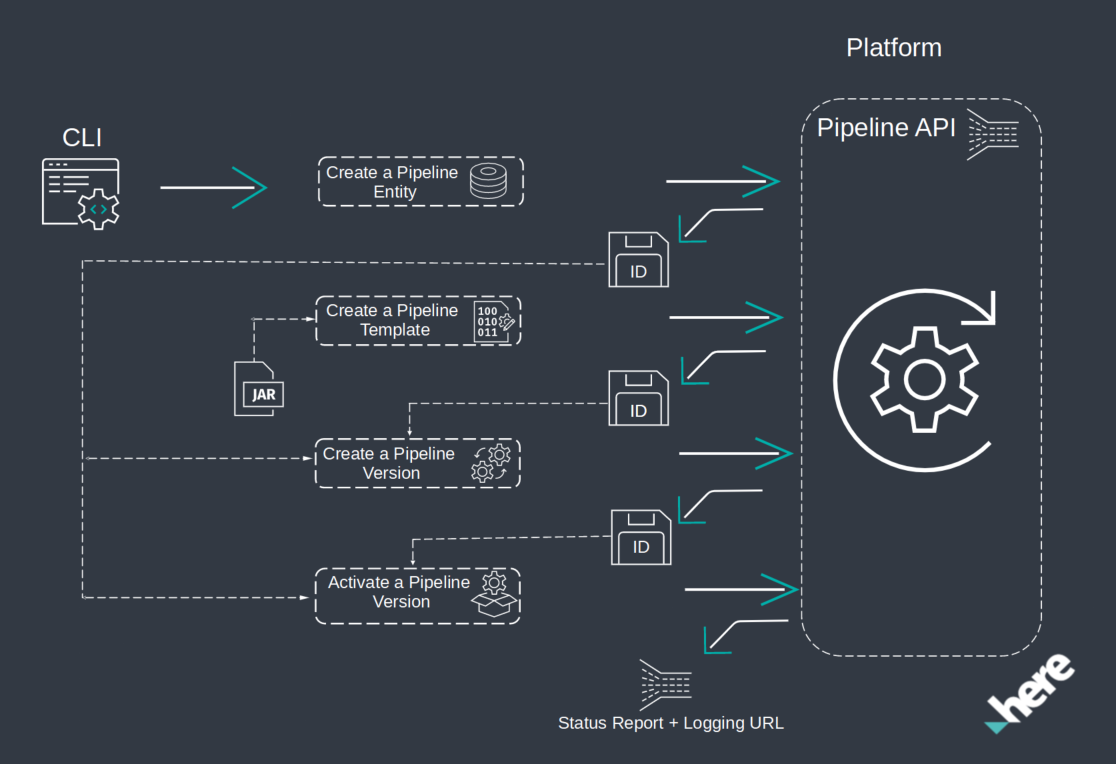
パイプラインの詳細については、『パイプライン開発者ガイド』を参照してください。
これで、アプリケーションで使用されているすべてのリソースと、それらを使用するように設定されたアプリケーションが、プラットフォーム に展開できるようになりました。 アプリケーションを起動してみましょう。
次の OLP CLI コマンドを使用して、プロジェクト範囲にパイプライン を作成してみましょう。
olp pipeline create {{PIPELINE_ID}} --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
Pipeline {{YOUR_PIPELINE_ID}} has been created.
次のステップでは、パイプライン テンプレート を作成します。 パイプラインの作成を支援するパイプライン テンプレートが提供されています。 これらのテンプレートには、再利用可能なパイプライン 定義 ( 実装、入力スキーマ、出力カタログ スキーマ ) が含まれています。
独自のパイプライン テンプレート を作成するには、テンプレート 名 batchランタイム環境 を指定する必要があります。このチュートリアルでは、 Spark アプリケーションを実行し、 batch プラットフォーム 上の環境、 mvn package -Pplatform コマンドで作成されたファット JAR 、メインクラス、パイプライン が属するプロジェクトを使用します。 および入力カタログ ID がパイプライン バージョンの設定で必要です。
チュートリアルフォルダーのルートから次の OLP CLI コマンドを実行して、パイプライン テンプレート を作成しましょう。
Java アプリケーション
Scala アプリケーション
olp pipeline template create {{TEMPLATE_NAME}} \
batch-3.0 target/develop-spark-application-<version>-platform.jar \
DevelopSparkApplication --input-catalog-ids pipeline-config.conf \
--scope {{YOUR_PROJECT_HRN}}
olp pipeline template create {{TEMPLATE_NAME}} \
batch-3.0 target/develop-spark-application-<version>-platform.jar \
DevelopSparkApplicationScala --input-catalog-ids \
pipeline-config.conf --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
Pipeline template {{YOUR_PIPELINE_TEMPLATE_ID}} has been created.
次のステップでは、パイプライン バージョンを作成します。 パイプライン API では、パイプライン のバージョンはパイプライン およびパイプライン テンプレート の形式になります。
パイプライン に develop-spark 関連する請求および使用状況のデータを取得できる請求タグを使用して、プロジェクト範囲でパイプライン バージョンを作成してみましょう。 詳細については、「請求と使用方法」の章を参照してください。 パイプライン バージョンに請求タグを追加するには、チュートリアルフォルダのルートから次の OLP CLI コマンドを実行します。
olp pipeline version create test-spark-version {{YOUR_PIPELINE_ID}} {{YOUR_PIPELINE_TEMPLATE_ID}} pipeline-config.conf --billing-tag develop-spark --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
Pipeline {{YOUR_PIPELINE_ID}} has been created.
バッチ パイプライン 、パイプライン テンプレート 、およびパイプライン バージョンを作成したら、パイプライン バージョンをアクティブ化することで、プラットフォーム でアプリケーションを実行できます。
バッチ パイプライン バージョンをアクティブ化するには、いくつかの実行モードを使用できます。On-demand、および ScheduledTime Schedule。 これらの実行モードについて詳しく見ていきましょう。 --schedule パイプライン バージョンをアクティブ化するときにフラグが指定されなかっ On-demand た場合、デフォルトで実行モードが使用されます。 On-demand モードでは、パイプライン が Scheduled 状態に入り、ただちに Running 状態に変化して、指定した入力データカタログの処理を試行します。 ジョブが完了 Ready すると、パイプライン は状態に戻ります。 入力カタログが新しいデータを受信しても、これ以上処理は行われません。 追加の処理は手動で開始する必要があります。
--schedule パラメーターでフラグが指定された場合 data-changeScheduled 、実行モードが使用されます。 このモードでは、パイプライン バージョンが Scheduled 短時間ステートに入り、 Running 状態に変化して入力カタログ内の既存のデータの処理を開始します。 ジョブが完了すると Scheduled 、入力カタログで新しいデータが使用可能になるまで待機する状態に戻ります。 データが変更されるとパイプラインが開始されますが、すべてのデータを再度処理することも、変更されたデータのみを処理することもできます。 アプリケーションの実装によって異なります。
最後の実行モードは Time Schedule です。このモードは、time:<cron-expression> パラメータとともに --schedule フラグを使用して選択できます。<cron-expression>は UNIX の cron 形式で指定します。
このモードでは、パイプライン は Scheduled 状態に入り、に従って実行されるまで待機 Time Scheduleします。 次に、パイプライン が Running 状態に変更され、入力カタログの既存のデータの処理が開始されます。 ジョブが完了すると Scheduled 、に従って一定の時間待機する状態に戻り Time Scheduleます。
このチュートリアルでは Scheduled 、新しいデータがカタログにアップロードされた場合にのみパイプライン が実行されるため、実行モードを使用します。
パイプライン バージョンをアクティブ化するには、次の OLP CLI コマンドを実行します。
olp pipeline version activate {{YOUR_PIPELINE_ID}} {{PIPELINE_VERSION_ID}} --schedule data-change --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
Pipeline version {{YOUR_PIPELINE_ID}} has been activated.
