- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
Path matching the sensor data to GeoJSON in Spark
Objectives: Use the Location Libraries to path match sensor data in standalone Spark.
Complexity: Intermediate
Time to complete: 45 min
Prerequisites: Organize your work in projects
Source code: Download
This example demonstrates how to do the following:
- Extract the recorded paths stored in the index layer of the SDII Sensor Data Sample Catalog,
- Map match each one of them using the Map Matching algorithms of the Location Library
- Output the map matched paths (trips) into a GeoJSON layer
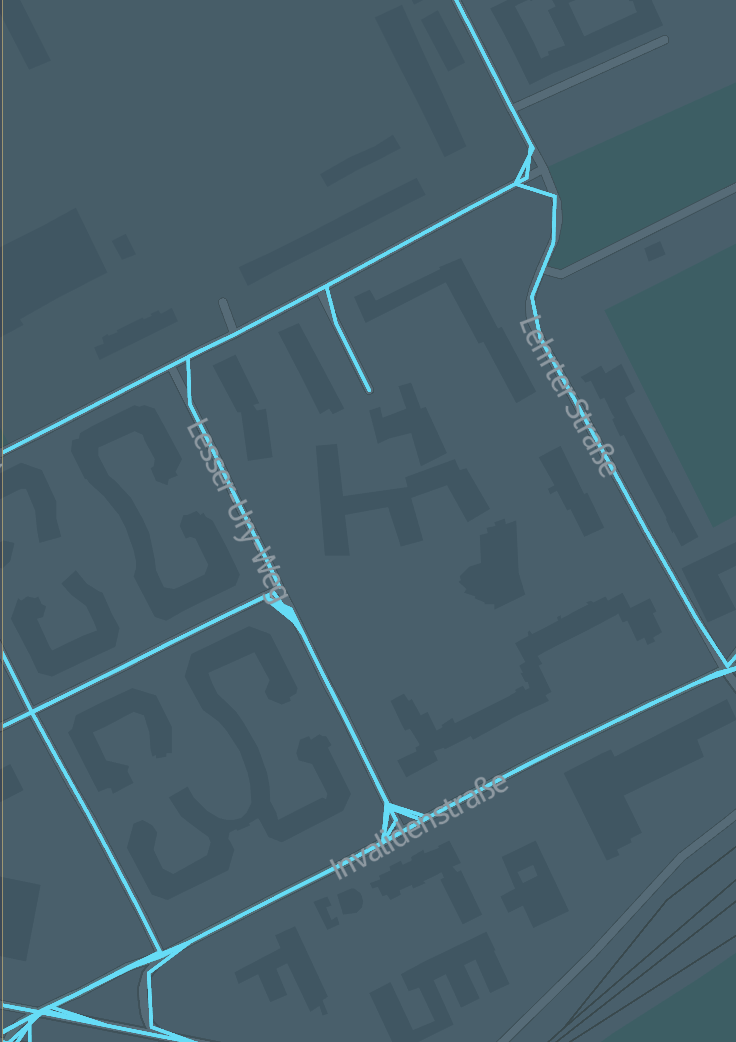
The input catalog contains path coordinates recorded from GPS devices:
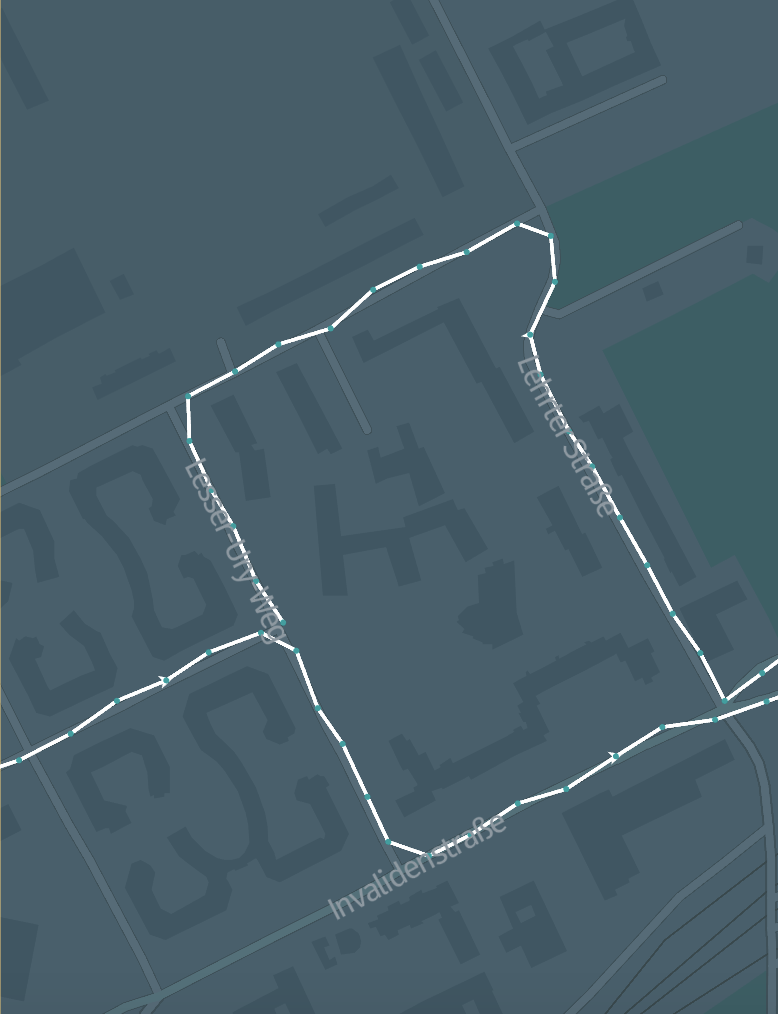
If map matching is possible, the output catalog contains the same trips that are matched to the HERE road network:
Set up the Maven project
Create the following folder structure for the project:
batch-path-matching
└── src
└── main
├── java
└── scala
You can do this with a single bash command:
mkdir -p batch-path-matching/src/main/{java,scala}
The Maven POM file is similar to that in the Verify Maven settings example, with the parent POM and dependencies sections updated:
Parent POM:
<parent>
<groupId>com.here.platform</groupId>
<artifactId>sdk-batch-bom_2.12</artifactId>
<version>2.54.3</version>
<relativePath/>
</parent>
Dependencies:
<dependencies>
<dependency>
<groupId>com.here.platform.pipeline</groupId>
<artifactId>pipeline-interface_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.platform.location</groupId>
<artifactId>location-integration-optimized-map-dcl2_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.platform.data.client</groupId>
<artifactId>spark-support_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.hrn</groupId>
<artifactId>hrn_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</dependency>
