- Products ProductsLocation Services
Solve complex location problems from geofencing to custom routing
PlatformCloud environments for location-centric solution development, data exchange and visualization
Tracking & PositioningFast and accurate tracking and positioning of people and devices, indoors or outdoors
APIs & SDKsEasy to use, scaleable and flexible tools to get going quickly
Developer EcosystemsAccess Location Services on your favorite developer platform ecosystem
- Documentation DocumentationOverview OverviewServices ServicesApplications ApplicationsDevelopment Enablers Development EnablersContent ContentHERE Studio HERE StudioHERE Workspace HERE WorkspaceHERE Marketplace HERE MarketplacePlatform Foundation and Policy Documents Platform Foundation and Policy Documents
- Pricing
- Resources ResourcesTutorials TutorialsExamples ExamplesBlog & Release Announcements Blog & Release AnnouncementsChangelog ChangelogDeveloper Newsletter Developer NewsletterKnowledge Base Knowledge BaseFeature List Feature ListSupport Plans Support PlansSystem Status System StatusLocation Services Coverage Information Location Services Coverage InformationSample Map Data for Students Sample Map Data for Students
- Help
Local development and testing with CLI and Data Client Library
Objectives: Understand how to implement and test a processing application with local catalogs.
Complexity: Intermediate
Time to complete: 45 min
Prerequisites: Use Spark Connector to read and write data (for the logic of the sample processing application)
Source code: Download
This example demonstrates how to do the following:
- Use the CLI to create a local output catalog to run your processing pipeline during development
- Use the CLI to create a local copy of the input platform hosted catalog, to create a fully offline development environment
- Use the Data Client Library, local catalogs, and your favorite testing framework to test your processing pipeline.
About local catalogs
A local catalog is a special catalog encoded in a file and stored in the ~/.here/local/ directory. The CLI and Data Client Library can spawn a local version of the Data API that reads and writes to local catalogs. Every local catalog file has the filename <catalog-id>.db, and can be renamed (to change the catalog ID), copied, and moved to other machines, to share local catalogs within or across engineering teams. Catalogs can be added to the ~/.here/local/ directory and be immediately used with the CLI and the Data Client Library.
Local catalogs are identified by the special HRN hrn:local:data:::<catalog-id>.
No authentication and no access to the external network are needed to use local catalogs, hence you do not incur any additional cost for accessing local catalogs. Since they are contained in a local machine, they are not subject to naming conflicts within your realm.
Additionally, local catalogs can be optionally created and stored in memory, rather than persisted on disk, which makes them especially useful during development and automated testing.
Note
Local catalogs may only be used for development and testing purposes. Running production use cases with local catalogs is not permitted.
A sample processing application
Local catalogs can be used during the development of a wide range of applications, from standalone to Spark or Flink based applications, and with versioned, stream, index, and volatile layers.
In this tutorial you use Data Client Library's Spark Connector, but the steps to run and test this application with local catalog can be used in all other scenarios.
First, develop an application that for each topology partitions in HERE Map Content, counts the number of topology nodes in each level 14 sub-tile, encodes this information in level 12 GeoJSON tiles, and saves the result in a output versioned layer:
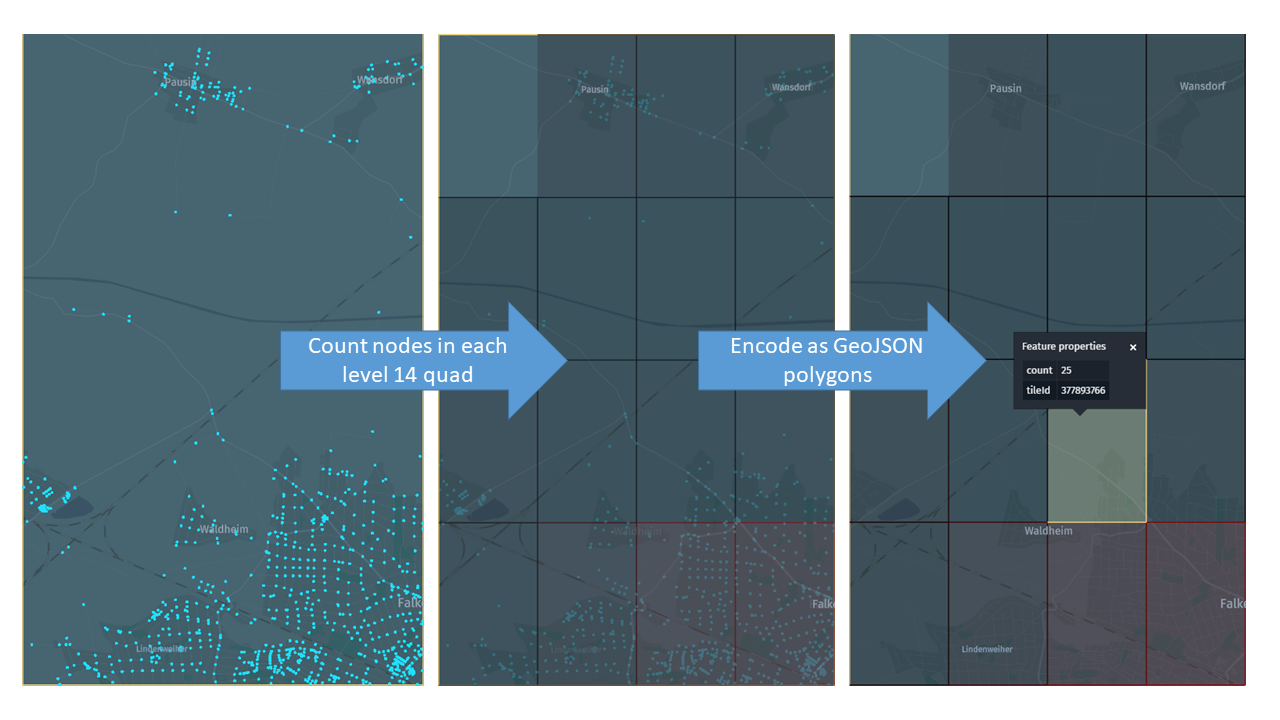
You use different shades of red based on the number of nodes, to create a "heatmap" representing the density of intersections in the sub-tile:

Set up the Maven project
Create the following folder structure for the project:
local-development-workflow
└── src
├── main
| ├── java
| ├── scala
| └── resources
└── test
├── java
├── scala
└── resources
You can do this with a single bash command:
mkdir -p local-development-workflow/src/{main,test}/{java,scala,resources}
The Maven POM file is similar to that in the Verify Maven Settings example, with the parent POM and dependencies sections updated:
Parent POM:
<parent>
<groupId>com.here.platform</groupId>
<artifactId>sdk-batch-bom_2.12</artifactId>
<version>2.54.3</version>
<relativePath/>
</parent>
Dependencies:
<dependencies>
<dependency>
<groupId>com.here.platform.pipeline</groupId>
<artifactId>pipeline-interface_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.platform.data.client</groupId>
<artifactId>spark-support_${scala.compat.version}</artifactId>
</dependency>
<!-- To enable support of local catalogs -->
<dependency>
<groupId>com.here.platform.data.client</groupId>
<artifactId>local-support_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.hrn</groupId>
<artifactId>hrn_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
</dependency>
<dependency>
<groupId>com.here.schema.rib</groupId>
<artifactId>topology-geometry_v2_scala_${scala.compat.version}</artifactId>
</dependency>
<dependency>
<groupId>com.here.schema.rib</groupId>
<artifactId>topology-geometry_v2_java</artifactId>
</dependency>
<dependency>
<groupId>com.thesamet.scalapb</groupId>
<artifactId>sparksql-scalapb_${scala.compat.version}</artifactId>
<version>0.10.4</version>
</dependency>
<!-- To test the Scala version of the application -->
<dependency>
<groupId>org.scalatest</groupId>
<artifactId>scalatest_${scala.compat.version}</artifactId>
<version>3.0.1</version>
<scope>test</scope>
</dependency>
<!-- To test the Java version of the application -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
Create a local output catalog
First you develop your pipeline, reading from HERE Map Content and writing to a local catalog. Further on, you create a local copy of the HERE Map Content catalog to produce a completely offline development environment.
Creating a local catalog with the CLI is very similar to creating a catalog on the platform. You are using the following catalog configuration:
{
"id": "node-count",
"name": "Aggregated node count at level 14 (From tutorial)",
"summary": "Here Map Content node count per level 14 tile.",
"description": "Here Map Content node count per level 14 tile.",
"tags": ["Tutorial"],
"layers": [
{
"id": "node-count",
"name": "node-count",
"summary": "Node count.",
"description": "Node count.",
"contentType": "application/vnd.geo+json",
"layerType": "versioned",
"volume": {
"volumeType": "durable"
},
"partitioning": {
"scheme": "heretile",
"tileLevels": [12]
}
}
]
}
The catalog contains a GeoJSON layer at level 12 (the same as in the input catalog). Create the catalog by running the following command:
olp local catalog create node-count "Node Count" \
--config local-development-workflow-output-catalog.json
Note
If a billing tag is required in your realm, update the config file by adding the billingTags: ["YOUR_BILLING_TAG"] property to the layer section.
The CLI returns as follows:
Catalog hrn:local:data:::node-count has been created.
This means you have now access to the local catalog hrn:local:data:::node-count, and you can play with the local variants of the CLI catalog commands:
olp local catalog list
olp local catalog show hrn:local:data:::node-count
olp local catalog layer show hrn:local:data:::node-count node-count
For more details on the available CLI commands for local catalogs, see the OLP CLI documentation.
The catalog data is stored in the ~/.here/local/node-count.db file, which you can verify with:
ls ~/.here/local/
You can now create a pipeline-config.conf file containing the input catalog (HERE Map Content) and your newly created local catalog is the output catalog:
pipeline.config {
// Make sure the local catalog has been created first:
// olp local catalog create node-count "Node Count" --config local-development-workflow-output-catalog.json
output-catalog { hrn = "hrn:local:data:::node-count" }
input-catalogs {
here-map-content { hrn = "hrn:here-cn:data::olp-cn-here:here-map-content-china-2" }
}
}
Implement the application
The sample application reads and processes all input partitions within a bounding box, specified in the application.conf configuration file:
tutorial {
boundingBox {
// Beijing
north = 41.0596
south = 39.4416
east = 117.508
west = 115.4172
}
}
To implement the logic, use the Data Client Library Spark connector and typical Spark transformations. Notice that you do not need to fully understand the processing logic to proceed with the tutorial. At the end of this exercise, test this code as a black box.