このコマンドを実行すると、パイプライン は起動せ Scheduled ずに状態に移行し、入力カタログ が更新されるまで待機します。 パイプライン の現在の状態は 、プラットフォーム のパイプライン ページで確認 olp pipeline version show できます。または、以下に示すように、次の OLP CLI コマンドを使用して確認できます。
入力カタログ にカスタムデータをアップロードして、パイプライン をトリガーしましょう。 これを行うには、次の OLP CLI コマンドを実行します。
olp catalog layer partition put {{YOUR_CATALOG_HRN}} versioned-layer-custom-data --partitions partition:data/partition_content --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
100% [======================================================] 1/1 (0:00:00 / 0:00:00)
Partition partition was successfully uploaded.
入力カタログ が変更されると、パイプライン がトリガーされ、入力カタログ からのデータの処理が開始されます。 Scheduled 状態から Running 状態への切り替え処理には、最大 5 分かかることに注意してください。
パイプライン の現在の状態を確認するには、次の OLP CLI コマンドを実行します。
olp pipeline version show {{YOUR_PIPELINE_ID}} {{PIPELINE_VERSION_ID}} --scope {{YOUR_PROJECT_HRN}}
OLP CLI は、指定されたパイプライン バージョンに関する情報(設定、 logging URL、、など)を返す必要 pipeline UI URLがあります。 logging URL は Splunk ログの URL で、 pipeline UI URL は Spark UI の URL です。loggingpipeline UI 次の章で使用するおよび URL を覚えておいてください。
Details of the {{YOUR_PIPELINE_ID}} pipeline:
ID d18282cd-63bb-4640-9f39-a05daa04b5ab
version number 1
pipeline template ID d03d3762-c02e-48ec-a3d5-38f85de0ce69
output catalog HRN {{YOUR_OUTPUT_CATALOG}}
state running
created 2022-03-28T11:00:31.932502Z
updated 2022-03-28T13:38:33.893834Z
highAvailability false
multi-region enabled false
input catalogs
ID HRN
sparkCatalog {{YOUR_INPUT_CATALOG}}
logging URL https://splunk.metrics.platform.here.com/en-US/app/olp-here-test/search?q=search%20index%3Dolp-here-test_common%20namespace%3Dolp-here-test-j-72afe4b1-f5f0-4b77-9d04-79f6c47c71d3
pipeline UI URL https://eu-west-1.pipelines.platform.here.com/jobs/72afe4b1-f5f0-4b77-9d04-79f6c47c71d3/ui
billing tag develop-spark
schedule data-change
アプリケーションがプラットフォーム で起動し、実行されています。 実行プランとログを確認し、アプリケーションの監視を設定しましょう。
Spark UI を使用して実行プランを表示します
バッチパイプラインには、バッチジョブの実行を監視および検査するための便利なツールがあります。 Spark フレームワークには、実行中状態のすべての Spark ジョブでアクティブな Web コンソールが含まれています。 これは Spark UI と呼ばれ、プラットフォーム 内から直接、または olp pipeline version show OLP CLI コマンドを使用してアクセスできます。 バッチ パイプライン ジョブが Running 状態に切り替わると、 Spark UI が自動的に開始されます。 Spark UI では、ジョブ、ステージ、実行グラフ、実行者からのログなど、バッチ パイプライン の処理に関する情報を提供します。
batch-2.1.0 ランタイム環境 から、パイプライン ジョブの実行が完了した後で Spark UI にアクセスすることもできます。 完了したジョブのランタイムデータには、完了後 30 日間、 Spark UI からアクセスできます。
実行中のパイプライン がある場合は、 Spark UI にアクセスできます。pipeline UIolp pipeline version show 前の章のコマンドの結果から URL を使用します。
pipeline UI 次の図に示すように、 URL によってブラウザで Spark UI が開きます。
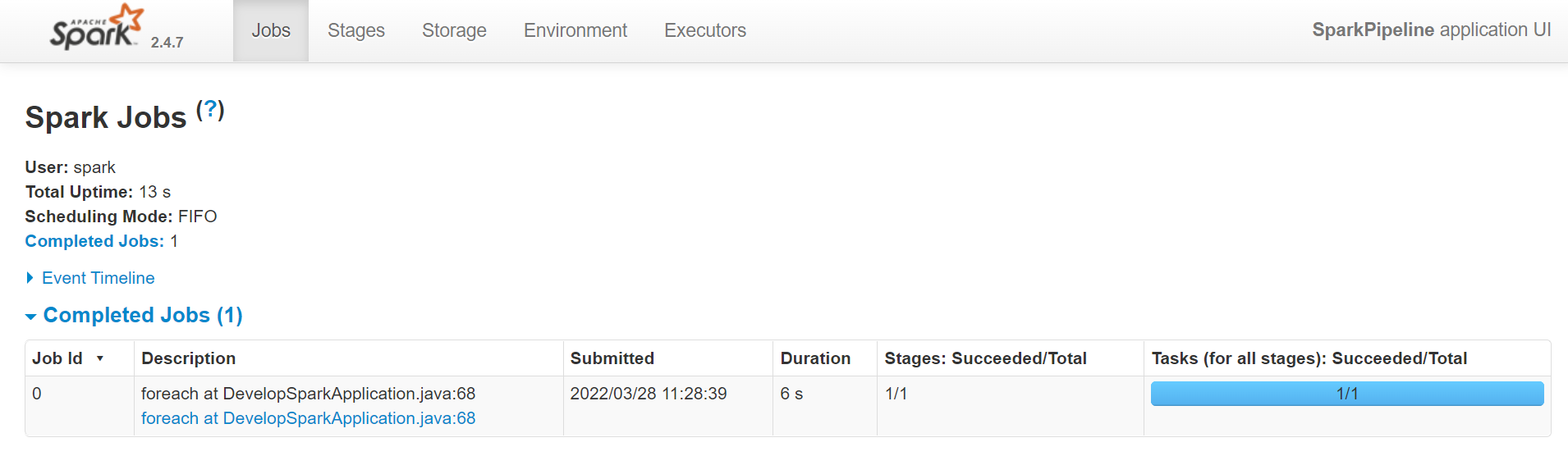
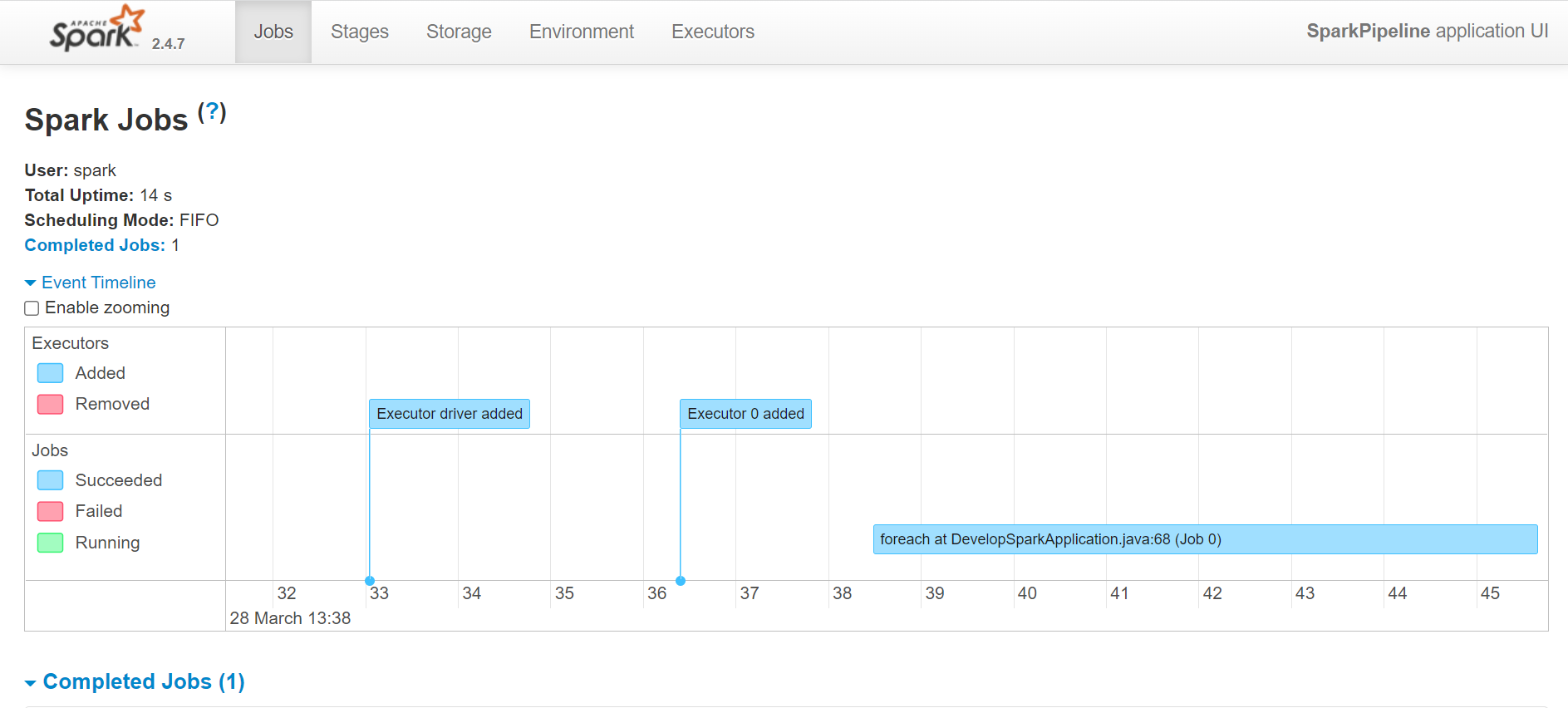
5 つのタブから、さまざまなカテゴリの情報にアクセスできます。 [ ジョブ ] タブには、 Spark アプリケーションのすべてのジョブの概要ページと、各ジョブの詳細ページが表示されます。 概要ページには、すべてのジョブのステータス、期間、進行状況、イベント全体のタイムラインなどの概要情報が表示されます。 概要ページでジョブをクリックすると、そのジョブの詳細ページが表示されます。
[ ステージ ] タブには、 Spark アプリケーションのすべてのジョブのすべてのステージの現在の状態を示す概要ページが表示されます。
![[ ステージ ] タブ](https://here-tech.skawa.fun/documentation/java-scala-dev/dev_guide/run-spark-application-platform/img/stage-tabs.png)