</dependencies>
Change your credentials to include the token scope
Append the here token scope to your credentials.properties file, so that all subsequent commands will be executed inside the project you have just created:
olp credentials update default --scope {{YOUR_PROJECT_HRN}}
Please remember to remove the line containing the here.token.scope from your credentials.properties file when you complete the tutorial, you can do this using the olp cli:
olp credentials update default --scope empty
Create the output catalog
Create an output catalog to contain the matched trips using this config file, replacing {{YOUR_CATALOG_ID}} and {{YOUR_USERNAME}} with your own.
{
"id": "{{YOUR_CATALOG_ID}}",
"name": "{{YOUR_USERNAME}} Path Matching Tutorial",
"summary": "Beijing sample matched path in GeoJSON",
"description": "Beijing sample matched path in GeoJSON",
"layers": [
{
"id": "matched-trips",
"name": "GeoJSON matched trips",
"summary": "GeoJSON matched trips",
"description": "GeoJSON matched trips",
"contentType": "application/vnd.geo+json",
"layerType": "versioned",
"volume": {
"volumeType": "durable"
},
"partitioning": {
"scheme": "heretile",
"tileLevels": [14]
},
"coverage": {
"adminAreas": [
"CN"
]
}
}
]
}
Create a catalog into the project with a GeoJSON layer at level 14 (the same as in the input catalog):
olp catalog create {{YOUR_CATALOG_ID}} "{{YOUR_USERNAME}} Matched Paths" \
--config output-catalog-cn.json
The CLI returns as follows:
Catalog {{YOUR_CATALOG_HRN}} has been created.
Note
If a billing tag is required in your realm, update the config file by adding the billingTags: ["YOUR_BILLING_TAG"] property to the layer section.
Implement the path matching application
The main() body contains direct invocations of the Location Libraries for the path matching logic. The helper methods implement the marshalling of input and output data via the Data Client Library.