Scala
Java
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import com.here.olp.util.geo.BoundingBox
import com.here.olp.util.quad.factory.HereQuadFactory
import com.here.platform.data.client.spark.LayerDataFrameReader.SparkSessionExt
import com.here.platform.data.client.spark.LayerDataFrameWriter.DataFrameExt
import com.here.platform.data.client.spark.scaladsl.{
GroupedData,
VersionedDataConverter,
VersionedRowMetadata
}
import com.here.platform.pipeline.PipelineContext
import com.here.schema.rib.v2.topology_geometry_partition.TopologyGeometryPartition
import com.typesafe.config.ConfigBeanFactory
import org.apache.spark.sql.{Dataset, Row, SparkSession}
import scalapb.spark.Implicits._
object SparkConnectorLocalScala {
// We expose two public methods, `main` and `run`. `main` reads the pipeline context and the
// configuration from `pipeline-config.conf` and `application.conf`, while `run` accepts them
// as parameters. This makes it convenient to test the logic later using `run` with different
// configuration parameters, without having to pass them through the classpath.
def main(args: Array[String]): Unit = {
// Read the default pipeline context
val pipelineContext = new PipelineContext
// Read the bounding box configured in `application.conf`
val bbox = ConfigBeanFactory.create(
pipelineContext.applicationConfig.getConfig("tutorial.boundingBox"),
classOf[BoundingBox]
)
run(pipelineContext, bbox)
}
def run(pipelineContext: PipelineContext, bbox: BoundingBox): Unit = {
// Defines the input / output catalogs to be read / written to
val inputHrn = pipelineContext.config.inputCatalogs("here-map-content")
val outputHrn = pipelineContext.config.outputCatalog
// Input / output layers
val topologyGeometryLayer = "topology-geometry"
val outputLayer = "node-count"
val sparkSession: SparkSession =
SparkSession.builder().appName("SparkTopologyNodeCount").getOrCreate()
// Read the input data as a Dataset of topology partitions
val topologyGeometryData: Dataset[TopologyGeometryPartition] = sparkSession
.readLayer(inputHrn, topologyGeometryLayer)
.query(
s"mt_partition=inboundingbox=(${bbox.getNorth},${bbox.getSouth},${bbox.getEast},${bbox.getWest})"
)
.option("olp.connector.force-raw-data", value = true)
.load()
.select("data")
.as[Array[Byte]]
.map(TopologyGeometryPartition.parseFrom)
// This is needed for implicit conversions - moved down to avoid conflicts with scalapb.spark.Implicits._
import sparkSession.implicits._
// Compute the output partitions
val nodeCountPartitions: Dataset[NodeCountPartition] = topologyGeometryData.map { partition =>
val quads = partition.node
.flatMap(_.geometry)
.map(
g => HereQuadFactory.INSTANCE.getMapQuadByLocation(g.latitude, g.longitude, 14).getLongKey
)
.groupBy(identity)
.map {
case (tileId, seq) => NodeCount(tileId, seq.size)
}
NodeCountPartition(partition.partitionName, quads.toSeq)
}
// Encode the output partitions, convert to DataFrame and publish the output data
nodeCountPartitions
.map(p => (p.partitionName, p.toGeoJson.getBytes))
.toDF("mt_partition", "data")
.writeLayer(outputHrn, outputLayer)
.withDataConverter(new VersionedDataConverter {
def serializeGroup(rowMetadata: VersionedRowMetadata,
rows: Iterator[Row]): GroupedData[VersionedRowMetadata] =
GroupedData(rowMetadata, rows.next().getAs[Array[Byte]]("data"))
})
.save()
sparkSession.stop()
}
// Class representing the number of nodes in a level 14 sub-tile
case class NodeCount(tileId: Long, count: Int) {
def toGeoJson: String = {
val box = HereQuadFactory.INSTANCE.getMapQuadByLongKey(tileId).getBoundingBox
val e = box.getEast
val w = box.getWest
val n = box.getNorth
val s = box.getSouth
val color = {
// from black (0 nodes) to red (500 nodes)
s"rgb(${(count.min(500).toDouble / 500 * 255).toInt},0,0)"
}
"""{"type":"Feature",""" +
s""""geometry":{"type":"Polygon","coordinates":[[[$w,$s],[$e,$s],[$e,$n],[$w,$n],[$w,$s]]]},""" +
s""""properties":{"description":{"tileId":$tileId,"count":$count},"style":{"color":"$color"}}}"""
}
}
// Class representing the decoded content of an output partition
case class NodeCountPartition(partitionName: String, counts: Seq[NodeCount]) {
def toGeoJson: String =
s"""{"type":"FeatureCollection","features":[${counts.map(_.toGeoJson).mkString(",")}]}"""
}
}
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import com.here.hrn.HRN;
import com.here.olp.util.geo.BoundingBox;
import com.here.olp.util.quad.factory.HereQuadFactory;
import com.here.platform.data.client.spark.javadsl.JavaLayerDataFrameReader;
import com.here.platform.data.client.spark.javadsl.JavaLayerDataFrameWriter;
import com.here.platform.data.client.spark.javadsl.VersionedDataConverter;
import com.here.platform.data.client.spark.scaladsl.GroupedData;
import com.here.platform.data.client.spark.scaladsl.VersionedRowMetadata;
import com.here.platform.pipeline.PipelineContext;
import com.here.schema.rib.v2.TopologyGeometry.Node;
import com.here.schema.rib.v2.TopologyGeometryPartitionOuterClass;
import com.here.schema.rib.v2.TopologyGeometryPartitionOuterClass.TopologyGeometryPartition;
import com.typesafe.config.ConfigBeanFactory;
import java.io.Serializable;
import java.util.Iterator;
import java.util.List;
import java.util.stream.Collectors;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SparkConnectorLocal {
// Class representing the number of nodes in a level 14 sub-tile
public static class NodeCount {
private long tileId;
private int count;
public NodeCount(long tileId, int count) {
this.tileId = tileId;
this.count = count;
}
public String toGeoJson() {
BoundingBox box = HereQuadFactory.INSTANCE.getMapQuadByLongKey(tileId).getBoundingBox();