[ ストレージ ] タブには、アプリケーション内に永続化された DDs と DataFrame がある場合は、それらが表示されます。 概要ページには、すべての DDs のストレージレベル、サイズ、およびパーティションが表示されます。詳細ページには、 RDD または DataFrame 内のすべてのパーティションのサイズと実行者の使用状況が表示されます。
[ 環境 ] タブには、 JVM 、 Spark 、システムのプロパティなど、さまざまな環境変数および設定変数の値が表示されます。
![[ 環境 ] タブ](https://here-tech.skawa.fun/documentation/java-scala-dev/dev_guide/run-spark-application-platform/img/environment-tab.png)
[ 実行者 ] タブには、メモリ、ディスク使用量、タスク、シャッフル情報など、アプリケーション用に作成された実行者に関する概要情報が表示されます。 [ ストレージメモリ ] 列には、データのキャッシュに使用され、予約されているメモリの量が表示されます。
![[ 実行者 ] タブ](https://here-tech.skawa.fun/documentation/java-scala-dev/dev_guide/run-spark-application-platform/img/executors-tabs.png)
このバージョンの Spark UI は、プラットフォーム と互換性があるように変更されています。 これは、ネイティブ Spark 環境で利用できる HERE では利用できない機能があることを意味します。 他の Spark UI ドキュメントを参照しているときに、 HERE がない機能についてのディスカッションが表示されることがあります。 不足している機能はプラットフォーム と互換性がありません。
Apache Spark Web UI については Apache Spark Web サイトの「Apache Spark Web UI」ページを参照してください。
Splunk からアプリケーションログを取得します
Splunk は、 Web サイト、アプリケーション、センサー、デバイス、その他のソースから収集された機械生成データを検索、分析、および視覚化するためのソフトウェアプラットフォーム です。 IT インフラストラクチャとビジネスを構成します。 Splunk の使用方法については 、 Splunk エンタープライズユーザーマニュアルを参照してください。
HERE platform では、ログレベルがパイプライン バージョンに設定されています。 すべてのジョブで、対応するパイプライン バージョンに関連付けられているログレベルが使用されます。 ログレベルは、パイプライン 全体のルートレベル、または指定したクラスの個別のログレベルとして設定できます。 デフォルトでは、エラーおよび警告のログエントリが確認のために Splunk に送信されます。 ログに記録される情報量は、実行時に各パイプライン バージョンで選択したログレベルによって異なります。 運用の遅延により、変更が有効になるまでに数分かかります。 これにより、 Splunk の新しいレベルでログが利用できなくなる可能性があります。
パイプライン バージョンの現在のログレベルを確認するには、次の OLP CLI コマンドを実行します。
olp pipeline version log level get {{YOUR_PIPELINE_ID}} {{YOUR_PIPELINE_VERSION_ID}} --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
Current logging configuration
root warn
出力から、デフォルトのログレベルがであることがわかり warnます。 つまり、 Splunk は、 Logger.info()log4j ライブラリ のメソッドを使用してすべてのデータをログに記録するため、アプリケーションからのログを表示しません。 Splunk でログを表示するに infoは、ログレベルをに設定する必要があります。
OLP CLI には olp pipeline version log level set 、パイプライン バージョンのログを設定するためのコマンドが用意されています。
olp pipeline version log level set {{YOUR_PIPELINE_ID}} {{YOUR_PIPELINE_VERSION_ID}} --root info --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
Current logging configuration
root info
アプリケーションでログを設定する方法の詳細については、『Pipelines 開発者ガイド』を参照してください。
これまでのところ、アプリケーションは Splunk にログを送信していません。 アプリケーションは、入力カタログ からのデータを処理する場合にのみログを送信します。 バッチ パイプライン を使用しているため Scheduled 、前の章で開始したパイプライン がすでに完了し、状態に移行されています。 そのため、に切り替える必要 Runningがあります。 これを行うに --schedule data-change は、入力カタログ を変更します。パイプライン は、パイプライン バージョンをアクティブ化するためのパラメータで指定された設定に従って開始されます。 次の OLP CLI コマンドを使用して、カタログにデータを挿入してみましょう。
olp catalog layer partition put {{YOUR_CATALOG_HRN}} versioned-layer-custom-data --partitions partition:data/partition_content --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
100% [======================================================] 1/1 (0:00:00 / 0:00:00)
Partition partition was successfully uploaded.