Scala
Java
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import com.here.hrn.HRN
import com.here.platform.data.client.base.scaladsl.BaseClient
import com.here.platform.data.client.engine.scaladsl.DataEngine
import com.here.platform.data.client.model.VersionDependency
import com.here.platform.data.client.scaladsl.{DataClient, NewPartition}
import com.here.platform.data.client.spark.DataClientSparkContextUtils
import com.here.platform.data.client.spark.LayerDataFrameReader._
import com.here.platform.data.client.spark.SparkSupport._
import com.here.platform.location.core.geospatial.GeoCoordinate
import com.here.platform.location.core.mapmatching.OnRoad
import com.here.platform.location.integration.optimizedmap.OptimizedMapLayers
import com.here.platform.location.integration.optimizedmap.dcl2.OptimizedMapCatalog
import com.here.platform.location.integration.optimizedmap.mapmatching.PathMatchers
import com.here.platform.pipeline.PipelineContext
import org.apache.spark.sql.expressions.UserDefinedFunction
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{Dataset, Row, SparkSession}
// Since it is not convenient to recreate an instance of BaseClient, it's connection pool
// and OptimizedMapCatalog caches, they are stored in a singleton and called from it.
object OptimizedMapLayersSingleton {
lazy val optimizedMapLayers: OptimizedMapLayers = {
val pipelineContext = new PipelineContext
val optimizedMapCatalogHrn = pipelineContext.config.inputCatalogs("location")
val optimizedMapCatalogVersion = pipelineContext.job.get.inputCatalogs("location").version
OptimizedMapCatalog
.from(optimizedMapCatalogHrn)
.usingBaseClient(BaseClient())
.newInstance
.version(optimizedMapCatalogVersion)
}
}
/**
* Read sensor data from an SDII archive and output the map-matched paths
* to a GeoJSON output catalog with the same tiling scheme.
*/
object BatchPathMatchingScala {
private val pipelineContext = new PipelineContext
private val outputCatalogHrn = pipelineContext.config.outputCatalog
private val outputLayer = "matched-trips"
private val sensorDataArchiveHrn = pipelineContext.config.inputCatalogs("sensor")
private val sensorDataArchiveVersionLayerName = "sample-index-layer"
private val locationCatalogHrn = pipelineContext.config.inputCatalogs("location")
private val locationCatalogVersion = pipelineContext.job.get.inputCatalogs("location").version
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession.builder().appName("BatchPathMatchingPipeline").getOrCreate()
val sensorData = getSensorData(sparkSession)
val matchedPaths = matchPaths(sparkSession, sensorData)
publish(matchedPaths)
sparkSession.stop()
}
/**
* Retrieves the contents of the sensor data archive partitions.
*/
private def getSensorData(sparkSession: SparkSession): Dataset[SensorData] = {
import sparkSession.implicits._
// Extracting input data.
// There are two different options for the query parameter: `hour_from` and `tile_id`.
// You can either make it `hour_from>0` to get all available messages or make it
// `tile_id==$tile_id` to get messages by the specific partition.
// Possible tile_ids = [377893756, 377894443, 377894442, ...].
// For CN environment = [389695267, 389696772, 389695401, ...].
// You can implement more complex queries with RSQL
// (https://here-tech.skawa.fun/documentation/data-client-library/dev_guide/client/rsql.html)
val sdiiMessages = sparkSession
.readLayer(sensorDataArchiveHrn, sensorDataArchiveVersionLayerName)
.query(s"hour_from>0")
.load()
val sensorData = sdiiMessages
.select($"idx_tile_id" as "tileId", $"path.positionEstimate" as "fullPositionEstimate")
.withColumn("positionEstimate", convertToGeoCoordinate($"fullPositionEstimate"))
.groupBy("tileId")
.agg(collect_list("positionEstimate") as "positionEstimateList")
.as[SensorData]
sensorData
}
/**
* Map match each path inside each sensor archive tile
* (https://en.wikipedia.org/wiki/Map_matching)
* and return a list of lists of coordinates.
* Each element in the top-level list represents a path as a list of coordinates.
* Convert each path to GeoJson.
*/
private def matchPaths(sparkSession: SparkSession,
sensorData: Dataset[SensorData]): Dataset[(Long, String)] = {
import sparkSession.implicits._
/**
* Convert the trips to GeoJson; each trip is converted to a linestring.