double e = box.getEast();
double w = box.getWest();
double n = box.getNorth();
double s = box.getSouth();
// from black (0 nodes) to red (500 nodes)
String color = String.format("rgb(%d,0,0)", (int) (Math.min(count, 500) / 500.0 * 255));
return String.format(
"{\"type\":\"Feature\","
+ "\"geometry\":{\"type\":\"Polygon\",\"coordinates\":[[[%f, %f], [%f, %f], [%f, %f], [%f, %f], [%f, %f]]]},"
+ "\"properties\":{\"description\":{\"tileId\":%d,\"count\":%d},\"style\":{\"color\":\"%s\"}}}",
w, s, e, s, e, n, w, n, w, s, tileId, count, color);
}
}
// Class representing the decoded content of an output partition
public static class NodeCountPartition {
private String partitionName;
private List<NodeCount> counts;
public NodeCountPartition(String partitionName, List<NodeCount> counts) {
this.partitionName = partitionName;
this.counts = counts;
}
public String toGeoJson() {
return String.format(
"{\"type\":\"FeatureCollection\",\"features\":[%s]}",
counts.stream().map(NodeCount::toGeoJson).collect(Collectors.joining(",")));
}
public String getPartitionName() {
return partitionName;
}
}
// Class representing an encoded output partition
public static class OutputData implements Serializable {
private String mt_partition;
private byte[] data;
public OutputData(String mt_partition, byte[] data) {
this.mt_partition = mt_partition;
this.data = data;
}
// Minimal bean interface - required to use Encoders.bean
public String getMt_partition() {
return mt_partition;
}
public void setMt_partition(String mt_partition) {
this.mt_partition = mt_partition;
}
public byte[] getData() {
return data;
}
public void setData(byte[] data) {
this.data = data;
}
}
// We expose two static methods, `main` and `run`. `main` reads the pipeline context and the
// configuration from `pipeline-config.conf` and `application.conf`, while `run` accepts them
// as parameters. This makes it convenient to test the logic later using `run` with different
// configuration parameters, without having to pass them through the classpath.
public static void main(String[] args) {
// Read the default pipeline context
PipelineContext pipelineContext = new PipelineContext();
// Read the bounding box configured in `application.conf`
BoundingBox boundingBox =
ConfigBeanFactory.create(
pipelineContext.applicationConfig().getConfig("tutorial.boundingBox"),
BoundingBox.class);
run(pipelineContext, boundingBox);
}
public static void run(PipelineContext pipelineContext, BoundingBox bbox) {
// Defines the input / output catalogs to be read / written to
HRN inputHrn = pipelineContext.getConfig().getInputCatalogs().get("here-map-content");
HRN outputHrn = pipelineContext.getConfig().getOutputCatalog();
// Input / output layers
String topologyGeometryLayer = "topology-geometry";
String outputLayer = "node-count";
SparkSession sparkSession =
SparkSession.builder().appName("SparkTopologyNodeCount").getOrCreate();
// Read the input data as a Dataset of topology partitions
Dataset<TopologyGeometryPartitionOuterClass.TopologyGeometryPartition> topologyGeometryData =
JavaLayerDataFrameReader.create(sparkSession)
.readLayer(inputHrn, topologyGeometryLayer)
.query(
String.format(
"mt_partition=inboundingbox=(%f,%f,%f,%f)",
bbox.getNorth(), bbox.getSouth(), bbox.getEast(), bbox.getWest()))
.option("olp.connector.force-raw-data", true)
.load()
.select("data")
.as(Encoders.BINARY())
.map(
(MapFunction<byte[], TopologyGeometryPartition>)
TopologyGeometryPartition::parseFrom,
Encoders.kryo(TopologyGeometryPartitionOuterClass.TopologyGeometryPartition.class));
// Compute the output partitions
Dataset<NodeCountPartition> nodeCountPartitions =
topologyGeometryData.map(
(MapFunction<TopologyGeometryPartition, NodeCountPartition>)
partition -> {
List<NodeCount> counts =
partition
.getNodeList()
.stream()
.map(Node::getGeometry)
.map(
g ->
HereQuadFactory.INSTANCE
.getMapQuadByLocation(g.getLatitude(), g.getLongitude(), 14)
.getLongKey())
.collect(Collectors.groupingBy(t -> t))
.entrySet()
.stream()
.map(e -> new NodeCount(e.getKey(), e.getValue().size()))
.collect(Collectors.toList());
return new NodeCountPartition(partition.getPartitionName(), counts);
},
Encoders.kryo(NodeCountPartition.class));
// Encode the output partitions, convert to DataFrame and publish the output data
JavaLayerDataFrameWriter.create(
nodeCountPartitions
.map(
(MapFunction<NodeCountPartition, OutputData>)
p -> new OutputData(p.getPartitionName(), p.toGeoJson().getBytes()),
Encoders.bean(OutputData.class))
.toDF())
.writeLayer(outputHrn, outputLayer)
.withDataConverter(
new VersionedDataConverter() {
@Override
public GroupedData<VersionedRowMetadata> serializeGroup(
VersionedRowMetadata rowMetadata, Iterator<Row> rows) {
return new GroupedData<>(rowMetadata, rows.next().getAs("data"));
}
})
.save();
sparkSession.stop();
}
}
Compile and run locally
To run the application locally, execute the following command:
Scala
Java
mvn compile exec:java \
-Dexec.mainClass=SparkConnectorLocalScala \
-Dpipeline-config.file=pipeline-config-cn.conf \
-Dconfig.file=application-cn.conf \
-Dspark.master="local[*]"
mvn compile exec:java \
-Dexec.mainClass=SparkConnectorLocal \
-Dpipeline-config.file=pipeline-config-cn.conf \
-Dconfig.file=application-cn.conf \
-Dspark.master="local[*]"
After one run, you can download with the CLI the GeoJSON partitions that have been published:
olp local catalog layer partition get hrn:local:data:::node-count node-count \
--all --output local-geojson-partitions
Create an offline development environment