入力カタログ が変更されると、パイプライン は Running 状態に切り替わり、入力カタログ からのデータを処理するか、またはパーティション コンテンツを Splunk にログします。
logging URLpipeline version show パイプライン が Running Splunk UI に到達するように状態に変更された場合は、 from the コマンドを使用します。
実行中の各パイプライン バージョンには、そのパイプライン のログが保存される一意の URL があります。 CLI を使用する場合 pipeline version activatepipeline version upgradepipeline version show 、 , , コマンドが実行されるたびに、パイプライン によってログ URL 情報が提供されます。
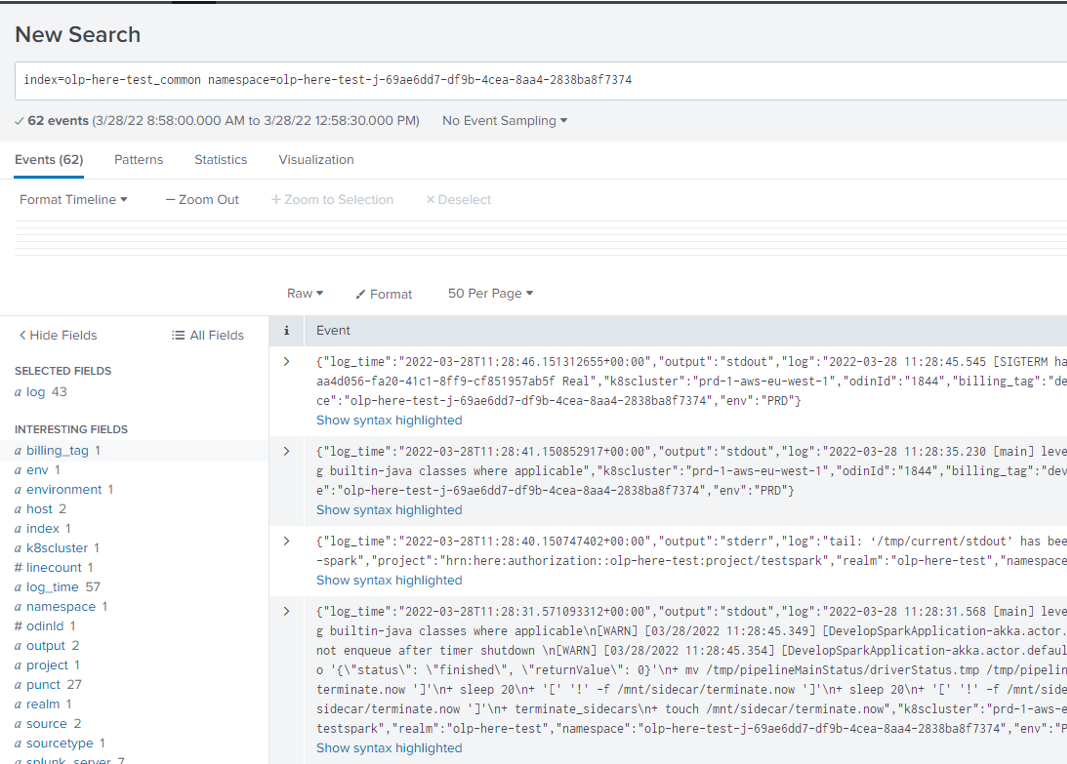
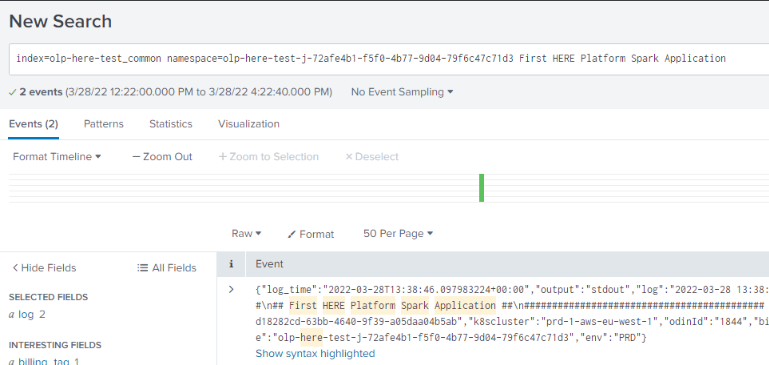
Splunk で特定のログを検索する必要がある場合 Search lineは、の最後のパラメータとしてフィルタを追加できます。 パイプライン ログは <realm>_common インデックスに保存されます。 たとえば、アカウントが olp-here レルム内にある場合、インデックスはになり olp-here_commonます。
以下のイメージでは、に Search line インデックス、パイプライン バージョンによって生成された名前空間 、および最後 First HERE Platform Spark Application のパラメーターが含まれていることがわかります。このパラメーターは、カタログにアップロードされたデータを以前に検索するためのフィルターにすぎません。
Splunk からログを取得する方法の詳細については、「アプリケーションログの検索」ページを参照してください。
このようにして、 Splunk UI を使用して作成された情報を取得するようにアプリケーションのログを設定できます。
Grafana ホーム を使用してアプリケーションデータを監視します
アプリケーションがプラットフォーム で実行され、 Spark UI および Splunk で正しく動作していることが確認されたので、次のステップで監視を設定します。
Grafana は、メトリクス、ログ、およびトレースを監視および分析できる完全な監視可能なスタックです。 データの保存場所に関係なく、データのクエリ、視覚化、警告、把握を行うことができます。
リージョンごとに 1 つの Grafana があります。 ダッシュボードに表示されるメトリクスは、その地域にのみ属します。 そのため、プラットフォーム にはプライマリリージョンとセカンダリリージョンの監視ページが用意されています。
このチュートリアルはプライマリリージョンで実行され、プライマリリージョン Grafana の手順を示します。
このチュートリアルでは、アプリケーションの実行を監視する方法、または既存の Grafana ホーム を使用してパイプライン ステータスを確認する方法、失敗したジョブの数を監視する独自の Grafana ホーム 、およびジョブが失敗したときに電子メールで警告を送信する Grafana アラートを作成する方法について説明します。
パイプライン のステータスを監視 Pipeline Status するために、 Grafana でホーム を利用できます。
プラットフォーム ポータル に移動し Launcher 、メニューを開いてを選択 Primary Region Monitoring します。 Grafana のホームページに移動します。