*/
def convertToGeoJSON(
matchedTrips: Dataset[(Long, Seq[Seq[GeoCoordinate]])]): Dataset[(Long, String)] =
matchedTrips.map { matchedTrip =>
val features = matchedTrip._2
.map(
coordinates =>
"""{ "type": "Feature", "geometry": """ +
"""{ "type": "LineString", "coordinates": """ +
coordinates.map(c => s"[${c.longitude}, ${c.latitude}]").mkString("[", ",", "]")
+ "}" + """, "properties": {} }""")
val featureCollection =
features.mkString("""{ "type": "FeatureCollection", "features": [""", ",", "]}")
(matchedTrip._1, featureCollection)
}
val matchedTrips = sensorData.mapPartitions { sensorDataIterator =>
val optimizedMap = OptimizedMapLayersSingleton.optimizedMapLayers
val pathMatcher =
PathMatchers(optimizedMap).carPathMatcherWithoutTransitions[GeoCoordinate]
sensorDataIterator.map { sensorDataElement =>
sensorDataElement.tileId ->
sensorDataElement.positionEstimateList
.map {
pathMatcher
.matchPath(_)
.results
.flatMap {
case OnRoad(matched) =>
Some(GeoCoordinate(matched.nearest.latitude, matched.nearest.longitude))
case _ => None
}
}
}
}
convertToGeoJSON(matchedTrips)
}
val convertToGeoCoordinate: UserDefinedFunction = udf((positionEstimateRows: Seq[Row]) => {
positionEstimateRows.map { positionEstimate =>
val lat = positionEstimate.getAs[Double]("latitude_deg")
val lon = positionEstimate.getAs[Double]("longitude_deg")
GeoCoordinate(lat, lon)
}
})
/**
* Publish the GeoJSON partitions to the output catalog using Data Client Library.
*/
private def publish(geoJsonByTile: Dataset[(Long, String)]): Unit = {
val masterActorSystem =
DataClientSparkContextUtils.context.actorSystem
// Start commit on master.
val masterPublishApi = DataClient(masterActorSystem).publishApi(outputCatalogHrn)
// Get the latest catalog version of the output catalog.
val baseVersion = masterPublishApi.getBaseVersion().awaitResult()
// Fill in the direct and indirect dependencies for the output catalog, given the direct inputs.
// This is good practice, especially if you intend to use the scheduler to
// determine when the pipeline should run, (i.e., by using the --with-scheduler option
// in
// For users using platform.here.com:
// https://here-tech.skawa.fun/documentation/open-location-platform-cli/user_guide/topics/pipeline/version-commands.html#pipeline-version-create
// For users using platform.hereolp.cn:
// https://here-tech.skawa.fun/cn/documentation/open-location-platform-cli/user_guide/topics/pipeline/version-commands.html#pipeline-version-create
val dependencies =
gatherDependencies(locationCatalogHrn, locationCatalogVersion)
// Start a publication batch on top of most recent catalog version.
val batchToken =
masterPublishApi.startBatch2(baseVersion, Some(Seq(outputLayer)), dependencies).awaitResult()
// Send partitions to workers, and upload data and metadata.
geoJsonByTile.foreachPartition({ partitions: Iterator[(Long, String)] =>
val workerActorSystem = DataClientSparkContextUtils.context.actorSystem
val workerPublishApi = DataClient(workerActorSystem).publishApi(outputCatalogHrn)
val workerWriteEngine = DataEngine(workerActorSystem).writeEngine(outputCatalogHrn)
val committedPartitions =
partitions.map {
case (tileId: Long, geoJson: String) =>
val newPartition =
NewPartition(
partition = tileId.toString,
layer = outputLayer,
data = NewPartition.ByteArrayData(geoJson.getBytes)
)
workerWriteEngine.put(newPartition).awaitResult()
}
workerPublishApi
.publishToBatch(batchToken, committedPartitions)
.awaitResult()
()
})
masterPublishApi.completeBatch(batchToken).awaitResult()
}
/**
* Gather the dependencies for the output catalog which depends on the location library catalog.
*/
private def gatherDependencies(locationHrn: HRN, locationVersion: Long) = {
val sparkActorSystem = DataClientSparkContextUtils.context.actorSystem
val locationLibraryQuery = DataClient(sparkActorSystem).queryApi(locationHrn)
val locationLibraryDeps =
locationLibraryQuery.getVersion(locationVersion).awaitResult().dependencies
// The output catalog depends directly on the location library
// catalog, and indirectly on its respective dependencies.
locationLibraryDeps.map(_.copy(direct = false)) ++
Seq(VersionDependency(locationHrn, locationVersion, direct = true))
}
/**
* Class used for encoding data in Dataset.