So far, you have only used an input catalog hosted on the platform. To create a development environment which does not require access to the external network nor HERE credentials, you now create a local copy of the HERE Map Content catalog, by running the following command:
olp local catalog copy create hrn:here-cn:data::olp-cn-here:here-map-content-china-2 \
--id here-map-content \
--include topology-geometry \
--filter [heretile]=bounding-box:41.0596,39.4416,117.508,115.4172
This creates a local catalog hrn:local:data:::here-map-content. Copy the latest version of of the HERE Map Content catalog, and initialize and copy only the topology-geometry layer. Include only the partitions contained in the specified bounding box. Local catalog copies are special local catalogs that retain information about the source catalog, which allows the local copy to be updated by running:
olp local catalog copy update hrn:local:data:::here-map-content
You can now modify the pipeline configuration to use this local copy as input:
pipeline.config {
output-catalog {hrn = "hrn:local:data:::node-count"}
input-catalogs {
// Notice how we use a local catalog here - instead of the HERE Map Content catalog on the
// platform.
here-map-content {hrn = "hrn:local:data:::here-map-content"}
}
}
Optionally, you do not need to access any catalog on the platform, you can configure the Data Client Library to only use local catalogs, by setting here.platform.data-client.endpoint-locator.discovery-service-env=local. This prevents the library from trying to fetch an authentication token:
Scala
Java
mvn compile exec:java \
-Dexec.mainClass=SparkConnectorLocalScala \
-Dpipeline-config.file=pipeline-config-local.conf \
-Dconfig.file=application-cn.conf \
-Dspark.master="local[*]" \
-Dhere.platform.data-client.endpoint-locator.discovery-service-env=local
mvn compile exec:java \
-Dexec.mainClass=SparkConnectorLocal \
-Dpipeline-config.file=pipeline-config-local.conf \
-Dconfig.file=application-cn.conf \
-Dspark.master="local[*]" \
-Dhere.platform.data-client.endpoint-locator.discovery-service-env=local
Now you can develop and run your application with no internet connection, for example, while commuting to work.
Note
In this tutorial, you have used the query functionality of the Data Client Library to only process a small bounding box, therefore run times are fast regardless of whether you read from the real platform hosted catalog or from a local copy. For applications which process the entire input, it is recommended that you copy a clip of the input catalog first, to keep development cycles fast, and test your logic with the real data in a Pipeline after ensuring the logic works correctly with local data.
Test the sample application
Local catalogs make it convenient to test the overall business logic of a processing application. Unit testing single methods is an important but time consuming process, and testing the whole pipeline as a black box is just as important. However, this usually requires creating and accessing catalog resources on the platform, which might be too slow and costly for frequently run automated test suites. Each developer, or even each test run, needs to access a unique output catalog, which further complicates the setup. Local in-memory catalogs are ideal in this situation, as they are kept in memory and are private to a single process instance.
Note
The maximum size of in-memory catalogs is limited by the amount of memory available to the JVM. If you need to run performance or stress tests with large local catalogs, you may decide to use persisted catalogs (here.platform.data-local.memory-mode=false).
First create your test configuration, by creating the file src/test/resources/application.conf. Configure the Data Client Library to use the local environment by default, which is needed to create catalogs in that environment with the AdminApi, and enable in-memory local catalogs:
here.platform.data-client {
# force local environment for all catalog accesses
endpoint-locator.discovery-service-env = local
}
here.platform.data-local {
# use in-memory local catalogs
memory-mode = true
}
Run a single test to verify that the application correctly computes the number of nodes in each level 14 tile. To this end, you first create some pseudo-random input data starting from an expected output, encode it in topology partitions, run the pipeline, and verify that the generated data matches the expected output. This setup can be used to run multiple tests, and with different data, allowing to cover all edge-cases:
Scala
Java
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import com.here.hrn.HRN
import com.here.olp.util.geo.BoundingBox
import com.here.olp.util.quad.factory.HereQuadFactory
import com.here.platform.data.client.engine.scaladsl.DataEngine
import com.here.platform.data.client.model._
import com.here.platform.data.client.scaladsl.{DataClient, NewPartition}
import com.here.platform.data.client.spark.DataClientSparkContextUtils.context._
import com.here.platform.data.client.spark.SparkSupport._
import com.here.platform.pipeline.{PipelineConfig, PipelineContext}
import com.here.schema.geometry.v2.geometry.Point
import com.here.schema.rib.v2.topology_geometry.Node
import com.here.schema.rib.v2.topology_geometry_partition.TopologyGeometryPartition
import org.junit.runner.RunWith
import org.scalatest.junit.JUnitRunner
import org.scalatest.{FlatSpec, Inspectors, Matchers}
import java.util.UUID
import scala.collection.JavaConverters._
import scala.util.Random
@RunWith(classOf[JUnitRunner])
class SparkConnectorLocalScalaTest extends FlatSpec with Matchers with Inspectors {
// Specify the bounding box used by our pipeline under test.