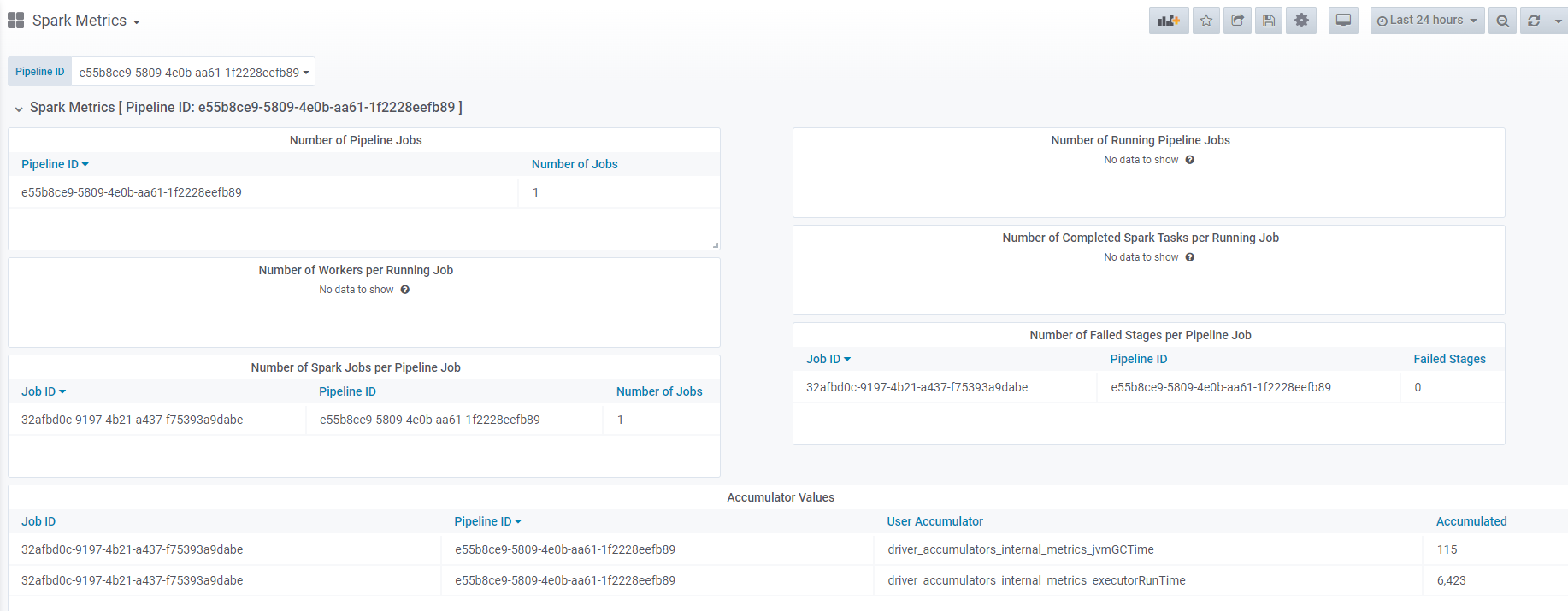
ホームページでは、複数のダッシュボードにアクセスできます。 ページ Default Dashboards の左側に複数のページが一覧表示されます。 デフォルトのダッシュボードのリストから Spark Metrics 、ホーム を探します。 ホーム 名をクリックして開きます。 Spark Metrics ホーム には、パイプライン に関連する Spark メトリックが表形式で表示されます。 パイプライン に関する情報を取得するに Pipeline IDEnterは、フィールドにパイプライン ID を入力し、を押します。
その結果、パイプライン について利用可能なすべての情報、つまり、パイプライン ジョブの数、実行中のパイプライン ジョブの数、実行中のジョブあたりのワーカーの数、実行中のジョブあたりの完了済み Spark タスクの数、パイプライン ジョブあたりの Spark ジョブの数が取得されます。 およびパイプライン ジョブごとの失敗したステージの数。
プラットフォーム では、既存の Grafana ダッシュボードを使用できるだけでなく、独自のダッシュボードを作成することもできます。
注
独自の Grafana ホーム を作成し、特定のメトリッククエリーを設定する場合 Dashboards monitor は、そのロールを持っている必要があります。 この役割は OrgAdmin 、プラットフォーム で役割を持つ任意のユーザーに付与できます。
独自の Grafana ホーム を作成するには、次の手順を実行します。
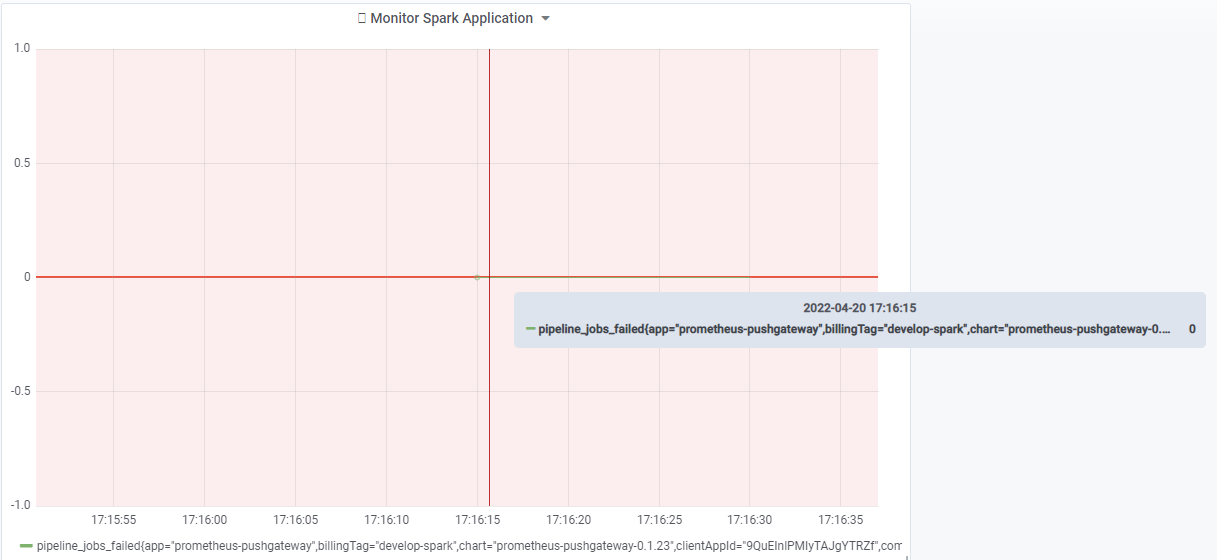
Create> をクリックしますDashboardAdd Queryクエリーを選択して設定します。{__name__="pipeline_jobs_failed", pipelineId="YOUR_PIPELINE_ID"}失敗したジョブの数を監視するクエリーを追加します。 上記のクエリで__name__は、パラメーターはに設定pipeline_jobs_failedされています。 つまり、 Grafana ホーム にpipelineIdは、フィールドで指定されたパイプライン の失敗したジョブの合計数が表示されます。
ホーム が作成されると、失敗したジョブがまだないため、値が 0 のジョブが 1 つ表示されます。
入力カタログ に変更を追加して、パイプライン Running が状態に入るようにします。
パイプライン で失敗したジョブの数を表示する Grafana ホーム を作成した場合と同様に、パイプライン でジョブを作成しようとしますが、失敗します。 これを行う data/fail_pipeline には、パーティション を入力カタログ に追加する必要があります。 このパーティション の内容はです THROW_EXCEPTION 。パイプライン テンプレート を作成したメインクラスを参照すると、次のコードを参照できます。
if (partitionContent.contains("THROW_EXCEPTION")) {
throw new RuntimeException("About to throw an exception");
}
これは、パーティションを読み取るとき RuntimeException に、パーティション の内容がと等しい場合にアプリケーションがをスロー THROW_EXCEPTIONすることを意味します。これにより、パイプライン が失敗します。 上記で作成した Grafana ホーム を使用して監視できます。