*/
case class SensorData(tileId: Long, positionEstimateList: Seq[Seq[GeoCoordinate]])
}
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import static org.apache.spark.sql.functions.col;
import static org.apache.spark.sql.functions.collect_list;
import static org.apache.spark.sql.functions.udf;
import akka.actor.ActorSystem;
import akka.japi.Pair;
import com.here.hrn.HRN;
import com.here.platform.data.client.base.javadsl.BaseClient;
import com.here.platform.data.client.base.javadsl.BaseClientJava;
import com.here.platform.data.client.engine.javadsl.DataEngine;
import com.here.platform.data.client.engine.javadsl.WriteEngine;
import com.here.platform.data.client.javadsl.CommitPartition;
import com.here.platform.data.client.javadsl.DataClient;
import com.here.platform.data.client.javadsl.NewPartition;
import com.here.platform.data.client.javadsl.PublishApi;
import com.here.platform.data.client.javadsl.QueryApi;
import com.here.platform.data.client.model.BatchToken;
import com.here.platform.data.client.model.VersionDependency;
import com.here.platform.data.client.spark.DataClientSparkContextUtils;
import com.here.platform.data.client.spark.javadsl.JavaLayerDataFrameReader;
import com.here.platform.location.core.geospatial.GeoCoordinate;
import com.here.platform.location.core.mapmatching.MatchResult;
import com.here.platform.location.core.mapmatching.NoTransition;
import com.here.platform.location.core.mapmatching.OnRoad;
import com.here.platform.location.core.mapmatching.javadsl.MatchResults;
import com.here.platform.location.core.mapmatching.javadsl.PathMatcher;
import com.here.platform.location.inmemory.graph.Vertex;
import com.here.platform.location.integration.optimizedmap.OptimizedMapLayers;
import com.here.platform.location.integration.optimizedmap.dcl2.javadsl.OptimizedMapCatalog;
import com.here.platform.location.integration.optimizedmap.mapmatching.javadsl.PathMatchers;
import com.here.platform.pipeline.PipelineContext;
import java.io.Serializable;
import java.util.*;
import java.util.concurrent.ExecutionException;
import java.util.stream.Collectors;
import java.util.stream.StreamSupport;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoder;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.api.java.UDF1;
import org.apache.spark.sql.expressions.UserDefinedFunction;
import org.apache.spark.sql.types.ArrayType;
import org.apache.spark.sql.types.DataTypes;
import scala.collection.JavaConverters;
import scala.collection.mutable.WrappedArray;
/**
* Read sensor data from an SDII archive and output the map-matched paths to a GeoJSON output
* catalog with the same tiling scheme.
*/
public class BatchPathMatchingJava {
private static final PipelineContext pipelineContext = new PipelineContext();
private static final HRN OUTPUT_CATALOG_HRN = pipelineContext.getConfig().getOutputCatalog();
private static final String OUTPUT_LAYER = "matched-trips";
private static final HRN SENSOR_DATA_ARCHIVE_HRN =
pipelineContext.getConfig().getInputCatalogs().get("sensor");
private static final String SENSOR_DATA_ARCHIVE_VERSION_LAYER_NAME = "sample-index-layer";
private static final HRN LOCATION_CATALOG_HRN =
pipelineContext.getConfig().getInputCatalogs().get("location");
private static final Long LOCATION_CATALOG_VERSION =
pipelineContext.getJob().get().getInputCatalogs().get("location").version();
// Since it is not convenient to recreate an instance of BaseClient, it's connection pool
// and OptimizedMapCatalog caches, they are stored in a singleton and called from it.
private enum OptimizedMapLayersSingleton {
INSTANCE;
private final OptimizedMapLayers optimizedMap;
OptimizedMapLayersSingleton() {
BaseClient baseClient = BaseClientJava.instance();
optimizedMap =
OptimizedMapCatalog.from(LOCATION_CATALOG_HRN)
.usingBaseClient(baseClient)
.newInstance()
.version(LOCATION_CATALOG_VERSION);
}
private OptimizedMapLayers optimizedMap() {
return optimizedMap;
}
}
public static void main(String[] args) throws InterruptedException, ExecutionException {
SparkSession sparkSession =
SparkSession.builder().appName("BatchPathMatchingPipeline").getOrCreate();
Dataset<SensorData> sensorData = getSensorData(sparkSession);
JavaRDD<Pair<Long, String>> matchedPaths = matchPaths(sensorData);
publish(matchedPaths);
sparkSession.stop();
}
/** Retrieves the contents of the sensor data archive partitions. */
private static Dataset<SensorData> getSensorData(SparkSession sparkSession) {
// Extracting input data.