private val testBoundingBox = new BoundingBox(52.67551, 52.33826, 13.76116, 13.08835)
// Utilities to create a random topology node within a bounding box.
private val random = new Random(42)
private def randomInRange(min: Double, max: Double): Double =
min + (max - min) * random.nextDouble()
private def randomNode(boundingBox: BoundingBox): Node =
Node(
geometry = Some(
Point(
latitude = randomInRange(boundingBox.getSouth, boundingBox.getNorth),
longitude = randomInRange(boundingBox.getWest, boundingBox.getEast)
)
)
)
// Utility to create a catalog with a single HERE Tile versioned layer. The catalog will be local
// because we use `here.platform.data-client.endpoint-locator.discovery-service-env=local` in
// src/test/resources/application.conf. It will be kept in memory only, because we also use
// `here.platform.data-local.memory-mode=true`.
private def createCatalog(catalogIdPrefix: String, layerId: String): HRN =
DataClient()
.adminApi()
.createCatalog(
WritableCatalogConfiguration(
catalogIdPrefix + "-" + UUID.randomUUID().toString,
catalogIdPrefix,
"summary",
"description",
Seq(
WritableLayer(
layerId,
layerId,
"summary",
"description",
LayerTypes.Versioned,
HereTilePartitioning(List(12)),
DurableVolume,
contentType = "application/octet-stream"
)
)
)
)
.awaitResult()
// Utility to publish some test data in a catalog.
private def writeData(hrn: HRN, layer: String, data: Map[String, Array[Byte]]): Unit = {
val partitions = data.map {
case (partitionId, data) =>
NewPartition(
partitionId,
layer,
NewPartition.ByteArrayData(data)
)
}
DataEngine()
.writeEngine(hrn)
.publishBatch2(4, Some(Seq(layer)), Nil, partitions.iterator)
.awaitResult()
}
// Utility to read the data from the latest version of a catalog.
private def readData(hrn: HRN, layer: String): Map[String, Array[Byte]] = {
val readEngine = DataEngine().readEngine(hrn)
val queryApi = DataClient().queryApi(hrn)
queryApi
.getLatestVersion()
.flatMap {
case None => fail("Catalog is empty")
case Some(v) => queryApi.getPartitionsAsIterator(v, layer)
}
.awaitResult()
.map(p => p.partition -> readEngine.getDataAsBytes(p).awaitResult())
.toMap
}
// Utility to create an input test catalog given the expected outcome. `expectedCounts` is a map
// containing, for each level 14 tile ID, the number of nodes contained in that sub-tile.
// This method creates the requested number of topology nodes in each level-14 tile, encodes them
// in a topology partition and publishes them in a freshly created test catalog.
private def createTestInputCatalog(expectedCounts: Map[Long, Int]): HRN = {
val hrn = createCatalog("input", "topology-geometry")
val partitions: Map[String, Array[Byte]] = expectedCounts
.map {
case (tileId, count) =>
val boundingBox = HereQuadFactory.INSTANCE.getMapQuadByLongKey(tileId).getBoundingBox
val nodes = (1L to count).map(_ => randomNode(boundingBox))
tileId -> nodes
}
.groupBy {
case (tileId, _) =>
HereQuadFactory.INSTANCE.getMapQuadByLongKey(tileId).getAncestor(12).getLongKey
}
.map {
case (tileId, nodes) =>
tileId.toString -> TopologyGeometryPartition(
partitionName = tileId.toString,
node = nodes.values.reduce(_ ++ _)
).toByteArray
}
writeData(hrn, "topology-geometry", partitions)
hrn
}
// Utility to create an output catalog for the pipeline.
private def createTestOutputCatalog(): HRN = createCatalog("output", "node-count")
// Utility to retrieve the actual node count per level 14 tile in the output catalog. It reads the
// latest version of the catalog, retrieves the data, decodes it and returns the node count
// encoded in each level 14 tile. This is used, after a run of the pipeline under test, to verify
// that the node count is the expected on.
private def readActualNodeCount(hrn: HRN): Map[Long, Int] = {
// We use regular expressions to extract the tileId of the level 14 tiles and their node count.