THROW_EXCEPTION 次の OLP CLI コマンドを使用して、パーティション をバージョン付レイヤー にプッシュしてみましょう。
olp catalog layer partition put {{YOUR_CATALOG_HRN}} versioned-layer-custom-data --partitions partition:data/fail_pipeline --scope {{YOUR_PROJECT_HRN}}
OLP CLI から次のメッセージが返されます。
100% [======================================================] 1/1 (0:00:00 / 0:00:00)
Partition partition was successfully uploaded.
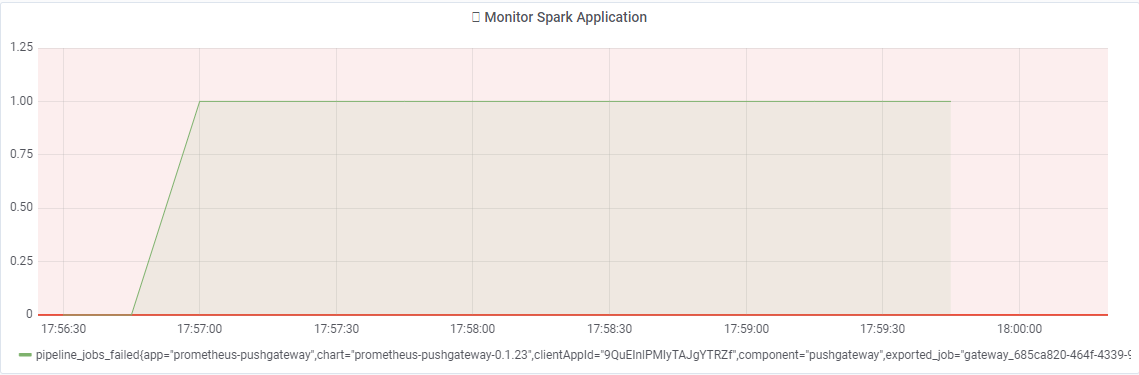
パーティション がバージョン付レイヤー にアップロードされ、パイプライン がトリガーされて失敗すると、以前に作成された Grafana ホーム で結果を確認できます。
次の画像では、 Grafana に失敗したパイプライン が表示されています。
Flink アプリケーションを監視するように Grafana クエリを設定する方法の詳細については『Logs, Monitoring and Alerts ユーザー ガイド』を参照してください。
次のステップでは、パイプライン に失敗したジョブがないことを監視するアラートを作成します。 Grafana では、条件またはしきい値に達したときにアラートを設定し、電子メール通知を要求できます。
まず、次の手順で通知チャネルを作成する必要があります。
- Grafana で左上にあるドロップダウンメニューをクリックし、
Alerting>Notification Channels>New channelを選択します。 - チャネル名
Example Channelを指定し、タイプフィールドでemailを選択してEmail settingsチャプタで電子メールアドレスemail@example.comを指定します。
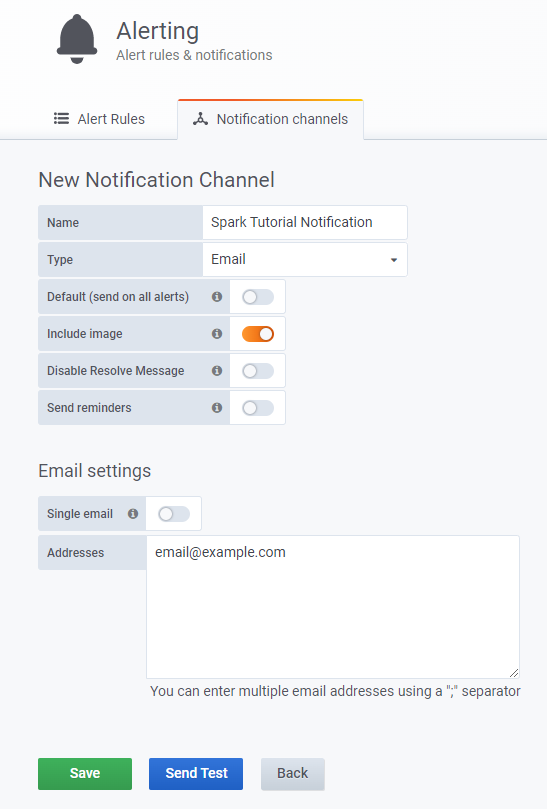
詳細およびオプションについては、通知に関する Grafana ドキュメントを参照してください。
アラートを作成するには、次の手順を実行します。
- 上記の説明に従って作成した Grafana ホーム をクリック
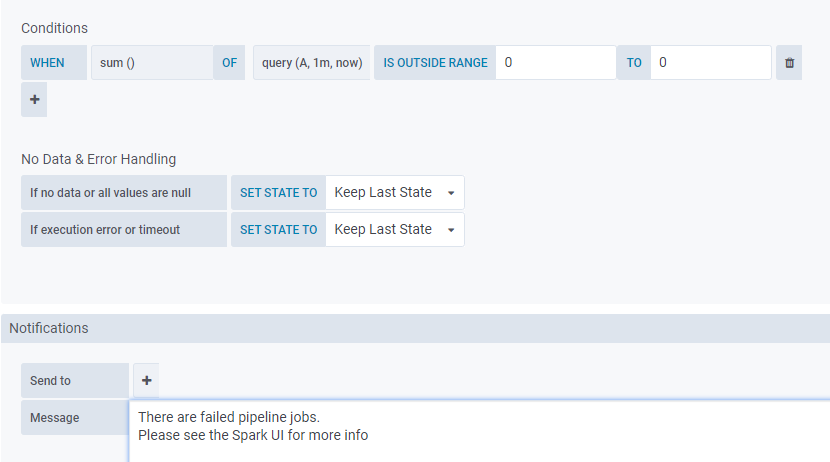
Panel Titleし、を選択して編集Editします。 Alertタブを選択して、アラートに値を追加します。Nameフィールドにルール名を指定します。 この例ではName、はですSpark application alert。- ルールをチェックインする頻度を
Evaluate every:1mおよびFor:1分で指定します。 Conditionsこの章でルールをチェックする条件を指定します。 この例ではcondition、はですWHEN sum() OF query(A, 1m,now) IS OUTSIDE RANGE 0 TO 0。 この条件はA、ボード上の各分の範囲のクエリーの結果の合計が 0 でない場合に警告を受け取ることを意味します。
条件の詳細については、『Grafana 開発者ガイド』を参照してください。Send toタブで以前に作成した通知チャネルを指定し、通知チャネルに送信するメッセージを追加します。 この例では、メッセージはですThere are failed pipeline jobs. Please see the Spark UI for more info。