// There are two different options for the query parameter: `hour_from` and `tile_id`.
// You can either make it `hour_from>0` to get all available messages or make it
// `tile_id==$tile_id` to get messages by the specific partition.
// Possible tile_ids = [377893756, 377894443, 377894442, ...].
// For CN environment = [389695267, 389696772, 389695401, ...].
// You can implement more complex queries with RSQL
// (https://here-tech.skawa.fun/documentation/data-client-library/dev_guide/client/rsql.html)
Dataset<Row> sdiiMessages =
JavaLayerDataFrameReader.create(sparkSession)
.readLayer(SENSOR_DATA_ARCHIVE_HRN, SENSOR_DATA_ARCHIVE_VERSION_LAYER_NAME)
.query("hour_from>0")
.load();
// Define structure of List of coordinate pairs - Spark uses it to encode data
ArrayType schema = DataTypes.createArrayType(DataTypes.StringType);
// UDF to extract only coordinates from the complex structure of path
UserDefinedFunction positionEstimateToCoordinatePair =
udf(
(UDF1<WrappedArray<Row>, List<String>>)
positionEstimateList ->
JavaConverters.seqAsJavaList(positionEstimateList)
.stream()
.map(
positionEstimate -> {
Double lat = positionEstimate.getAs("latitude_deg");
Double lon = positionEstimate.getAs("longitude_deg");
return lat + "," + lon;
})
.collect(Collectors.toList()),
schema);
Encoder<SensorData> sensorDataEncoder = Encoders.bean(SensorData.class);
// Extract list of paths (each path represented as a list of coordinates)
return sdiiMessages
.select(
col("idx_tile_id").as("tileId"),
col("path.positionEstimate").as("fullPositionEstimate"))
.withColumn(
"positionEstimate", positionEstimateToCoordinatePair.apply(col("fullPositionEstimate")))
.groupBy("tileId")
.agg(collect_list("positionEstimate").as("positionEstimateList"))
.as(sensorDataEncoder);
}
/**
* Map match each path inside each sensor archive tile
* (https://en.wikipedia.org/wiki/Map_matching) and return a list of lists of (lon,lat) string
* pairs. Each element in the top-level list represents a path as a list of coordinates. Convert
* each path to GeoJson.
*/
private static JavaRDD<Pair<Long, String>> matchPaths(Dataset<SensorData> sensorData) {
JavaRDD<Pair<Long, List<List<GeoCoordinate>>>> matchedTrips =
sensorData
.javaRDD()
.mapPartitions(
tiles -> {
OptimizedMapLayers optimizedMap =
OptimizedMapLayersSingleton.INSTANCE.optimizedMap();
PathMatcher<GeoCoordinate, Vertex, NoTransition> pathMatcher =
new PathMatchers(optimizedMap).carPathMatcherWithoutTransitions();
Iterable<SensorData> tileIterable = () -> tiles;
return StreamSupport.stream(tileIterable.spliterator(), false)
.map(
sensorDataElement ->
new Pair<>(
sensorDataElement.getTileId(),
getCoordinatesMatchedToPath(
pathMatcher, sensorDataElement.getPositionEstimateList())))
.iterator();
});
return convertToGeoJSON(matchedTrips);
}
/** Using path matcher get new list of lists of GeoCoordinates, each list representing a path. */
private static List<List<GeoCoordinate>> getCoordinatesMatchedToPath(
PathMatcher<GeoCoordinate, Vertex, NoTransition> pathMatcher,
List<List<String>> positionEstimatePathList) {
return positionEstimatePathList
.stream()
.map(BatchPathMatchingJava::convertToGeoCoordinates)
.map(
positionEstimatePath ->
pathMatcher
.matchPath(positionEstimatePath)
.results()
.stream()
.map(BatchPathMatchingJava::matchResultOnRoad)
.filter(Objects::nonNull)
.collect(Collectors.toList()))
.collect(Collectors.toList());
}
/** Convert list of string pairs, representing coordinates to actual GeoCoordinates */
private static List<GeoCoordinate> convertToGeoCoordinates(List<String> coordinatePairs) {
return coordinatePairs
.stream()
.map(
coordinatePair -> {
String[] coordinates = coordinatePair.split(",", 2);
double latitude = Double.parseDouble(coordinates[0]);
double longitude = Double.parseDouble(coordinates[1]);
return new GeoCoordinate(latitude, longitude);
})
.collect(Collectors.toList());
}
/** Construct new GeoCoordinates for on-road matches. */