// Using a proper JSON parser is left as an exercise.
val descriptionRegex =
""""description":\s*\{"tileId":\s*(\d+),\s*"count":\s*(\d+)}""".r.unanchored
readData(hrn, "node-count").flatMap {
case (_, data) =>
val geoJson = new String(data)
descriptionRegex.findAllMatchIn(geoJson).map(m => m.group(1).toLong -> m.group(2).toInt)
}
}
// Randomly generated expected result. For each level 14 tile in `testBoundingBox` we generate a
// random non-negative node count. We filter out zeros because those are by design not encoded by
// the pipeline under test.
private val expectedNodeCount: Map[Long, Int] = {
HereQuadFactory.INSTANCE
.iterableBoundingBoxToMapQuad(testBoundingBox, 14)
.asScala
.map { quad =>
quad.getLongKey -> (random.nextInt.abs % 100)
}
.filter(_._2 != 0)
.toMap
}
"SparkConnectorLocalScala" should "correctly compute the number of nodes in each sub-tile" in {
// Create the input catalog and publish the test data.
val inputHrn = createTestInputCatalog(expectedNodeCount)
// Create an empty output catalog.
val outputHrn = createTestOutputCatalog()
val pipelineContext =
PipelineContext(PipelineConfig(outputHrn, Map("here-map-content" -> inputHrn)))
// Run the pipeline under test.
SparkConnectorLocalScala.run(pipelineContext, testBoundingBox)
// Check the output data.
readActualNodeCount(outputHrn) should contain theSameElementsAs expectedNodeCount
}
}
/*
* Copyright (c) 2018-2023 HERE Europe B.V.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
import static junit.framework.TestCase.assertEquals;
import com.here.hrn.HRN;
import com.here.olp.util.geo.BoundingBox;
import com.here.olp.util.quad.factory.HereQuadFactory;
import com.here.platform.data.client.engine.javadsl.DataEngine;
import com.here.platform.data.client.engine.javadsl.ReadEngine;
import com.here.platform.data.client.javadsl.DataClient;
import com.here.platform.data.client.javadsl.NewPartition;
import com.here.platform.data.client.javadsl.Partition;
import com.here.platform.data.client.javadsl.QueryApi;
import com.here.platform.data.client.model.*;
import com.here.platform.data.client.spark.DataClientSparkContextUtils;
import com.here.platform.pipeline.PipelineConfig;
import com.here.platform.pipeline.PipelineContext;
import com.here.schema.geometry.v2.GeometryOuterClass;
import com.here.schema.rib.v2.TopologyGeometry;
import com.here.schema.rib.v2.TopologyGeometryPartitionOuterClass;
import java.util.*;
import java.util.concurrent.CompletionStage;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import java.util.stream.StreamSupport;
import org.junit.Test;
public class SparkConnectorLocalTest {
// Simple Pair class used to collect maps with Java streams.
static class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
}
// Specify the bounding box used by our pipeline under test.
private BoundingBox testBoundingBox = new BoundingBox(52.67551, 52.33826, 13.76116, 13.08835);
// Utilities to create a random topology node within a bounding box.
private Random random = new Random(42);
private double randomInRange(double min, double max) {
return min + (max - min) * random.nextDouble();
}
private TopologyGeometry.Node randomNode(BoundingBox boundingBox) {
return TopologyGeometry.Node.newBuilder()
.setGeometry(
GeometryOuterClass.Point.newBuilder()
.setLatitude(randomInRange(boundingBox.getSouth(), boundingBox.getNorth()))
.setLongitude(randomInRange(boundingBox.getWest(), boundingBox.getEast()))
.build())
.build();
}
// Utility to create a catalog with a single HERE Tile versioned layer. The catalog will be local
// because we use `here.platform.data-client.endpoint-locator.discovery-service-env=local` in
// src/test/resources/application.conf. It will be kept in memory only, because we also use
// `here.platform.data-local.memory-mode=true`.
private HRN createCatalog(String catalogIdPrefix, String layerId) {
return await(
DataClient.get(DataClientSparkContextUtils.context().actorSystem())
.adminApi()
.createCatalog(
new WritableCatalogConfiguration.Builder()
.withId(catalogIdPrefix + "-" + UUID.randomUUID().toString())
.withName("name")
.withSummary("summary")
.withDescription("description")
.withLayers(
Collections.singletonList(
new WritableLayer.Builder()
.withId(layerId)
.withName("name")
.withSummary("summary")
.withDescription("description")
.withLayerType(LayerTypes.Versioned())
.withPartitioning(
Partitioning.HereTile()
.withTileLevels(Collections.singletonList(12))
.build())
.withVolume(Volumes.Durable())
.withContentType("application/octet-stream")))
.build()));
}
// Utility to publish some test data in a catalog.
private void writeData(HRN hrn, String layer, Map<String, byte[]> data) {
Iterator<NewPartition> partitions =
data.entrySet()
.stream()
.map(
e ->
new NewPartition.Builder()
.withPartition(e.getKey())
.withLayer(layer)
.withData(e.getValue())
.build())
.collect(Collectors.toList())
.iterator();
await(
DataEngine.get(DataClientSparkContextUtils.context().actorSystem())
.writeEngine(hrn)
.publishBatch2(
4,
Optional.of(Collections.singletonList(layer)),
Collections.emptyList(),
partitions));
}
// Utility to read the data from the latest version of a catalog.
private Map<String, byte[]> readData(HRN hrn, String layer) {
ReadEngine readEngine =
DataEngine.get(DataClientSparkContextUtils.context().actorSystem()).readEngine(hrn);
QueryApi queryApi =
DataClient.get(DataClientSparkContextUtils.context().actorSystem()).queryApi(hrn);
Iterable<Partition> partitions =
() ->
await(
queryApi
.getLatestVersion(OptionalLong.empty())
.thenApply(
v -> v.orElseThrow(() -> new RuntimeException("Output catalog is empty")))
.thenCompose(
v -> queryApi.getPartitionsAsIterator(v, layer, Collections.emptySet())));
return StreamSupport.stream(partitions.spliterator(), false)
.map(p -> new Pair<>(p.getPartition(), await(readEngine.getDataAsBytes(p))))
.collect(Collectors.toMap(Pair::getKey, Pair::getValue));
}
// Utility to create an input test catalog given the expected outcome. `expectedCounts` is a map
// containing, for each level 14 tile ID, the number of nodes contained in that sub-tile.