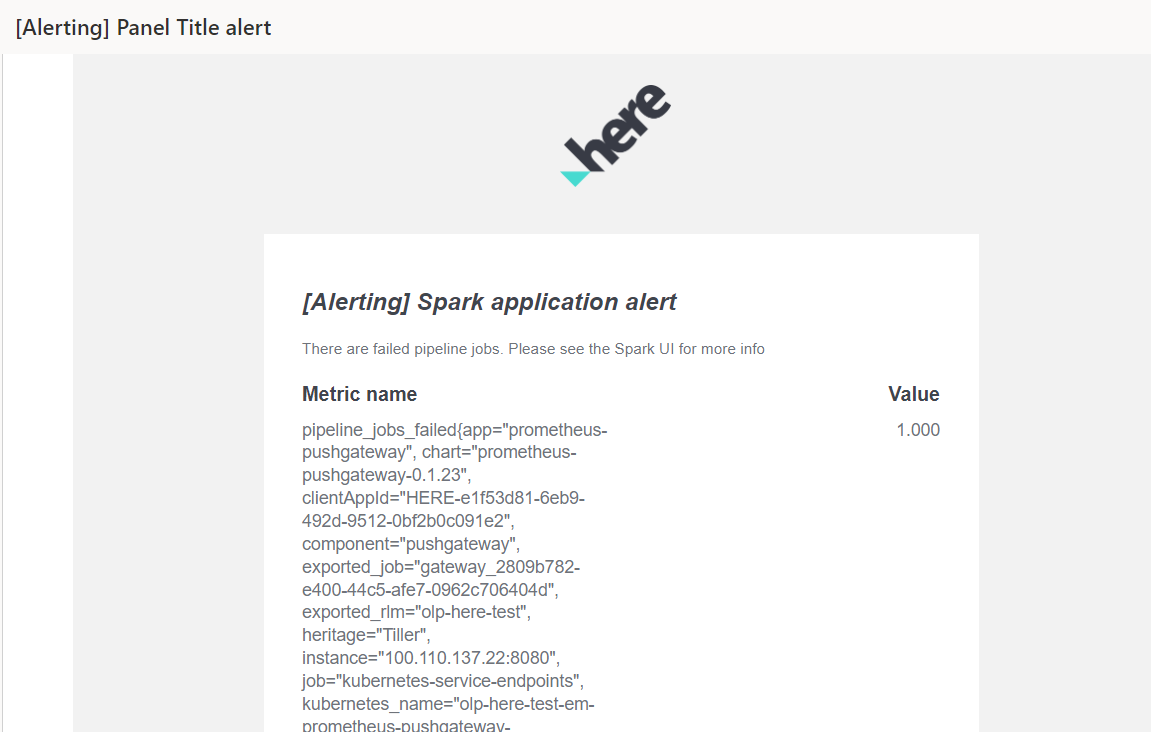
Grafana ホーム とアラートが設定されたら THROW_EXCEPTION 、パーティション をバージョン付レイヤー にもう一度アップロードしてパイプライン の実行を開始し、 Grafana アラートが動作し、電子メールでアラートが受信されたことを確認します。
パイプライン が失敗してから数分後に、アラートの設定時に指定したメッセージを含むアラートが電子メールで送信されます。
請求と使用状況
組織は、組織、プロジェクト、アプリ の使用量を取得し、さまざまな次元で使用量の上限を設定することで、プラットフォーム の支出を管理できます。 プラットフォーム でソリューションのスタックを構築する場合は、選択したサービスの使用状況を監視して、支出をより適切に管理できます。 HERE platform には、コスト管理のニーズを支援するコスト管理ツールのセットが用意されています。
コストは、次の 2 つの方法で区別できます。
- Project HERE リソースネーム を使用する。特に、このチュートリアルで行うように、プロジェクトスコープでパイプライン を実行します。
- billingTag を使用すると、請求書の経費を結合するための文字列を作成できます。 たとえば、特定のコストを強調表示するプロジェクトまたはアクティビティの複数のパイプラインをグループ化できます。 請求タグを使用して使用状況および請求についての情報を取得できるようにする
--billing-tagには、パラメータを使用してパイプライン バージョンを作成する必要があります。
請求および使用状況を確認するには、次の手順に従います。
- プラットフォームの [請求と使用状況] タブを開きます。
- 時間範囲を選択し て、 Download.Download csv をクリックします。
- パイプライン バージョンの作成時にプロジェクトの HERE リソースネーム または請求タグを指定した場合は、そのタグを使用して請求および使用状況を検索します。
注
請求および使用状況のデータは、パイプライン でアプリケーションを実行してから 48 時間が経過すると表示されます。
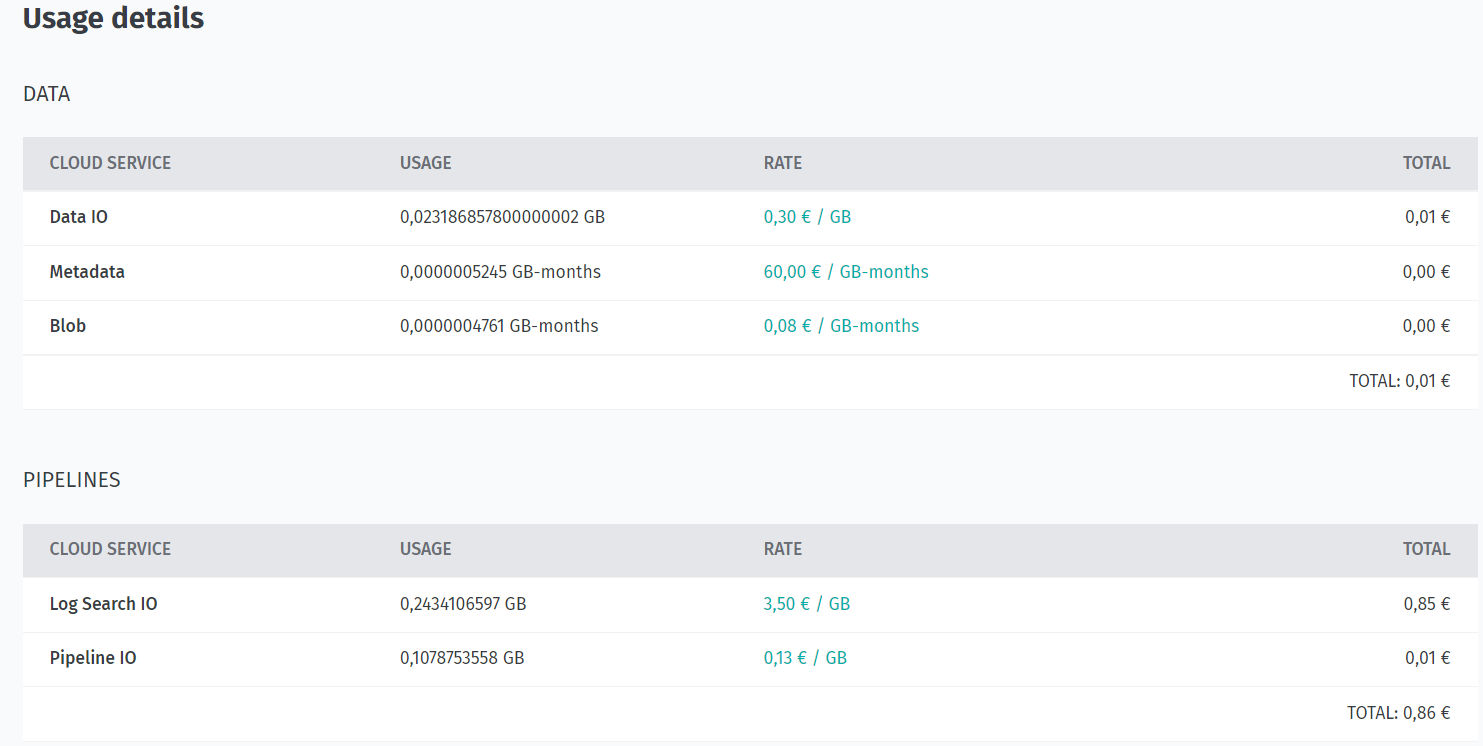
プログラム中に使用されたサービス、使用されたデータ量、および請求されたアイテムに関する情報が、 csv ファイルからテーブルに抽出されます。
| カテゴリ | サービス名またはリソース名 | 請求タグ | プロジェクト ID | 開始日 | 終了日 | 使用量 | 単位 | 1 台あたりのレート ( ユーロ / ドル ) | 合計価格 |
|---|---|---|---|---|---|---|---|---|---|
| データ | メタデータ | プロジェクト時間 | 2022-03-15 | 2022-03-30 | 0.0000000053 | MB/ 秒 - 月 | 60 | - | |
| データ | blob | プロジェクト時間 | 2022-03-15 | 2022-03-30 | 0.0000000106 | GB/s - か月 | 0.08 | 0 | |
| データ | データ IO | プロジェクト時間 | 2022-03-15 | 2022-03-30 | 0.0133039551 | GB | 0.3 | 0 | |