private static GeoCoordinate matchResultOnRoad(MatchResult<Vertex> matchResult) {
if (MatchResults.isOnRoad(matchResult)) {
OnRoad<Vertex> onRoad = (OnRoad<Vertex>) matchResult;
GeoCoordinate nearest = onRoad.elementProjection().nearest();
return new GeoCoordinate(nearest.latitude(), nearest.longitude());
}
return null;
}
/** Convert the trips to GeoJson; each trip is converted to a linestring. */
private static JavaRDD<Pair<Long, String>> convertToGeoJSON(
JavaRDD<Pair<Long, List<List<GeoCoordinate>>>> matchedTrips) {
return matchedTrips.map(
matchedTrip -> {
String featureCollection =
matchedTrip
.second()
.stream()
.map(BatchPathMatchingJava::mapToFeature)
.collect(
Collectors.joining(
",", "{ \"type\": \"FeatureCollection\", \"features\": [", "]}"));
return new Pair<>(matchedTrip.first(), featureCollection);
});
}
/** Convert path to GeoJson Feature */
private static String mapToFeature(List<GeoCoordinate> coordinates) {
StringJoiner coordJoiner = new StringJoiner(",", "[", "]");
coordinates
.stream()
.map(c -> "[" + c.getLongitude() + ", " + c.getLatitude() + "]")
.forEach(coordJoiner::add);
return "{ \"type\": \"Feature\", \"geometry\": "
+ "{ \"type\": \"LineString\", \"coordinates\": "
+ coordJoiner
+ "}"
+ ", \"properties\": {} }";
}
/** Publish the GeoJSON partitions to the output catalog using Data Client Library. */
private static void publish(JavaRDD<Pair<Long, String>> geoJsonByTile)
throws InterruptedException, ExecutionException {
ActorSystem masterActorSystem = DataClientSparkContextUtils.context().actorSystem();
// Start commit on master.
PublishApi masterPublishApi = DataClient.get(masterActorSystem).publishApi(OUTPUT_CATALOG_HRN);
// Get the latest catalog version of the output catalog.
OptionalLong baseVersion = masterPublishApi.getBaseVersion().toCompletableFuture().get();
// Fill in the direct and indirect dependencies for the output catalog, given the direct inputs.
// This is good practice, especially if you intend to use the scheduler to
// determine when the pipeline should run, (i.e., by using the --with-scheduler option
// in
// For users using platform.here.com:
// https://here-tech.skawa.fun/documentation/open-location-platform-cli/user_guide/topics/pipeline/version-commands.html#pipeline-version-create
// For users using platform.hereolp.cn:
// https://here-tech.skawa.fun/cn/documentation/open-location-platform-cli/user_guide/topics/pipeline/version-commands.html#pipeline-version-create
List<VersionDependency> dependencies =
gatherDependencies(LOCATION_CATALOG_HRN, LOCATION_CATALOG_VERSION);
// Start a publication batch on top of most recent catalog version.
BatchToken batchToken =
masterPublishApi
.startBatch2(
baseVersion, Optional.of(Collections.singletonList(OUTPUT_LAYER)), dependencies)
.toCompletableFuture()
.get();
// Send partitions to workers, and upload data and metadata.
geoJsonByTile.foreachPartition(
partitions -> {
ActorSystem workerActorSystem = DataClientSparkContextUtils.context().actorSystem();
PublishApi workerPublishApi =
DataClient.get(workerActorSystem).publishApi(OUTPUT_CATALOG_HRN);
WriteEngine workerWriteEngine =
DataEngine.get(workerActorSystem).writeEngine(OUTPUT_CATALOG_HRN);
ArrayList<CommitPartition> commitPartitions = new ArrayList<>();
while (partitions.hasNext()) {
Pair<Long, String> content = partitions.next();
NewPartition newPartition =
new NewPartition.Builder()
.withPartition(content.first().toString())
.withLayer(OUTPUT_LAYER)
.withData(content.second().getBytes())
.build();
commitPartitions.add(workerWriteEngine.put(newPartition).toCompletableFuture().join());
}
workerPublishApi
.publishToBatch(batchToken, commitPartitions.iterator())
.toCompletableFuture()
.join();
});
// Complete the commit.
masterPublishApi.completeBatch(batchToken).toCompletableFuture().join();
}
/**
* Gather the dependencies for the output catalog which depends on the location library catalog.