// This method creates the requested number of topology nodes in each level-14 tile, encodes them
// in a topology partition and publishes them in a freshly created test catalog.
private HRN createInputCatalog(Map<Long, Integer> expectedNodeCount) {
HRN hrn = createCatalog("input", "topology-geometry");
Map<String, byte[]> partitions =
expectedNodeCount
.entrySet()
.stream()
.map(
e -> {
BoundingBox boundingBox =
HereQuadFactory.INSTANCE.getMapQuadByLongKey(e.getKey()).getBoundingBox();
List<TopologyGeometry.Node> nodes =
IntStream.rangeClosed(1, e.getValue())
.mapToObj(notused -> randomNode(boundingBox))
.collect(Collectors.toList());
return new Pair<>(e.getKey(), nodes);
})
.collect(
Collectors.groupingBy(
p ->
HereQuadFactory.INSTANCE
.getMapQuadByLongKey(p.getKey())
.getAncestor(12)
.getLongKey()))
.entrySet()
.stream()
.map(
e -> {
byte[] data =
TopologyGeometryPartitionOuterClass.TopologyGeometryPartition.newBuilder()
.setPartitionName(String.valueOf(e.getKey()))
.addAllNode(
e.getValue()
.stream()
.flatMap(p -> p.getValue().stream())
.collect(Collectors.toList()))
.build()
.toByteArray();
return new Pair<>(String.valueOf(e.getKey()), data);
})
.collect(Collectors.toMap(Pair::getKey, Pair::getValue));
writeData(hrn, "topology-geometry", partitions);
return hrn;
}
// Utility to create an output catalog for the pipeline.
private HRN createOutputCatalog() {
return createCatalog("output", "node-count");
}
private <T> T await(CompletionStage<T> stage) {
try {
return stage.toCompletableFuture().get();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
// Utility to retrieve the actual node count per level 14 tile in the output catalog. It reads the
// latest version of the catalog, retrieves the data, decodes it and returns the node count
// encoded in each level 14 tile. This is used, after a run of the pipeline under test, to verify
// that the node count is the expected on.
private Map<Long, Integer> readActualNodeCount(HRN hrn) {
// We use regular expressions to extract the tileId of the level 14 tiles and their node count.
// Using a proper JSON parser is left as an exercise.
Pattern descriptionRegex =
Pattern.compile("\"description\":\\s*\\{\"tileId\":\\s*(\\d+),\\s*\"count\":\\s*(\\d+)}");
return readData(hrn, "node-count")
.entrySet()
.stream()
.flatMap(
e -> {
String geoJson = new String(e.getValue());
Matcher matcher = descriptionRegex.matcher(geoJson);
List<Pair<Long, Integer>> matches = new ArrayList<>();
while (matcher.find()) {
matches.add(
new Pair<>(
Long.parseLong(matcher.group(1)), Integer.parseInt(matcher.group(2))));
}
return matches.stream();
})
.collect(Collectors.toMap(Pair::getKey, Pair::getValue));
}
private Map<Long, Integer> initializeExpectedNodeCount() {
return StreamSupport.stream(
HereQuadFactory.INSTANCE
.iterableBoundingBoxToMapQuad(testBoundingBox, 14)
.spliterator(),
false)
.map(quad -> new Pair<>(quad.getLongKey(), Math.abs(random.nextInt()) % 100))
.filter(pair -> pair.getValue() != 0)
.collect(Collectors.toMap(Pair::getKey, Pair::getValue));
}
// Randomly generated expected result. For each level 14 tile in `testBoundingBox` we generate a
// random non-negative node count. We filter out zeros because those are by design not encoded by
// the pipeline under test.
private Map<Long, Integer> expectedNodeCount = initializeExpectedNodeCount();
@Test
public void correctNodeCountTest() {
// Create the input catalog and publish the test data.
HRN inputHrn = createInputCatalog(expectedNodeCount);
// Create an empty output catalog.
HRN outputHrn = createOutputCatalog();
PipelineContext pipelineContext =
new PipelineContext(
new PipelineConfig(outputHrn, Collections.singletonMap("here-map-content", inputHrn)),
Optional.empty());
// Run the pipeline under test.
SparkConnectorLocal.run(pipelineContext, testBoundingBox);
// Check the output data.
assertEquals(readActualNodeCount(outputHrn), expectedNodeCount);
}
}
To run the test with Maven, execute this command:
mvn test -Dspark.master=local[*]
Deploy on the platform
Once you are satisfied with your application, you can build a fat JAR file as shown in the following:
mvn -Pplatform clean package
Deploy it via the Pipeline API, with no code modifications. For more details on pipeline deployment, see the Pipelines Developer's Guide.
Further information
For additional details on the topics covered in this tutorial, you can refer to the following sources:
- For information on the different layer types and configurations you can check the Data API documentation
- To know more about the interactive querying and manipulation of catalogs, you should check the OLP CLI documentation and the Data section
- For details on the Scala and Java APIs to access the platform, you can check the Data Client Library Developer Guide