| パイプライン | ログ検索 IO | 開発 - 火花 | プロジェクト時間 | 2022-03-15 | 2022-03-30 | 0.1604950334 | GB | 3.5 | 0.56 |
| パイプライン | パイプライン IO | 開発 - 火花 | プロジェクト時間 | 2022-03-15 | 2022-03-30 | 0.0811133124 | GB | 0.13 | 0.01 |
この表には、作成したプロジェクトの請求メトリクスが表示されます。 請求タグはパイプライン バージョンにのみ設定され、カタログには設定されていないため、パイプライン メトリクスにのみ関連付けられていることも確認できます。
Data カテゴリの課金メトリックは、プラットフォーム のバージョン付レイヤー を使用したカタログの使用状況、およびアプリケーションの実行中に使用された次のサービスとリソースに接続されます。
-
Metadata- レイヤーのタイトル、カバレッジ、タグ、説明など、メタデータ で使用される割り当て済みストレージ。 使用量は、 1 時間あたりの保存済みレコードの最大バイト数として測定され、インデックスおよびメタデータ の永続ストレージに保存されているデータの合計として計算されます。 -
Blob- メッセージのペイロードが 1 か月あたり 1 メガバイト (MB) を超えると、バージョン管理されたレイヤーによって生成される blob データの保存に使用される割り当て済みディスクストレージ。 -
Data IO- HERE platform 内のデータを社内外から保存してアクセスする際に発生する転送。 データの取り込み、データの公開、 HERE platform コンポーネント間でのデータの転送を行う場合にも、データ IO が発生します。
Pipelines カテゴリの課金メトリックは実行中のパイプラインに接続され、アプリケーションの実行中に次のサービスとリソースが使用されました。
-
Log Search IO- パイプライン によって生成されたログ情報がデバッグ目的で書き込まれ、インデックスが作成されたときに発生するデータ転送。 -
Pipeline IO- パイプライン がパブリックインターネットとの間でデータの読み取りまたは書き込みを行ったときに発生するデータ転送。
使用状況の詳細に関するレポートを取得するもう 1 つの方法は、[請求と使用状況] ページの View ドロップダウンにプロジェクト ID を指定することです。
その結果、プロジェクトの使用状況の詳細が表形式で集計されます。
HERE platform のコスト概念の概要については、「請求可能なサービス」を参照してください。
結論
このチュートリアルでは、 Spark プログラムの開発段階、 Spark アプリケーションのデバッグ方法、 Splunk 、 Grafana 、 Spark UI などの監視ツールについて学習し、プラットフォーム の請求情報を取得する方法を学習しました。
詳細情報
このチュートリアルで扱うトピックの詳細については、次のソースを参照してください。
- Spark アプリケーションの開発方法の詳細については、Apache Spark のドキュメントを参照してください。
- パイプラインでアプリケーションを実行する方法の詳細については、『Pipelines 開発者ガイド』を参照してください。
- OLP CLI を使用してパイプライン でアプリケーションを実行する方法の詳細については、『OLP CLI Guide』を参照してください。
- Splunk の使用方法については 、 Splunk エンタープライズユーザーマニュアルを参照してください。
- コストの概念については 、「課金可能サービス」を参照してください。