*/
private static List<VersionDependency> gatherDependencies(HRN locationHrn, Long locationVersion) {
ActorSystem sparkActorSystem = DataClientSparkContextUtils.context().actorSystem();
QueryApi locationLibraryQuery = DataClient.get(sparkActorSystem).queryApi(locationHrn);
List<VersionDependency> locationDeps =
locationLibraryQuery
.getVersion(locationVersion)
.toCompletableFuture()
.join()
.getDependencies();
List<VersionDependency> retval =
locationDeps
.stream()
.map(dep -> new VersionDependency(dep.hrn(), dep.version(), false))
.collect(Collectors.toList());
retval.add(new VersionDependency(locationHrn, locationVersion, true));
return retval;
}
/**
* Class used for encoding data in Dataset. Contains tileId and list of lists of pairs, each list
* representing a path and each pair representing coordinate.
*/
public static class SensorData implements Serializable {
private Long tileId;
private List<List<String>> positionEstimateList;
public Long getTileId() {
return tileId;
}
public void setTileId(Long tileId) {
this.tileId = tileId;
}
public List<List<String>> getPositionEstimateList() {
return positionEstimateList;
}
public void setPositionEstimateList(List<List<String>> positionEstimateList) {
this.positionEstimateList = positionEstimateList;
}
}
}
Declare the catalog inputs to the path matching application
The pipeline configuration files which declare the catalog inputs to the path matching application are as follows.
Replace the value for {{YOUR_CATALOG_HRN}} in the output-catalog HRN.
pipeline-config.conf
pipeline.config {
output-catalog {hrn = "{{YOUR_CATALOG_HRN}}"}
input-catalogs {
location {hrn = "hrn:here-cn:data::olp-cn-here:here-optimized-map-for-location-library-china-2"}
sensor {hrn = "hrn:here-cn:data::olp-cn-here:sample-data"}
}
}
Use SDII Sensor Data Sample Catalog and HERE Optimized Map for Location Library Catalog as an input data catalogs, to link to the project. To do this, replace {{YOUR_PROJECT_HRN}} with the HRN of your project in the following commands and execute they:
olp project resource link {{YOUR_PROJECT_HRN}} hrn:here-cn:data::olp-cn-here:sample-data
olp project resource link {{YOUR_PROJECT_HRN}} hrn:here-cn:data::olp-cn-here:here-optimized-map-for-location-library-china-2
The CLI should return the following messages:
Project resource hrn:here-cn:data::olp-cn-here:sample-data has been linked.
Project resource hrn:here-cn:data::olp-cn-here:here-optimized-map-for-location-library-china-2 has been linked.
pipeline-job.conf
// NOTE: If you are running the application in a pipeline with the scheduler,
// i.e., using the --with-scheduler option when creating the pipeline version
// (https://here-tech.skawa.fun/documentation/open-location-platform-cli/user_guide/topics/pipeline/version-commands.html#pipeline-version-create)
// then this file is not needed, as the scheduler will pick up the latest versions
// of the input catalogs.
pipeline.job.catalog-versions {
output-catalog {base-version = -1}
input-catalogs {
location {
processing-type = "reprocess"
version = 4
}
sensor {
processing-type = "reprocess"
version = -1
}
}
}
For more information on pipeline configuration files, see the Pipeline API documentation.
Compile and run locally
To run the application locally, execute the following command:
Scala
Java
mvn compile exec:java \
-Dexec.mainClass=BatchPathMatchingScala \
-Dpipeline-config.file=pipeline-config.conf \
-Dpipeline-job.file=pipeline-job.conf \
-Dspark.master="local[*]" \
-Dcom.here.platform.data.client.endpoint-locator.discovery-service-env=here-cn
mvn compile exec:java \
-Dexec.mainClass=BatchPathMatchingJava \
-Dpipeline-config.file=pipeline-config.conf \
-Dpipeline-job.file=pipeline-job.conf \
-Dspark.master="local[*]" \
-Dcom.here.platform.data.client.endpoint-locator.discovery-service-env=here-cn
Further information
For additional details on the topics covered in this tutorial, you can refer to the following sources: Developer's Guide. The Code Examples page also lists more detailed code examples using the Location Library.
You can also build this simple path matching application as a fat JAR file:
mvn -Pplatform clean package
and deploy it via the Pipeline API. For more details on pipeline deployment, see the Pipelines Developer's Guide.